
Views: 8
XBRL Japanでの勉強会の動画を次のアドレスから公開しました。
https://youtu.be/_zBWUsRz5K4
発表で使用しているWebノートは、無為です。
デジタル会計帳簿のTidy data(整頓されたデータ)アプローチ
仕訳入力例
総勘定元帳の仕訳入力用にTidy data(整頓されたデータ)を定義する方法を検討します。
次は、用紙を現金で購入したときの仕訳入力例です。
| 日付 | 明細行摘要 | 借方 金額 |
貸方 金額 |
科目 番号 |
科目名 | C | N | T | ID |
|---|---|---|---|---|---|---|---|---|---|
|
2009-04-03 |
用紙 |
14,858 |
754 |
事務用消耗品費 |
10 |
札幌 |
部門 |
943-8-477 |
|
|
2009-04-03 |
742 |
191 |
仮払消費税等 |
10 |
札幌 |
部門 |
943-8-477 |
||
|
2009-04-03 |
用紙 |
15,600 |
111 |
現金 |
0 |
共通部門 |
部門 |
943-8-477 |
|
|
Key C: ビジネスセグメントコード, N: ビジネスセグメントタイプ, T: ビジネスセグメントタイプ |
|||||||||
今回の検証で使用したデータは、今世紀初頭にPCA会計9V.2の仕訳データをXBRL-GL (XBRL 2.0a) に変換して出力したもので、架空の企業の1年間の記帳データ [data] です。
国際的な標準仕様で出力したデータは、その当時のプログラムを用いることなく数十年たっても確認することができます。
今回のTidy Dataアプローチで1/12以上の容量削減になりました(31MB → 2.4MB)。xBRL-CSVもxBRLインスタンスですからタクソノミを使用したバリデーションやフォーミュラを使用した検証がCSVファイルでも可能です。
WickhamnによるTidy Dataの例
私たちの行と列の語彙は、2 つのテーブルが同じデータを表す理由を説明するのに十分ではありません。 外観に加えて、テーブルに表示される値の基本的なセマンティクスまたは意味を説明する方法が必要です。
Tidy Data Journal of Statistical Software August 2014 Volume 59 Issue 10
| 処置 A | 処置 B | |
|---|---|---|
|
John Smith |
– |
2 |
|
Jane Doe |
16 |
11 |
|
Mary Johnson |
3 |
1 |
| John Smith | Jane Doe | Mary Johnson | |
|---|---|---|---|
|
処置 A |
– |
16 |
3 |
|
処置 B |
2 |
11 |
1 |
データセットは 値 のコレクションです。 値 は 2 つの方法で編成されます。 すべての 値 は、 変数 と 観測 に属します。
表 4 は、表 1 を再構成して、値、変数、および 観測 をより明確にしています。 変数 は次のとおりです。
1. 個人, 3つの取りうる値がある (John Smith, Mary Johnson, および Jane Doe)
2. 処置, 2つの取りうる値がある (A および B)
3. 結果値, 欠損値をどう位置付けるかで5つあるいは6つの値がある。 (-, 16, 3, 2, 11, 1).
