
Views: 20
XBRL Japanでの勉強会の動画公開しました。下の画像をクリックするとYouTubeで視聴できます。
発表で使用しているWebノートは、無為です。
Google翻訳をもとに加筆修正しました。デジタル会計帳簿の Tidy data (整頓されたデータ)アプローチの参考文献である”Tidy data”の前半部分の翻訳です。
Tidy Data, Journal of Statistical Software, August 2014, Volume 59, Issue 10, Headley Wickham
https://www.jstatsoft.org/article/view/v059i10
Tidy Data
RStudio
概要
分析の準備を整えるためにデータのクリーニングに多大な労力が費やされていますが、データのクリーニングを可能な限り簡単かつ効果的に行う方法についての研究はほとんどありません。
この論文では、小さいながらも重要なデータ クリーニングのコンポーネントであるデータの整頓に取り組みます。
整頓されたデータセットは、操作、モデル化、視覚化が容易で、特定の構造を持っています。各々の変数(variable)は列、各々の観測値(observation)は行、各々のタイプの観測単位はテーブルです。 このフレームワークを使用すると、乱雑なデータセットを簡単に整頓できます。これは、整頓されていないさまざまなデータセットを処理するために必要なツールのセットが少なくて済むためです。 また、この構造により、データ分析用の整然としたツール、入力と分析の両方を行うツールの開発が容易になります。
整頓されたデータセット(tidy dataset)を出力します。 一貫したデータ構造とマッチング ツールの利点は、ありふれたデータ操作作業から解放されたケース スタディで実証されます。
キーワード: data cleaning, data tidying, relational databases, R.
1.はじめに
データ分析の 80% は、データのクリーニングと準備のプロセスに費やされるとよく言われます (Dasu and Johnson 2003)。 データの準備は単なる最初のステップではなく、新しい問題が明らかになったり、新しいデータが収集されたりするたびに、分析の過程で何度も繰り返さなければなりません。 時間がかかるにもかかわらず、データを適切にクリーニングする方法に関する研究は驚くほど少ない。課題の一部は、外れ値のチェックから日付の解析、欠損値の代入まで、含まれるアクティビティの幅が広いことです。 この問題を解決するために、この論文では、小さいながらも重要なデータ クリーニングの側面に焦点を当てます。これを私はデータの整頓(data tidying)と呼んでいます。それは、データセットを構造化して分析を容易にすることです。整頓されたデータ(tidy data)の原則は、データセット内のデータ値を整頓する標準的な方法を提供します。 標準を使用すると、最初から始めて毎回車輪を再発明する必要がないため、最初のデータ クリーニングが容易になります。 整頓されたデータ(tidy data)標準は、データの初期調査と分析を容易にし、連携して機能するデータ分析ツールの開発を簡素化するように設計されています。 現在のツールでは、データ変換が必要になることがよくあります。 あるツールからの出力を別のツールに入力できるように、時間をかけて変更する必要があります。 整頓されたデータセット(tidy dataset)と整頓されたツールは連携してデータ分析を容易にし、興味のないデータのロジスティクスではなく、興味深いドメインの問題に集中できるようにします。