
Views: 14
UN/CEFACT SBDH 第5章「PROCESSING FLOW OVERVIEW」解説と構造化CSV & 汎用データ交換器
2025-11-18
【デジタル取引のためのユニバーサル配送ラベル】UN/CEFACT SBDHが実現するデータ交換の未来
注:この動画は、GoogleのNotebookLMに参考文献を読ませて作成した解説動画です。
【20年前の仕様書から、未来のアーキテクチャへ】UN/CEFACT SBDHと構造化CSVが拓くデジタル取引の未来
注:この動画は、GoogleのNotebookLMに参考文献を読ませて作成した解説動画です。
1. はじめに

UN/CEFACT Standard Business Document Header Technical Specification Version 1.3 の第5章「PROCESSING FLOW OVERVIEW」は、SBDH がどのように業務アプリケーション、ミドルウェア、通信基盤の間を流れていくかを、図2とアプリケーション A〜G・データストア 1〜6 というモデルで説明している。
この章は規範的な要件ではなく、あくまで「典型的なデータフローのイメージ」を共有するための説明と位置付けられている。そのため、ここで示される構成をそのまま実装する必要はないが、SBDH をどのレイヤで生成・利用・変換するのかを整理するうえで有用なリファレンスになる。
本稿では、第5章の Processing Flow を日本語で整理したうえで、その拡張として
-
構造化CSV(xBRL-CSV)をコアモデルとする
-
Translator を「汎用データ交換器」として位置付ける
という拡張可能な汎用モデルを紹介する。
2. 図2の全体像
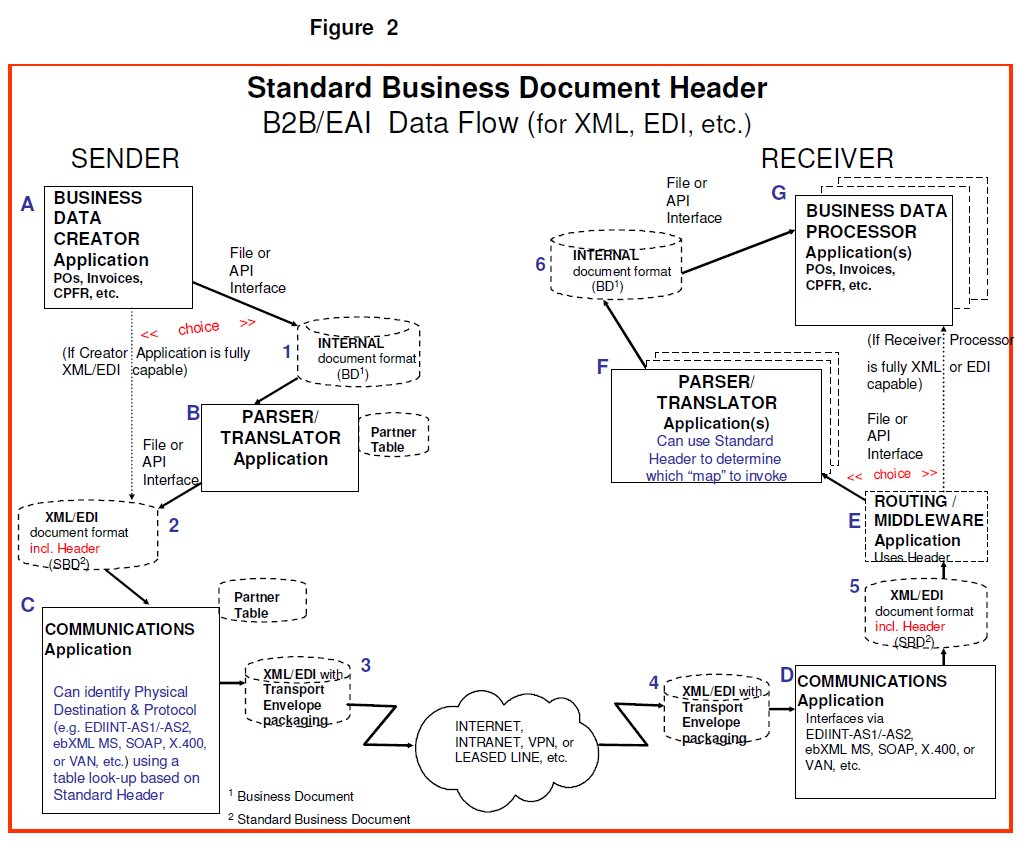
図2では、次のような流れが描かれている。
-
送信側の業務アプリケーションがビジネス文書(Business Document)を生成する。
-
必要に応じてパーサ/トランスレータで標準ビジネス文書(Standard Business Document, SBD)に変換し、その中に SBDH を組み込む。
-
通信アプリケーションが、SBDH に含まれる論理的な送信者・受信者・文書種別などを使って、実際の宛先と使用するトランスポートプロトコルを決定し、トランスポート用の封筒(プロトコル固有ヘッダ)を付与して送信する。
-
受信側の通信アプリケーションがトランスポート封筒をはがし、SBDH 付きの SBD を取り出す。
-
必要に応じてルーティング/ミドルウェアが SBDH を見て、どの変換ロジックやどのバックエンドアプリケーションに渡すかを決定する。
-
受信側パーサ/トランスレータが SBD を自社の内部フォーマットのビジネス文書に変換する。
-
最終的に受信側の業務アプリケーションが、そのビジネス文書を処理する。
この流れを、アプリケーション A〜G とデータストア 1〜6 で表現している。
3. アプリケーション A〜G とデータストア 1〜6
3.1. アプリケーション A(Business Data Creator)とデータストア 1・2
アプリケーション A は、いわゆる業務システムである。基幹システムや ERP、レガシーな販売管理システムなどが該当し、発注(PO)、請求(Invoice)、共同補充計画(CPFR)など、具体的なビジネスプロセスのトランザクションを作る役割を持つ。
ここで二つのパターンが示されている。
-
内部フォーマットのビジネス文書を生成するパターン
データストア 1 に格納されるのは、自社専用のフラットファイルや独自 XML などの内部形式で表現されたビジネス文書である。買掛明細や売掛明細をまとめたファイルなど、複数トランザクションを 1 ファイルに含めるようなケースも想定されている。 -
直接 SBD(標準ビジネス文書)を生成するパターン