Tidy Data Journal of Statistical Software August 2014 Volume 59 Issue 10
| 個人 | 処置 | 値 |
|---|---|---|
|
John Smith |
A |
– |
|
Jane Doe |
A |
16 |
|
Mary Johnson |
A |
3 |
|
John Smith |
B |
2 |
|
Jane Doe |
B |
11 |
|
Mary Johnson |
B |
1 |
Tidy data(整頓されたデータ)では:
— 各 変数 が列を形成します。
— 各 観測 値が行を形成します。
— 観測 の種類ごとに表が形成されます。
Tidy Data Journal of Statistical Software August 2014 Volume 59 Issue 10
総勘定元帳の意味構造
Table 5 は、総勘定元帳の意味構造を示しています。 この階層データ構造は、変数がデジタル台帳でどのように編成されているかを表しています。
これを 1 つのTidy data(整頓されたデータ)で表すことが目標です。
| ID | H | 項目 | 繰返 | データ型 |
|---|---|---|---|---|
|
A25 |
0 |
総勘定元帳 |
0..n |
集約 |
|
A25-01 |
1 |
•仕訳ID |
1..1 |
識別子 |
|
A25-02 |
1 |
•仕訳番号 |
0..1 |
コード |
|
A25-09 |
1 |
•Header Description |
0..1 |
文字 |
|
A25-10 (A25-A26) |
1 |
•総勘定元帳明細行 |
1..n |
集約 |
|
A26-03 (A26-A09) |
2 |
••勘定科目 |
1..1 |
集約 |
|
A26-A09-01 |
3 |
•••勘定科目番号 |
1..1 |
識別子 |
|
A26-A09-02 |
3 |
•••勘定科目名 |
0..1 |
文字 |
|
A26-A09-05 |
3 |
•••勘定科目タイプ |
0..1 |
コード |
|
A26-A09-06 |
3 |
•••補助科目タイプ |
0..1 |
コード |
|
A25-A26-06 |
2 |
••日付 |
0..1 |
日付 |
|
A25-A26-08 |
2 |
••仕訳タイプコード |
0..1 |
コード |
|
A25-A26-07 |
2 |
••明細行番号 |
0..1 |
コード |
|
A25-A26-10 |
2 |
••明細行摘要 |
0..1 |
文字 |
|
A25-A26-11 |
2 |
••源コード |
0..1 |
コード |
|
A25-A26-12 |
2 |
••書類番号 |
0..1 |
コード |
|
A25-A26-14 |
2 |
••書類日付 |
0..1 |
日付 |
|
A25-A26-27 |
2 |
••貸借区分 |
0..1 |
コード |
|
A26-18 (A26-A89) |
2 |
••多通貨金額 |
1..n |
集約 |
|
A26-A89-01 |
3 |
•••金額 |
1..1 |
金額 |
|
A26-A89-02 |
3 |
•••通貨 |
1..1 |
コード |
|
A26-41 (A26-A01) |
2 |
••ビジネスセグメント |
1..n |
集約 |
|
A26-A01-03 |
3 |
•••ビジネスセグメント参照レベル |
1..1 |
コード |
|
A26-A01-01 |
3 |
•••ビジネスセグメントコード |
1..1 |
コード |
|
A26-A01-02 |
3 |
•••ビジネスセグメントタイプ |
1..1 |
文字 |
|
A26-A01-04 |
3 |
•••組織タイプ |
0..1 |
文字 |
|
Key H: 階層レベル |
||||
第3正規型の表
上記の意味構造を表現するための従来のアプローチは、多くの Codd の第 3 正規形の表を定義し、これらの表をリレーショナル データベースで接続することです。
Tidy data(整頓されたデータ)は、多数の接続されたデータセットではなく、単一のデータ セットに焦点を当てます。
次に示す表 6、表 7、表 8、表 9、および表 10 は、第3正規型の表です。これを 1 つのTidy data(整頓されたデータ)としてまとめます。
| ID | H | 項目 | 繰返 | データ型 |
|---|---|---|---|---|
|
A25 |
0 |
総勘定元帳 |