整頓されたデータ(tidy data)の原則は、リレーショナル データベースや Codd のリレーショナル代数 (Codd 1990) の原則と密接に結びついていますが、統計学者になじみのある言語で組み立てられています。 コンピューター科学者も、データ クリーニングの研究に大きく貢献してきました。 たとえば、Lakshmanan、Sadri、および Subramanian (1996) は、SQL の拡張機能を定義して乱雑なデータセットを操作できるようにし、Raman と Hellerstein (2001) はデータセットをクリーニングするためのフレームワークを提供し、Kandel、Paepcke、Hellerstein、および Heer (2011) ) データをクリーンアップするためのコードを自動的に作成する、使いやすいユーザー インターフェイスを備えた対話型ツールを開発します。 これらのツールは便利ですが、ほとんどの統計学者にとってなじみのない言語で提示されており、データセットをどのように構造化すべきかについて多くのアドバイスを与えることができず、データ分析ツールとの関連性が欠けています。整頓されたデータ(tidy data)の開発は、実世界のデータセットを扱った私の経験によって推進されてきました。 組織に制約があったとしてもほとんどないため、このようなデータセットは奇妙な方法で構築されることがよくあります。 私は数え切れないほどの時間を費やして、そのようなデータセットを整頓して、データ分析を可能にするだけでなく、簡単にする方法で苦労してきました. また、学生が現実世界のデータセットに自分で取り組めるように、これらのスキルを学生に教えることにも苦労しました。 これらの闘争の過程で、私は reshape および reshape2 (Wickham 2007) パッケージを開発しました。 ツールを直感的に使用し、例を通して教えることができましたが、直感を明確にするためのフレームワークがありませんでした。 この論文では、そのフレームワークを提供します。 これは、plyr (Wickham 2011) および ggplot2 (Wickham 2009) パッケージでの私の作業の根底にある、包括的な「データの哲学」を提供します。論文は次のように進行します。 セクション 2 では、データセットを整頓する 3 つの特性を定義することから始めます。 現実世界のほとんどのデータセットは整頓されていないため、セクション 3 では、乱雑なデータセットを整頓するために必要な操作について説明し、さまざまな実際の例を使用して手法を示します。 セクション 4 では、tidy ツール (整頓されたデータセット(tidy dataset)を入力および出力するツール) を定義し、整頓されたデータ(tidy data)と tidy ツールを組み合わせることでデータ分析がどのように容易になるかについて説明します。 これらの原則は、セクション 5 の小さなケース スタディで説明されています。セクション 6 では、このフレームワークに欠けているものと、他のどのアプローチを追求すると有益であるかについての議論で締めくくります。
2. 整頓されたデータ(tidy data)を定義する
幸せな家族は皆同じです。 すべての不幸な家族は、それぞれ独自の方法で不幸です。
家族のように、整頓されたデータセット(tidy dataset)はすべて似ていますが、すべての乱雑なデータセットは独自の方法で乱雑です。 整頓されたデータセット(tidy dataset)は、データセットの構造 (物理的なレイアウト) をそのセマンティクス (意味) にリンクする標準化された方法を提供します。 このセクションでは、データセットの構造とセマンティクス(意味)を説明するための標準語彙をいくつか提供し、それらの定義を使用して整頓されたデータ(tidy data)を定義します。