もしアプリケーション A が「最初から標準 XML や EDI で出力できる」場合は、データストア 2 に示されるように、SBDH を含む標準ビジネス文書を直接生成し、後続のパーサ/トランスレータ(アプリケーション B)をバイパスできる。
データストア 2 は、このように外部向けの SBD(XML インスタンス、または EDI インターチェンジ)を保存する場所として定義されている。SBDH は、ここで初めて「論理的な送信者・受信者・文書種別・ビジネスプロセス識別」といった情報を持つビジネスヘッダとして登場する。
3.2. アプリケーション B(送信側パーサ/トランスレータ)
アプリケーション B は、内部ビジネス文書を SBD に変換するためのパーサ/トランスレータである。
-
内部の顧客コードを標準パートナーコードに変換する。
-
内部の商品コードを標準の商品識別コードに変換する。
-
独自フラットファイルなどの構造を標準フォーマット(XML や EDI)にマッピングする。
-
その際に SBDH を生成し、論理的な送信者・受信者・文書種別などを設定する。
仕様書では、すべての文書が必ずしも「プロプライエタリ → 標準」変換を必要とするわけではないことも明示されている。最初から標準フォーマットで生成するシステムであれば、この変換ステップは最小限または不要になる。
3.3. アプリケーション C(送信側コミュニケーション)とデータストア 3・4
アプリケーション C は、実際にネットワーク上でメッセージを送る通信アプリケーションである。ここでポイントになるのは、SBDH の論理情報を使って物理的な送信先とトランスポートプロトコルを決定する、という役割である。
-
SBDH に記録された論理的送信者・受信者 ID(例: GLN、DUNS など)をもとに、パートナーテーブルから実際の接続先や使用すべきプロトコル(AS2、ebMS、SOAP、X.400、VAN など)を引き当てる。
-
その結果として、SBD をトランスポート固有ヘッダと封筒(エンベロープ)で包んだ「トランスポートメッセージ」を生成し、ネットワークへ投入する。
データストア 3 は「送信時点のトランスポートメッセージ」、データストア 4 は「受信側で受け取られたトランスポートメッセージ」を表す。中身は同じだが、視点が送信側か受信側かという違いだけがある。
ここで重要なのは、SBDH がトランスポートプロトコルに依存しない論理ヘッダであり、具体的なプロトコルや物理アドレスへのマッピングは通信アプリケーション側の責務とされている点である。
3.4. アプリケーション D(受信側コミュニケーション)とデータストア 5
アプリケーション D は、受信側の通信アプリケーションである。
-
トランスポート層で受け取ったメッセージから、プロトコル固有の封筒を取り除き、SBDH 付きの SBD を取り出す。
-
SBDH の内容に基づき、この後どのような処理(どのルート、どのパーサ)に回すかを判断することもできる。
データストア 5 は、受信側で取り出された「SBDH を含む SBD」が保存される場所として定義されている。
3.5. アプリケーション E(ルーティング/ミドルウェア)
アプリケーション E はオプションのコンポーネントであり、ルーティングやミドルウェアの役割を担う。
-
SBDH を読み込んで、どのパーサ/トランスレータ(アプリケーション F)に渡すか、あるいはどのバックエンド業務アプリケーション(アプリケーション G)に直接渡すかを選択する。
-
SBDH に定義されている Business Scope、Service Information、Correlation Information などを利用し、ビジネス上のコンテキストに応じた処理分岐を行う。
これは、複数の業務システムや複数のフォーマットが並存している環境で、SBDH をキーにして「どのマッピング定義(変換マップ)を使うか」を決めるハブ的なコンポーネントとして理解できる。