0..n |
集約 |
|
A25-01 |
1 |
•仕訳ID |
1..1 |
識別子 |
|
A25-02 |
1 |
•仕訳番号 |
0..1 |
コード |
|
A25-09 |
1 |
•摘要 |
0..1 |
文字 |
|
A25-10 (A25-A26) |
1 |
•総勘定元帳明細行 |
1..n |
集約 |
|
Key H: 階層レベル |
||||
| ID | H | 項目 | 繰返 | データ型 |
|---|---|---|---|---|
|
A26 |
0 |
総勘定元帳明細行 |
0..n |
集約 |
|
A26-03 (A26-A09) |
1 |
•勘定科目 |
1..1 |
集約 |
|
A26-06 |
1 |
•日付 |
0..1 |
日付 |
|
A26-08 |
1 |
•仕訳タイプコード |
0..1 |
コード |
|
A26-07 |
1 |
•明細行番号 |
0..1 |
コード |
|
A26-10 |
1 |
•明細行摘要 |
0..1 |
文字 |
|
A26-11 |
1 |
•源コード |
0..1 |
コード |
|
A26-12 |
1 |
•書類番号 |
0..1 |
コード |
|
A26-14 |
1 |
•書類日付 |
0..1 |
日付 |
|
A26-27 |
1 |
•貸借区分 |
0..1 |
コード |
|
A26-18 (A26-A89) |
1 |
•多通貨金額 |
1..1 |
集約 |
|
A26-41 (A26-A01) |
1 |
•ビジネスセグメント |
1..n |
集約 |
|
Key H: 階層レベル |
||||
| ID | H | 項目 | 繰返 | データ型 |
|---|---|---|---|---|
|
A09 |
0 |
勘定科目 |
0..n |
集約 |
|
A09-01 |
1 |
•勘定科目番号 |
1..1 |
識別子 |
|
A09-02 |
1 |
•勘定科目名 |
0..1 |
文字 |
|
A09-05 |
1 |
•勘定科目タイプ |
0..1 |
コード |
|
A09-06 |
1 |
•補助科目タイプ |
0..1 |
コード |
|
Key H: 階層レベル |
||||
| ID | H | 項目 | 繰返 | データ型 |
|---|---|---|---|---|
|
A89 |
0 |
多通貨金額 |
0..n |
集約 |
|
A89-01 |
1 |
•金額 |
1..1 |
金額 |
|
A89-02 |
1 |
•通貨 |
1..1 |
コード |
|
Key H: 階層レベル |
||||
| ID | H | 項目 | 繰返 | データ型 |
|---|---|---|---|---|
|
A01 |
0 |
ビジネスセグメント |
0..n |
集約 |
|
A01-03 |
1 |
•ビジネスセグメント参照レベル |
1..1 |
コード |
|
A01-01 |
1 |
•ビジネスセグメントコード |
1..1 |
コード |
|
A01-02 |
1 |
•ビジネスセグメントタイプ |
1..1 |
文字 |
|
A01-04 |
1 |
•組織タイプ |
0..1 |
文字 |
|
Key H: 階層レベル |
||||
— 列ヘッダーは 値 であり、変数名ではない。
— 複数の 変数 が 1 つの列に格納される。
— 変数 は行と列の両方に格納される。
— 複数の種類の 観測 が同じ表に格納される。
— 1 つの 観測 が複数の表に格納される。
Tidy Data Journal of Statistical Software August 2014 Volume 59 Issue 10
Tidy data
表に含まれる 変数 として 集約 を検出することから始めます。
これらの 集約 が、複数繰り返すと指定されている場合、観測 を報告するための 変数 が必要です。総勘定元帳には、複数の 集約、つまり、総勘定元帳、総勘定元帳明細、複数通貨金額、およびビジネスセグメントが含まれています。この例では、総勘定元帳が単一の通貨で記録されていて現地通貨は報告通貨でもあるので、多通貨金額の 変数 は不要です。
したがって、次の 3 つの 変数 が必要となります。
— d_A25 総勘定元帳
— d_A26 総勘定元帳明細行
— d_A01 ビジネスセグメント
次の表は、これらの3つの 変数 と項目に対応する 変数 を列ヘッダーと 観測 値の列として使用して定義しています。 3件の明細行に対応して d_A26 列に 1, 2, 3が指定されています。