2.1. データ構造
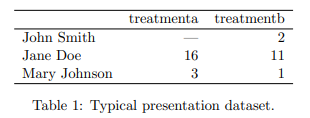
ほとんどの統計データセットは、行と列で構成される長方形のテーブルです。 ほとんどの場合、列にはラベルが付けられ、行にもラベルが付けられることがあります。 表 1 は、実際に一般的に見られる形式で架空の実験に関するいくつかのデータを提供します。 表には 2 つの列と 3 つの行があり、行と列の両方にラベルが付けられています。
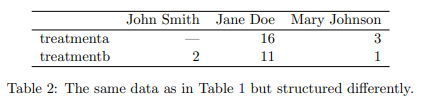
同じ基になるデータを構造化する方法は多数あります。 表 2 は、表 1 と同じデータを示していますが、行と列が転置されています。 データは同じですが、レイアウトが異なります。 行と列の語彙は、2 つのテーブルが同じデータを表す理由を説明するのに十分ではありません。 外観に加えて、表に表示される値の基礎となるセマンティクス(意味)を記述する方法が必要です。
2.2. データのセマンティクス(意味)
データセットは値のコレクションであり、通常は数値 (定量的な場合) または文字列 (定性的な場合) です。 値は 2 つの方法で編成されます。 すべての値は、変数(variable)と観測(observation)に属します。 変数には、ユニット全体で同じ基本属性 (高さ、温度、期間など) を測定するすべての値が含まれます。 観測には、属性全体で同じ単位 (人、日、人種など) で測定されたすべての値が含まれます。
表 3 は、値(value)、変数(variable)、観測(observation)をより明確にするために、表 1 を再編成したものです。 データセットには、3 つの変数と 6 つの観測値を表す 18 の値が含まれています。 変数は次のとおりです。
1. person、可能な値は 3 つ (John Smith、Mary Johnson、および Jane Doe)。
2. treatment 2 つの可能な値 (a と b) を持つ治療。
3. result 欠損値の考え方に応じて、5 つまたは 6 つの値を持つ結果 (—, 16, 3, 2, 11, 1)。
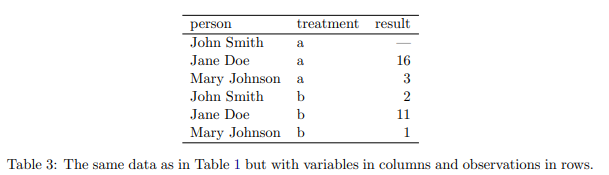
表 3: 表 1 と同じデータですが、列に変数、行に観測値があります。
実験計画は、観測の構造について詳しく教えてくれます。 この実験では、人と治療のすべての組み合わせが測定され、完全に交差したデザインになっています。 実験計画では、欠損値を安全に削除できるかどうかも決定します。 この実験では、欠損値は、行われるべきであったが行われなかった観測を表しているため、それを維持することが重要です。 測定できない測定値 (妊娠中の男性の数など) を表す構造的な欠損値は、安全に削除できます。
通常、特定のデータセットについて、何が観測値で何が変数かを理解するのは簡単ですが、変数と観測値を一般的に正確に定義することは驚くほど困難です。たとえば、表 1 の列が身長と体重である場合、それらを変数と呼んでもよかったでしょう。列が高さと幅である場合、高さと幅をディメンション変数の値と考える可能性があるため、明確ではありません。列が自宅の電話番号と勤務先の電話番号である場合、これらを 2 つの変数として扱うことができますが、不正検出環境では、複数の人が 1 つの電話番号を使用すると不正行為を示唆する可能性があるため、電話番号と番号の種類の変数が必要になる場合があります。一般的な経験則では、行間よりも変数間の関数関係 (たとえば、z は x と y の線形結合、密度は重量と体積の比率) を記述する方が簡単であり、変数間の比較を行う方が簡単です。列のグループ間よりも観測値のグループ (たとえば、グループ a の平均とグループ b の平均) を比較します。