3.6. アプリケーション F(受信側パーサ/トランスレータ)とデータストア 6
アプリケーション F は、SBD を自社内部のビジネス文書形式に変換するパーサ/トランスレータである。
-
SBDH に含まれる文書種別やサービス情報などを手掛かりに、「どのマッピング定義を適用するか」を選択する。
-
標準のパートナーコードや商品コードを自社内部コードに戻す。
-
外部標準の XML/EDI 構造から、内部のフラットファイルやテーブル構造に変換する。
データストア 6 は、この変換後の内部ビジネス文書を格納する領域であり、送信側のデータストア 1 と対になる位置付けになる。
3.7. アプリケーション G(Business Data Processor)
最後に、アプリケーション G は受信側の業務アプリケーションである。基幹システムや ERP、販売管理システムなどが該当し、データストア 6 のビジネス文書を読み込んで実際の業務処理(売上計上、在庫更新、請求計上など)を行う。
ここまでで、アプリケーション A から G、データストア 1 から 6 までの流れを通して見ると、SBDH は次の二つのポイントで特に重要な役割を果たしていることがわかる。
-
送信側で、内部データを標準化し、論理的な送受信者・文書種別・ビジネススコープを明示する。
-
受信側で、その論理情報を使ってルーティング・マッピング・業務アプリケーションへの振り分けを行う。
4. トランスポート層とビジネス層ヘッダの分離
第3章の Layered Processing Model や Routing、Packaging の説明と合わせて読むと、第5章の Processing Flow Overview は次のような設計原則を前提としている。
-
トランスポート層ヘッダ(AS2 ヘッダ、ebMS ヘッダなど)は、ネットワークレベルのルーティングやセキュリティ、再送制御など、技術的なメッセージ転送に関わる情報を扱う。
-
SBDH は、ビジネス文書の論理的な送受信者、文書種別、ビジネススコープなど、ビジネスアプリケーションやミドルウェアが必要とする情報を扱う。
-
この二つを明確にレイヤ分離することで、トランスポートプロトコルに依存しない標準的なビジネスヘッダとして SBDH を再利用できる。
Processing Flow Overview は、このレイヤ分離の考え方を「具体的なデータフロー」の形で示したものと解釈できる。
5. 構造化CSVと汎用データ交換器による拡張モデル
ここからは、第5章のモデルを土台にしつつ、拡張性の部分を
-
コアモデル = 構造化CSV(xBRL-CSV)
-
Translator = 汎用データ交換器
とする中核モデルとして整理し直す。
5.1. 前提: 「コアインボイス論理モデル」とは何か
ここで言う「コアインボイス論理モデル」は、私の設計コンセプトであり、
-
EN 16931-1 のコアインボイスモデル利用仕様(Core Invoice Usage Specification)
-
CEN/TS 16931-3 の Syntax Binding(UBL 2.1 及び UN/CEFACT CII D16B への対応付け)
を参考に再整理したものである。
EN 16931-1 では、UBL や UN/CEFACT CII のような 具体的なXML構文とは独立した「意味論レベルの項目一覧(セマンティックモデル)」 をまず定義し、そのうえで CEN/TS 16931-3 が
-
「コアインボイスの項目」 → 「UBL の要素階層」
-
「コアインボイスの項目」 → 「CII の要素階層」
という 構文バインディング を規定している。
ただし CEN/TS 16931-3 の Syntax Binding は、
-
要素階層の対応関係(Business Term と XML 要素階層の対応)
-