| d_A25 | d_A26 | d_A01 | ID | 項目 | 値 |
|---|---|---|---|---|---|
|
943-8-477 |
A25-01 |
仕訳ID |
943-8-477 |
||
|
943-8-477 |
A25-A26-08 |
仕訳タイプコード |
entries |
||
|
943-8-477 |
A25-A26-07 |
仕訳明細行番号 |
8-477 |
||
|
943-8-477 |
A25-A26-14 |
書類日付 |
2009-04-03 |
||
|
943-8-477 |
A25-A26-12 |
書類番号 |
manual |
||
|
943-8-477 |
A25-A26-11 |
源コード |
gj |
||
|
943-8-477 |
A25-09 |
摘要 |
General |
||
|
943-8-477 |
A25-02 |
仕訳番号 |
134 |
||
|
943-8-477 |
1 |
A26-A09-01 |
勘定科目番号 |
754 |
|
|
943-8-477 |
1 |
A26-A09-02 |
勘定科目名 |
事務用消耗品費 |
|
|
943-8-477 |
1 |
A26-A09-05 |
勘定科目タイプ |
account |
|
|
943-8-477 |
1 |
A25-A26-27 |
貸借区分 |
debit |
|
|
943-8-477 |
1 |
A26-A89-01 |
金額 |
14858 |
|
|
943-8-477 |
1 |
A26-A89-02 |
通貨 |
ISO4217:JPY |
|
|
943-8-477 |
1 |
A25-A26-06 |
日付 |
2009-04-03 |
|
|
943-8-477 |
1 |
A26-A09-06 |
補助科目タイプ |
proposed |
|
|
943-8-477 |
1 |
A25-A26-10 |
明細行摘要 |
用紙 |
|
|
943-8-477 |
1 |
1 |
A26-A01-03 |
ビジネスセグメント参照レベル |
account sub |
|
943-8-477 |
1 |
1 |
A26-A01-01 |
ビジネスセグメントコード |
10 |
|
943-8-477 |
1 |
1 |
A26-A01-02 |
ビジネスセグメントタイプ |
札幌 |
|
943-8-477 |
1 |
1 |
A26-A01-04 |
組織タイプ |
部門 |
|
943-8-477 |
2 |
A26-A09-01 |
勘定科目番号 |
191 |
|
|
943-8-477 |
2 |
A26-A09-02 |
勘定科目名 |
仮払消費税等 |
|
|
943-8-477 |
2 |
A26-A09-05 |
勘定科目タイプ |
account |
|
|
943-8-477 |
2 |
A25-A26-27 |
貸借区分 |
debit |
|
|
943-8-477 |
2 |
A26-A89-01 |
金額 |
742 |
|
|
943-8-477 |
2 |
A26-A89-02 |
通貨 |
ISO4217:JPY |
|
|
943-8-477 |
2 |
A25-A26-06 |
日付 |
2009-04-03 |
|
|
943-8-477 |
2 |
A26-A09-06 |
補助科目タイプ |
tax |
|
|
943-8-477 |
2 |
1 |
A26-A01-03 |
ビジネスセグメント参照レベル |
account sub |
|
943-8-477 |
2 |
1 |
A26-A01-01 |
ビジネスセグメントコード |
10 |
|
943-8-477 |
2 |
1 |
A26-A01-02 |
ビジネスセグメントタイプ |
札幌 |
|
943-8-477 |
2 |
1 |
A26-A01-04 |
組織タイプ |
部門 |
|
943-8-477 |
3 |
A26-A09-01 |
勘定科目番号 |
111 |
|
|
943-8-477 |
3 |
A26-A09-02 |
勘定科目名 |
現金 Cash |
|
|
943-8-477 |
3 |
A26-A09-05 |
勘定科目タイプ |
account |
|
|
943-8-477 |
3 |
A25-A26-27 |
貸借区分 |
credit |
|
|
943-8-477 |
3 |
A26-A89-01 |
金額 |
15600 |
|
|
943-8-477 |
3 |
A26-A89-02 |
通貨 |