特定の分析では、複数のレベルの観測が存在する場合があります。 たとえば、新しいアレルギー治療薬の試験では、3 つの観測タイプがあります。各人から収集された人口統計データ (年齢、性別、人種)、各人から毎日収集された医療データ (くしゃみの回数、目の充血)、 毎日収集された気象データ(気温、花粉数)。
2.3. 整頓されたデータ(tidy data)
整頓されたデータ(tidy data)は、データセットの意味をその構造にマッピングする標準的な方法です。 データセットは、行、列、およびテーブルが観測、変数、および観測のタイプとどのように一致しているかに応じて、乱雑または整頓されています。 整頓されたデータ(tidy data)では:
1. 各々の変数(variable)が列を形成します。
2. 各々の観測値(observation)が行を形成します。
3. 観測のタイプ(type of observational unit)ごとにテーブルを形成します。
これは Codd の第 3 正規形 (Codd 1990) ですが、制約が統計言語で構成されており、リレーショナル データベースで一般的な多数の接続されたデータセットではなく、単一のデータセットに焦点が当てられています。 乱雑なデータは、データのその他の配置です。
表 3 は表 1 を整頓したものです。各々の行は観測結果、1 人に対する 1 つの治療の結果を表し、各々の列は変数です。
整頓されたデータは、データセットを構造化する標準的な方法を提供するため、アナリストやコンピューターが必要な変数を簡単に抽出できるようにします。 表 3 を表 1 と比較してください。表 1 では、さまざまな戦略を使用してさまざまな変数を抽出する必要があります。 これにより、分析が遅くなり、エラーが発生します。 変数内のすべての値 (すべての集計関数) を含むデータ分析操作の数を考慮すると、単純で標準的な方法でこれらの値を抽出することがいかに重要であるかがわかります。 整頓されたデータは、R (R Core Team 2014) のようなベクトル化されたプログラミング言語に特に適しています。これは、同じ観測結果からの異なる変数の値が常にペアになるようにレイアウトされているためです。
変数と観測の順序は分析に影響しませんが、順序が適切であれば、生の値をスキャンしやすくなります。 変数を整頓する 1 つの方法は、分析での役割ごとです。値はデータ コレクションの設計によって固定されているのでしょうか、それとも実験の過程で測定されたものでしょうか? 固定変数は、実験計画を記述し、事前にわかっています。 コンピューター科学者は固定変数次元と呼ぶことが多く、統計学者は通常、確率変数の添字で次元を示します。 測定変数は、調査で実際に測定するものです。 固定変数が最初に来て、その後に測定変数が続き、関連する変数が連続するようにそれぞれが順序付けられます。 次に、行を最初の変数で並べ替え、2 番目以降の (固定された) 変数との関係を断ち切ることができます。 これは、このホワイト 論文のすべての表形式の表示で採用されている規則です。
3. 乱雑なデータセットの整頓
実際のデータセットは、考えられるほぼすべての方法で、整頓されたデータの 3 つの原則に違反する可能性があり、実際に違反することがよくあります。 すぐに分析を開始できるデータセットを取得することもありますが、これは例外であり、規則ではありません。 このセクションでは、乱雑なデータセットに関する 5 つの最も一般的な問題とその解決策について説明します。
* 列ヘッダーは値であり、変数名ではありません。
* 複数の変数が 1 つの列に格納されています。
* 変数は行と列の両方に格納されています。
* 複数の種類の観測単位が同じテーブルに格納されています。