その適用条件(Allowance/Charge の区別など)を説明文で補足
という、やや間接的な記述になっており、そのままでは機械処理(自動変換)に使いにくい。
そこで本稿では、「コアインボイス論理モデル」を次のように捉え直す。
-
ビジネス用語レベルの論理項目(セマンティック項目)を一覧にしたテーブルをコアとする。
-
各論理項目について、構文ごとに XPath で明確に 対応要素を指定する。
-
例:
-
UBL 向け:
/Invoice/cac:AllowanceCharge[cbc:ChargeIndicator=false()]/cbc:Amount -
CII 向け:
/rsm:CrossIndustryInvoice/ram:SpecifiedTradeAllowanceCharge/…
-
-
-
条件付きの対応(Allowance と Charge の区別、税区分・税率別の集計など)は、可能な限り XPath の述語で表現し、それでも書き切れない部分のみを最小限の説明文で補足する。
つまり、「論理モデル+構文バインディング」を
-
論理項目名(Business Term)
-
意味・定義
-
各構文への XPath(
[条件文]を含むセレクタ指定) -
適用条件(XPath で表現しきれない部分のみテキスト)
という 機械可読なテーブル として整理し、Translator(後述の汎用データ交換器)がそのまま参照できる形にしておく、という前提に立っている。
5.2. コアモデルを「構造化CSV(xBRL-CSV)」とする
この従来の「コアインボイス論理モデル(セマンティックモデル)」として想定していた部分を、思い切って
-
構造化CSV(xBRL-CSV+タクソノミ)
そのものに置き換える発想である。
-
勘定元帳や仕訳と同様に、インボイスや月次請求書、仕入明細なども「階層定義モデル」として表現する。
-
行・列の意味と制約は xBRL タクソノミ(概念・軸・メンバー)で定義し、機械可読なデータ辞書とする。
-
コアとして定義するのは、
-
インボイス行(売上/仕入行)
-
税区分・税率・通貨・金額
-
事業者(売り手/買い手/第三者)
-
-
これらを xBRL-CSV のテーブル(キューブ)として定義し、最小限の汎用モデルとする。
この構造化CSVタクソノミが、すべてのインボイス関連データの「中立な着地点=コアモデル」になる。
5.3. Translator を「汎用データ交換器」として再定義
第5章のアプリケーション B と F(送信側・受信側の Translator)を、次のように再定義する。
送信側 Translator(B)
-
内部の業務データ(ERP、販売管理など)から、まず「構造化CSV(xBRL-CSV)」を定義する。
-
コアインボイス用のタクソノミに従い、行(トランザクション)、列(項目)、軸(パーティ、税区分、通貨など)をマッピングする。
-
そのうえで、必要に応じて構文バインディングを適用し、
-
GS1 Invoice BSM → 構造化CSV
-
流通BMS Invoice → 構造化CSV
-
UN/CEFACT CII XML → 構造化CSV
-
UBL Invoice → 構造化CSV
-
Peppol PINT → 構造化CSV
-
中小企業共通 EDI XML → 構造化CSV
-
この形式にしておくことで、Translator(後述の汎用データ交換器)がそのテーブルをそのまま参照し、自動変換ロジックの基盤として利用できる、という前提に立っている。
受信側 Translator(F)
-
受け取った「構造化CSV(xBRL-CSV)」をそれぞれの構文(CII, UBL, Peppol, 共通EDI, 固定長EDI, JSON 等)に変換する。
-
構造化CSV → GS1 Invoice BSM
-
構造化CSV → 流通BMS Invoice
-
構造化CSV → UN/CEFACT CII XML