ISO4217:JPY |
|
|
943-8-477 |
3 |
A25-A26-06 |
日付 |
2009-04-03 |
|
|
943-8-477 |
3 |
A26-A09-06 |
補助科目タイプ |
proposed |
|
|
943-8-477 |
3 |
A25-A26-10 |
明細行摘要 |
用紙 |
|
|
943-8-477 |
3 |
1 |
A26-A01-03 |
ビジネスセグメント参照レベル |
account sub |
|
943-8-477 |
3 |
1 |
A26-A01-01 |
ビジネスセグメントコード |
0 |
|
943-8-477 |
3 |
1 |
A26-A01-02 |
ビジネスセグメントタイプ |
共通部門 |
|
943-8-477 |
3 |
1 |
A26-A01-04 |
組織タイプ |
部門 |
表 11 はほとんど整理されていますが、観測 値には異なるデータ型の値が混在しています。 データ型が異なる列(要素)の 観測 値です。 Tidy データは、変数 の列数を制限していないことに注意してください。 各要素の変数に対応する追加の列を提供しているTable 12が Tidy data (整頓されたデータ)です。
| d_A25 総勘定元帳 |
d_A26 総勘定元帳明細行 |
d_A01 ビジネスセグメント |
A25-01 仕訳ID |
A25-A26-08 タイプコード |
A25-A26-07 仕訳明細行番号 |
A25-A26-14 日付 |
A25-A26-12 入力元 |
A25-A26-11 情報源コード |
A25-09 摘要 |
A25-02 仕訳番号 |
A26-A09-01 勘定科目番号 |
A26-A09-02 勘定科目名 |
A26-A09-05 勘定科目タイプ |
A25-A26-27 貸借区分 |
A26-A89-01 金額 |
A26-A89-02 通貨 |
A25-A26-06 日付 |
A26-A09-06 補助科目タイプ |
A25-A26-10 明細行摘要 |
A26-A01-03 ビジネスセグメント参照レベル |
A26-A01-01 ビジネスセグメントコード |
A26-A01-02 ビジネスセグメントタイプ |
A26-A01-04 組織タイプ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
943-8-477 |
943-8-477 |
entries |
8-477 |
2009-04-03 |
manual |
gj |
General |
134 |
|||||||||||||||
|
943-8-477 |
1 |
754 |
事務用消耗品費 |
account |
debit |
14858 |
JPY |
2009-04-03 |
proposed |
用紙 |
|||||||||||||
|
943-8-477 |
1 |
1 |
account sub |
10 |
札幌 |
部門 |
|||||||||||||||||
|
943-8-477 |
2 |
191 |
仮払消費税等 |
account |
debit |
742 |
JPY |
2009-04-03 |
tax |
||||||||||||||
|
943-8-477 |
2 |
1 |
account sub |
10 |
札幌 |
部門 |
|||||||||||||||||
|
943-8-477 |
3 |
111 |
現金 |
account |
credit |
15600 |
JPY |
2009-04-03 |
proposed |
用紙 |
|||||||||||||
|
943-8-477 |
3 |
1 |
account sub |
0 |
共通部門 |
部門 |
xBRL taxonomy and xBRL-CSV
xBRL taxonomy
図 1 の左側には、単純な数値データ「1234」がある。 そのデータは、受信者がそのコンテキストと目的を既に理解している場合にのみ、受信者に情報を中継できる。 ここでは、そのデータをファクトと呼ぶ。 精度、報告単位(尺度)、単位、およびその他の同様の情報の層を定義することで、ファクトに意味を追加できる。 コンテキストの意味は、時間や場所などの情報を含む別の層を介して提供することもできる。
事実は概念情報として識別できる。 データを表すために使用される標準のセマンティック要素に応じて、この概念情報は非常に詳細であり、豊富な追加の意味が含まれる場合がある。 前述のように、構造化データ標準は、そのデータを解釈するための有用され事前定義された方法を提供する意味のあるコンテキストの層を追加することにより、この方法でデータを表す定義済みのシステムを提供する。 XBRL はそのような標準の 1 つである。