* 1 つの観測単位が複数のテーブルに格納されています。
驚くべきことに、上記で明示的に説明されていないタイプの乱雑さを含むほとんどの乱雑なデータセットは、小さなツール セット (融解、文字列分割、キャスト) で整頓できます。 以下のセクションでは、私が遭遇した実際のデータセットでの問題をそれぞれ説明し、それらを整頓する方法を示します。 完全なデータセットとそれらを整頓するために使用される R コードは、”https://github.com/hadley/tidy-data” でオンラインで入手でき、この論文のオンライン補足資料でも入手できます。
3.1. 列ヘッダーは値であり、変数名ではありません
乱雑なデータセットの一般的なタイプは、プレゼンテーション用に設計された表形式のデータです。変数は行と列の両方を形成し、列ヘッダーは変数名ではなく値です。 私はこの配置を乱雑と呼んでいますが、場合によっては非常に便利です。 完全に交差した計画に効率的なストレージを提供し、必要な操作を行列操作として表現できる場合、非常に効率的な計算につながる可能性があります。 この問題については、セクション 6 で詳しく説明します。
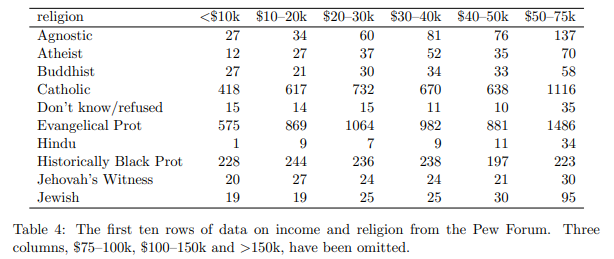
表 4: ピュー フォーラムの収入と宗教に関するデータの最初の 10 行。 $75-100k、$100-150k、>150k の 3 つの列は省略されています。
表 4 は、この形式の典型的なデータセットのサブセットを示しています。このデータセットは、米国における収入と宗教の関係を調査しています。これは、宗教からインターネットに至るまでのトピックに対する態度に関するデータを収集し、この形式のデータセットを含む多くのレポートを作成するアメリカのシンクタンクであるピュー リサーチ センターによって作成されたレポート[1]に由来します。
このデータセットには、宗教、収入、頻度の 3 つの変数があります。きれいにするには、溶かすか、積み重ねる必要があります。つまり、列を行に変換する必要があります。これは、幅の広いデータセットを長くしたり高くしたりすると説明されることがよくありますが、これらの用語は不正確であるため避けます。

表 5: 融解の簡単な例。 (a) は、1 つの colvar、行で融解され、融解したデータセット (b) が得られます。 各々のテーブルの情報はまったく同じで、保存方法が異なるだけです。
おもちゃのデータセットを使用して表 5 で説明します。融解は、すでに変数である列のリスト、または略して colvar によってパラメーター化されます。他の列は 2 つの変数に変換されます。列見出しの繰り返しを含む column と呼ばれる新しい変数と、以前に分離された列から連結されたデータ値を含む value と呼ばれる新しい変数です。融解の結果が融解データセットです。
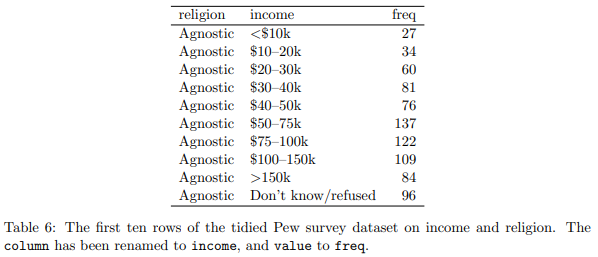
表 6: 収入と宗教に関する Pew 調査データセットの整頓された最初の 10 行。 列の名前が収入に、値が頻度に変更されました。
Pew データセットを、一つのcolvar(宗教)で融解することにより表 6 が得られます。このデータセットでの役割をより適切に反映するために、変数列の名前が収入に、値列の名前が freq(頻度) に変更されました。 各々の列が変数を表し、各々の行が観測値を表しているため、このフォームは整然としています。この場合、宗教と収入の組み合わせに対応する人口統計単位です。
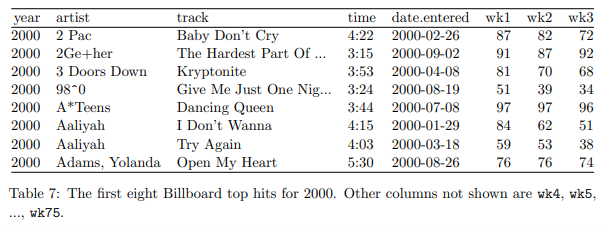
表 7: 2000 年の最初の 8 つのビルボード トップ ヒット。表示されていない他の列は、wk4、wk5、…、wk75 です。