-
構造化CSV → UBL Invoice
-
構造化CSV → Peppol PINT
-
構造化CSV → 中小企業共通 EDI XML
-
-
コアの構造化CSVタクソノミに従って正規化し、税計算・与信・監査・レポートなど共通処理はできる限り CSV 側で行う。
-
最後に、構造化CSVから自社の内部フォーマット(テーブル・仕訳データ・データウェアハウスなど)への変換―意味論バインディング(Semantic Binding)―を行う。
このように Translator を「常に構造化CSVを中間表現とする汎用データ交換器」として設計すると、
-
ビジネスロジックや検証ルール(いわゆる Schematron に相当する制約)は xBRL-CSV+タクソノミ側に集約し、
-
外部インターフェイスごとの差異は 構文バインディング(論理階層モデル定義 ↔ XML/EDI/JSON 要素)の差し替えで対応できるようになる。
5.4. 多様な構文への対応は「バインディングの差し替え」で済ませる
この構造化CSV中心モデルでは、新しい構文やバージョンへの対応は、基本的に次の二段階になる。
-
既存の構造化CSVタクソノミで表現できる範囲かを確認する
-
足りない場合は、コア・タクソノミを拡張する。
-
それでも足りない特殊要素は、「両当事者間で合意する拡張(バイラテラル拡張)」として別キューブ/別 CSV に分離する。
-
-
新構文用の構文バインディングを定義する
-
「この XML の XPath は、構造化CSV のどの列(どの概念+軸)に対応するか」
-
「この EDI セグメント+データエレメントは、どの概念+軸に対応するか」
-
といったマッピングテーブルを追加するだけでよい。
-
つまり、
-
コア(構造化CSV+タクソノミ)はできるだけ安定させる。
-
周辺の構文バインディングを差し替え/追加することで、多様な EDI・XML・JSON に対応する。
という、「中心は動かさず、周りのバインディングだけを差し替える」設計が実現できる。
5.5. SBDH/ヘッダとの協調
最後に、第5章の Processing Flow と、この構造化CSV中心の汎用データ交換器をどう組み合わせるかを整理する。
-
SBDHは、
-
文書種別(Invoice / Statement / Self-Billing / 仕入明細 等)
-
ビジネスプロセス(注文〜出荷〜請求 / 月次請求 / 与信審査用データ提出 等)
-
取引先識別(Buyer / Seller / Intermediary)
-
使用すべきコアタクソノミのバージョン
-
-
を示す「論理ヘッダ」として機能する。
-
Translator(汎用データ交換器)は、
-
SBDH の情報を読んで「どの構造化CSVタクソノミを使うか」
-
そして「どの構文バインディングを選ぶか」
-
-
を決め、構造化CSV ↔ 各種構文の変換を行う。
-
構造化CSV(xBRL-CSV)は、
-
税計算・与信評価・統計分析・監査データ抽出など、インボイス関連データの共通処理の土台
-
xBRL タクソノミによる機械可読なデータ辞書
-
-
として位置付けられる。
結果として、
-
ヘッダ(SBDH 等): ルーティングとスキーマ選択
-
構造化CSV(xBRL-CSV): コアモデル+共通ロジック
-
構文バインディング: 各種 EDI/XML/JSON との接続
という三層構造が明確になる。
Processing Flow Overview で描かれた A〜G の流れはそのまま活かしつつ、「内部の標準世界」を構造化CSVに統一し、Translator を汎用データ交換器として設計し直すイメージである。
6. 日本の EDI・構造化CSV への応用メモ
日本の中小企業共通 EDI や Peppol/JP PINT、さらには構造化CSV(xBRL-CSV ベース)を用いた汎用データ交換器を設計する際にも、この Processing Flow Overview と構造化CSV中心モデルはそのまま応用できる。