XBRL Taxonomy Development Handbook A Guide for XBRL Taxonomy
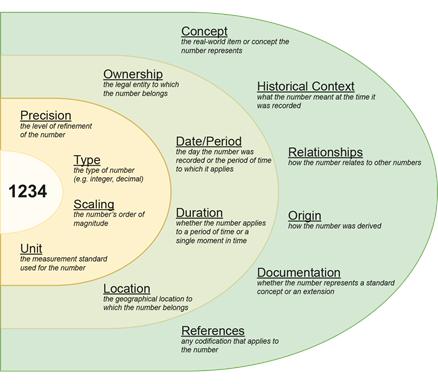
XBRL では、fact は、XBRL の dimension と data point の組み合わせ一意に定義される。 図 2 は、fact の基本構造を示す。 数字や名前、短い文書などの任意の情報にはそれ自体に意味情報や文脈情報はない。 セマンティックな情報を追加する XBRL dimension がその data point と交差すると、XBRL fact になる。
.A data point versus an XBRL fact
image::https://xbrlus.github.io/docs/images/thd_v10_007.jpg[]
XBRL Taxonomy Development Handbook A Guide for XBRL Taxonomy
Table 13 shows the relationship between Tidy data terms and xBRL terms.
.Relation among Tidy data and xBRL
| Tidy data | xBRL |
|---|---|
|
value |
fact |
|
variable |
dimension |
|
observation |
data point |
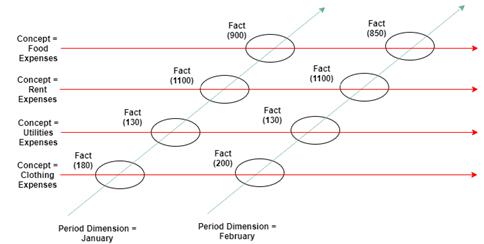
概念は、図 3 の費目 (食費、家賃、光熱費など) になる。 期間は列 (1 月、2 月など) で表される。 ここでも、概念の次元と期間の次元が交差する各箇所がfact(事実) (この場合、セルの金額) であり、費目概念と期間などの他の次元によって提供されるコンテキスト情報を組み合わせて XBRLの事実の次元を定義している。
XBRL Taxonomy Development Handbook A Guide for XBRL Taxonomy
xBRL-CSV
xBRL-CSV[_2]はこの形式のTidy data(整頓されたデータ)をサポートしています。
PCA会計9V.2の仕訳データをXBRL-GL (XBRL 2.0a) に変換して出力したもので、架空の企業の1年間の記帳データ(2829件 31MB)
例 xbrlgl/instances/0001-20091231-145-2109-1-4679.xml
XBRL-GLの記事ページは、 こちら です。
xBRL-CSVデータ adc-instances2-facts.csv (18MB)
xBRL-CSV定義 adc-instances2-metadata.json (1.1KB)
xBRL-CSVデータ adc-instances.csv (2.4MB) 1/12以上容量削減
xBRL-CSV定義 adc-instances.json (4.6KB)
Schema core.xsd
Definition Linkbase core-def.xml
Presentation Linkbase core-pre.xml
Label Linkbase core-label-en.xml
参考資料
[1] Tidy Data, Journal of Statistical Software, August 2014, Volume 59, Issue 10, Headley Wickham
https://www.jstatsoft.org/article/view/v059i10
[2] xBRL-CSV: CSV representation of XBRL data 1.0, Recommendation 13 October 2021
https://www.xbrl.org/Specification/xbrl-csv/REC-2021-10-13/xbrl-csv-REC-2021-10-13.html
[3] XBRL Taxonomy Development Handbook A Guide for XBRL Taxonomy, Developers First Edition (July 2020), XBRL US
https://xbrlus.github.io/docs/tdh.html#a_Toc45794887