このデータ形式のもう 1 つの一般的な用途は、時間の経過とともに規則的な間隔で観測を記録することです。 たとえば、表 7 に示すビルボード データセットは、曲がビルボード トップ 100 に最初に入った日付を記録します。これには、アーティスト、トラック、日付、ランク、週の変数があります。 上位 100 位に入ってからの各々の週の順位は、wk1 から wk75 までの 75 列に記録されます。 曲のトップ 100 入りが 75 週間未満の場合、残りの列は欠損値で埋められます。 この形式のストレージは整頓されていませんが、データ入力には便利です。 そうしないと、各々の週の各々の曲に独自の行が必要になり、タイトルやアーティストなどの曲のメタデータを繰り返す必要があるため、重複を減らします。 この問題については、セクション 3.4 で詳しく説明します。
このデータセットには、年、アーティスト、トラック、時間、および日付が入力された colvars があります。 溶解することで 表 8 が得られます。整頓と同様に少しのクリーニングも行いました。数値を抽出して列を週に変換し、date.entered と週から日付を計算しました。
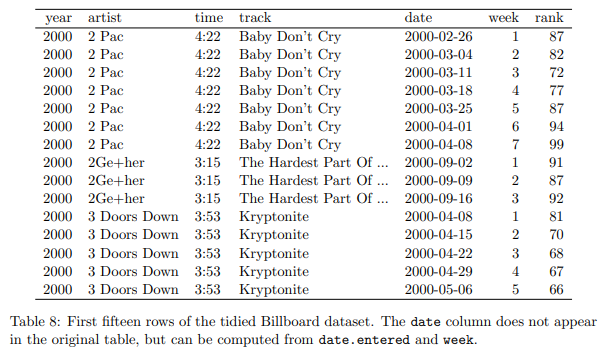
表 8: 整頓された Billboard データセットの最初の 15 行。 日付列は元のテーブルには表示されませんが、date.entered と week から計算できます。
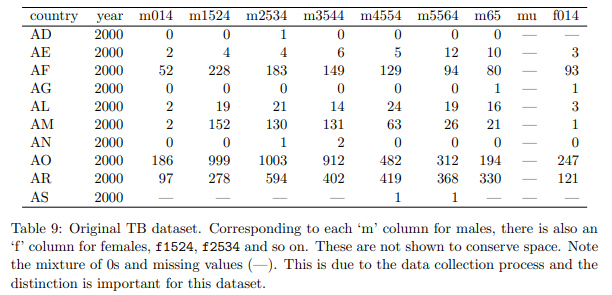
表 9: 元の TB データセット。 男性の各「m」列に対応して、女性の「f」列、f1524、f2534 などもあります。 これらは、スペースを節約するために表示されていません。 0 と欠損値 (—) が混在していることに注意してください。 これはデータ収集プロセスによるものであり、このデータセットでは区別が重要です。
3.2. 1 複数の変数が 1 つの列に格納されています
融解後、列変数名は、多くの場合、複数の基になる変数名の組み合わせになります。 これは結核 (TB) データセットによって示され、そのサンプルを表 9 に示します。このデータセットは世界保健機関から取得され、国、年、および人口統計グループごとに確認された結核症例の数を記録します。 人口統計グループは、性別 (m、f) と年齢 (0 ~ 14、15 ~ 25、25 ~ 34、35 ~ 44、45 ~ 54、55 ~ 64、不明) によって分類されます。
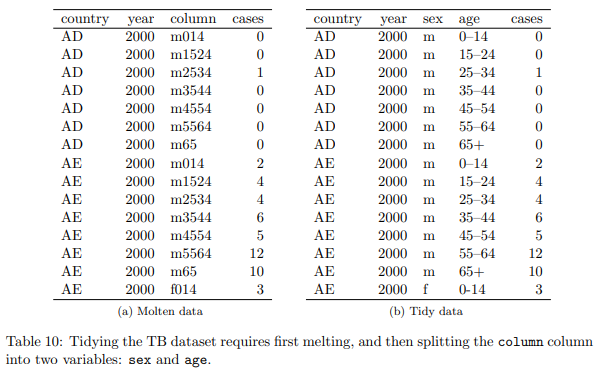
表 10: 結核データセットを整頓するには、最初に溶解してから、列の列を性別と年齢の 2 つの変数に分割する必要があります。
この形式の列ヘッダーは、多くの場合、文字 (.、-、_、:) で区切られています。 その文字を区切り記号として使用して文字列を分割できますが、このデータセットのように他の場合では、より慎重な文字列処理が必要です。 たとえば、変数名は、単一の複合値を複数のコンポーネント値に変換するルックアップ テーブルに一致させることができます。
表 10(a) は TB データセットを融解した結果を示し、表 10(b) は 1 つの列の列を年齢と性別の 2 つの実数変数に分割した結果を示しています。 この形式で値を格納すると、元のデータの別の問題が解決されます。 カウントではなく、レートを比較したい。 しかし、率を計算するには、母集団を知る必要があります。 元の形式では、人口変数を追加する簡単な方法はありません。 別のテーブルに格納する必要があるため、母集団をカウントに正しく一致させることが難しくなります。 整然とした形式では、人口と割合の変数を追加するのは簡単です。 それらは単なる追加の列です。