-
アプリケーション A/B/F/G に相当する部分は、各社の業務システムと「構造化CSVコアモデル」との間をつなぐ変換ロジックとして実装できる。
-
アプリケーション C/D とデータストア 3/4 の部分は、AS2/ebMS/SOAP などのトランスポート層、あるいは Uranos や Peppol のようなメッセージングプラットフォームに対応させることができる。
-
アプリケーション E は、SBDH 相当のヘッダ情報をもとに、
-
どの構造化CSVタクソノミ(コアインボイス/月次請求/仕入明細 等)を使うか
-
どの構文バインディング(PINT/共通EDI/既存EDI 等)を選ぶか
-
-
を決定する「中立ハブ」として実装しやすい。
SBDH 第5章自体は 2004 年当時の XML/EDI 前提で書かれているが、
-
論理ヘッダとトランスポートヘッダの分離
-
送信側・受信側双方で SBDH を活用したルーティングとマッピング
-
Translator で構文差異を吸収するアーキテクチャ
という発想は、構造化CSV中心の汎用データ交換器にもそのまま継承できる。
7. まとめ
UN/CEFACT SBDH 仕様の第5章「Processing Flow Overview」は、SBDH がどのように業務アプリケーション、パーサ/トランスレータ、通信アプリケーション、ミドルウェアの間を流れ、そこでどのような役割を果たすのかを整理した「データフローの図」である。
本稿ではその内容を日本語で整理したうえで、
-
コアモデルを構造化CSV(xBRL-CSV)とし、
-
Translator を汎用データ交換器として再定義し、
-
多様な構文(CII/UBL/Peppol/共通EDI/既存EDI/JSON 等)への対応を「構文バインディングの差し替え」で行う
という拡張モデルを提示した。
これにより、
-
SBDH(論理ヘッダ)
-
構造化CSV+タクソノミ(コアモデル&共通ロジック)
-
構文バインディング(外部インターフェイス)
という三層アーキテクチャが明確になり、日本の中小企業共通 EDI、Peppol、Uranos エコシステム、xBRL GL などを相互接続するための実装指針としても活用できる。
今後のブログでは、このモデルを前提に、
-
月次請求書(前月残+当月発生+入金+調整)の構造化CSVタクソノミ例
-
CII/UBL/JP PINT/共通EDI との具体的な構文バインディング表
-
xBRL GL や監査データサービスへのブリッジ方法
-
既存の会計ソフト等が提供する専用CSVインタフェース(フラット)ファイルと構造化CSVの対応を定義する意味論バインディング(Semantic Binding)
など、もう一段具体的な設計パターンを検討していきたい。
なお、本稿で述べるコアインボイス・ゲートウェイは、汎用データ交換器のコアモデルをインボイス領域に特化させたものである。汎用データ交換器(コアインボイス・ゲートウェイ)の全体像については、次のブログ記事およびサイトも参照されたい。
-
JP PINT と中小企業共通EDIの構文変換を紹介する コアインボイスゲートウェイ サイト
構造化CSVをハブとして会計ソフトの仕訳日記帳を確認する 検索専用ブラウザ サイトも、併せてご確認いただきたい。CSV のカラムと論理階層モデルの要素の対応は、JSON Path を参考に新たに定義した論理パス(Semantic Path)を用いて記述する意味論バインディング(Semantic Binding)として定義している。同ブラウザで使用する構造化CSVは、それぞれの会計ソフト固有のインタフェースCSVと構造化CSVの要素対応を定義した意味論バインディング(Semantic Binding)表に基づき、「汎用データ交換器」で変換された結果である。

コメントを残す