3.3. 変数は行と列の両方に格納されています
乱雑なデータの最も複雑な形式は、変数が行と列の両方に格納されている場合に発生します。 表 11 は、2010 年の 5 か月間のメキシコの 1 つの気象観測所 (MX17004) の Global Historical Climatology Network からの毎日の気象データを示しています。個々の列 (id、年、月) に変数があり、列 (日、d1 ~ d31) に広がっています。) および行全体 (tmin、tmax) (最小および最大温度)。 31 日未満の月には、その月の最終日に構造的な欠損値があります。 要素列は変数ではありません。 変数の名前を格納します。
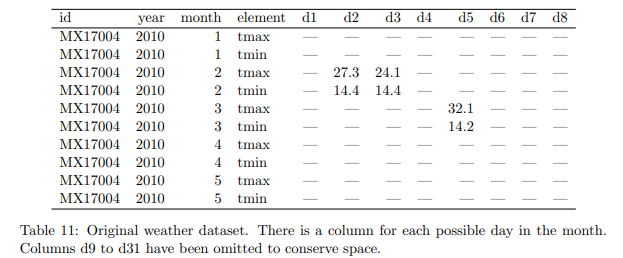
表 11: 元の気象データセット。 その月の可能性のある日ごとに列があります。 列 d9 から d31 は、スペースを節約するために省略されています。
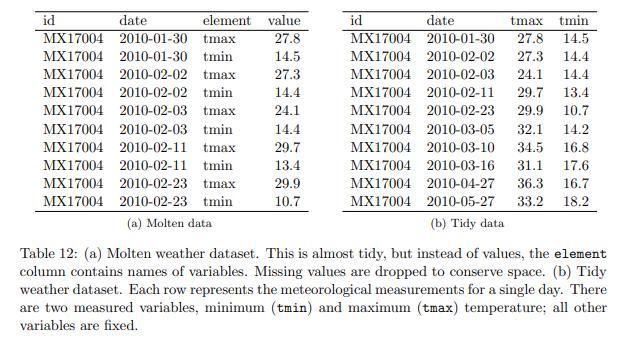
表 12: (a) 溶融気象データセット。 これはほとんど整頓されていますが、値の代わりに、要素列には変数の名前が含まれています。 スペースを節約するために、欠損値は削除されます。 (b) 整頓された気象データセット。 各々の行は、1 日の気象測定値を表します。 測定変数には、最低 (tmin) と最高 (tmax) の 2 つの温度があります。 他のすべての変数は固定されています。
このデータセットを整頓するには、最初に colvars id、年、月、および変数名、要素を含む列でそれを溶かします。 これにより、表 12(a) が得られます。 プレゼンテーションのために、欠落している値を削除し、明示的ではなく暗黙的にしました。 これは、各々の月の日数が分かっており、明示的な欠損値を簡単に再構築できるため、許容されます。
このデータセットはほとんど整然としていますが、2 つの変数が行に格納されています: tmin と tmax で、観測の種類です。 この例では、他の気象変数 prcp (降水量) と snow (降雪量) は示されていません。 観測のタイプに関する問題を修正するには、キャストまたはアンスタック操作が必要です。 これは、要素変数を回転させて列に戻すことにより、融解の逆を実行します (表 12(b))。 この形は整っています。 各々の列には 1 つの変数があり、各々の行は 1 日の観測を表します。 キャスト操作については、Wickham (2007) で詳しく説明されています。
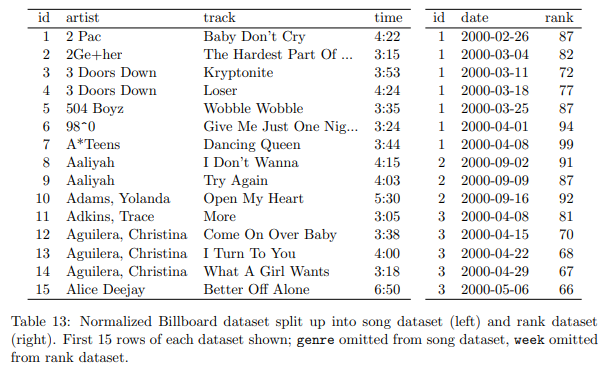
表 13: 曲のデータセット (左) とランクのデータセット (右) に分割された正規化されたビルボード データセット。 表示されている各々のデータセットの最初の 15 行。 曲のデータセットから除外されたジャンル、ランクのデータセットから除外された週。
3.4. 複数の種類の観測単位が同じテーブルに格納されています
多くの場合、データセットには、さまざまな種類の観測単位で、複数のレベルで収集された値が含まれます。 整頓中は、各々のタイプの観測単位を独自のテーブルに格納する必要があります。 これは、各々の事実が 1 か所だけで表現されるデータベースの正規化の考え方と密接に関連しています。 これを行わないと、不整合が発生する可能性があります。
表 8 で説明されている Billboard データセットには、実際には 2 種類の観測単位に関する観測が含まれています。曲とその週ごとのランクです。 これは、曲に関する事実の重複によって明らかになります。アーティストと時間は、毎週すべての曲で繰り返されます。 ビルボード データセットは、2 つのデータセットに分割する必要があります。1 つはアーティスト、曲名、時間を格納する曲データセットで、もう 1 つはその曲の週ごとのランクを示すランキング データセットです。 表 13 は、これら 2 つのデータセットを示しています。 1 週間の背景情報 (販売された曲の総数や同様の人口統計情報など) を記録する 1 週間のデータセットを想像することもできます。
正規化は、矛盾を整頓して排除するのに役立ちます。 ただし、リレーショナル データを直接操作するデータ分析ツールはほとんどないため、分析には通常、非正規化またはデータセットを 1 つのテーブルにマージする必要があります。
3.5. 1 つの観測単位が複数のテーブルに格納されています
また、複数のテーブルまたはファイルにまたがる単一タイプの観測単位に関するデータ値を見つけることも一般的です。 これらのテーブルとファイルは、多くの場合、別の変数によって分割されるため、それぞれが 1 つの年、人、または場所を表します。 個々のレコードのフォーマットが一貫している限り、これは簡単に修正できる問題です。
1. ファイルをテーブルのリストに読み込みます。
2. 各々のテーブルに、元のファイル名を記録する新しい列を追加します (ファイル名は重要な変数の値であることが多いため)。
3. すべてのテーブルを 1 つのテーブルに結合します。
plyr パッケージを使用すると、R でこれを簡単に実行できます。次のコードは、正規表現 (.csv で終わる) に一致するディレクトリ (data/) 内のファイル名のベクトルを生成します。 次に、ベクトルの各々の要素にファイルの名前を付けます。 これを行うのは、plyr が次のステップで名前を保持し、最終的なデータ フレームの各々の行にそのソースのラベルが付けられるようにするためです。 最後に、ldply() は各々のパスをループし、CSV ファイルを読み取り、結果を 1 つのデータ フレームに結合します。
R> paths <- dir("data", pattern = "\\.csv$", full.names = TRUE)
R> names(paths) <- basename(paths)
R> ldply(paths, read.csv, stringsAsFactors = FALSE)テーブルを 1 つ作成したら、必要に応じて追加の整頓を実行できます。 このタイプのクリーニングの例は、”https://github.com/hadley/data-baby-names” で見つけることができます。これは、米国社会保障局が提供する 129 年間の赤ちゃんの名前テーブルを取得し、それらを 1 つのファイルに結合します。
データセットの構造が時間とともに変化すると、より複雑な状況が発生します。 たとえば、データセットには、異なる変数、異なる名前の同じ変数、異なるファイル形式、または欠損値の異なる規則が含まれる場合があります。 これには、各ファイルを個別に (または、運が良ければ小さなグループで) 整頓し、整頓したらそれらを結合する必要がある場合があります。 このタイプの整頓の例は、”https://github.com/hadley/data-fuel-economy” に示されています。これは、1978 年から 2008 年までの 50,000 台を超える車の EPA 燃費データの整頓を示しています。生データはオンラインで入手できます。 ただし、毎年別のファイルに保存され、多くのマイナーなバリエーションを含む 4 つの主要な形式があるため、このデータセットを整頓することはかなりの課題です。 ■
これ以降の4. Tidy tools, 5. Case study, 6. Discussion は、省略しました。
