
Views: 2
“デジタル会計帳簿の Tidy data (整然としたデータ)アプローチ” で紹介したTidy dataを使用するとXMLと互換性のあるCSVファイルが作成可能です。
今回は、UBL 2.1のXML文書をTidy data形式のCSVファイルと相互変換するPythonプログラムも紹介します。
使用している自作ライブラリについては、”JP PINT 0.9.3 スキーマトロンファイルの解析プログラム” の”XMLとPython dictのデータ変換ライブラリ”をお読みください。dic2etreeライブラリは、 stackoverflow converting xml to dictionary using elementtree を参考に作成しました。
CSVは、Tidy data表現を使用すると構造を含めたデータを一枚のシートで表現することができます。
リレーショナルデータベースのテーブルの形式にとらわれないTidy data形式は、すべてのデータをメモリ上で処理する際にも効果的な形式です。
JP PINT 0.9.3からダウンロードしたデジタルインボイスのTidy data表現
JP PINT 0.9.3のDownload resourcesに含まれているデジタルインボイスの例をTidy data形式にしたものをExample.xlsxにまとめました。
今回紹介するJapan PINT Invoice UBL Example1-minimum.xmlは、UBL 2.1のデジタルインボイスです。
が、よく見ると記載された金額に誤りがあります。エラー箇所については最後に紹介しています。
<?xml version="1.0" encoding="UTF-8"?>
<Invoice xmlns="urn:oasis:names:specification:ubl:schema:xsd:Invoice-2"
xmlns:cac="urn:oasis:names:specification:ubl:schema:xsd:CommonAggregateComponents-2"
xmlns:cbc="urn:oasis:names:specification:ubl:schema:xsd:CommonBasicComponents-2"
xmlns:ccts="urn:un:unece:uncefact:documentation:2"
xmlns:ext="urn:oasis:names:specification:ubl:schema:xsd:CommonExtensionComponents-2"
xmlns:qdt="urn:oasis:names:specification:ubl:schema:xsd:QualifiedDatatypes-2"
xmlns:udt="urn:un:unece:uncefact:data:specification:UnqualifiedDataTypesSchemaModule:2"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="urn:oasis:names:specification:ubl:schema:xsd:Invoice-2
http://docs.oasis-open.org/ubl/os-UBL-2.1/xsd/maindoc/UBL-Invoice-2.1.xsd">
<!-- Japan common commercial invoice, example1-minimum -->
<cbc:UBLVersionID>2.1</cbc:UBLVersionID>
<cbc:CustomizationID>urn:fdc:peppol:jp:billing:3.0</cbc:CustomizationID> <!--IBT-024 - Specification identifier -->
<cbc:ProfileID>urn:fdc:peppol.eu:2017:poacc:billing:01:1.0</cbc:ProfileID> <!--IBT-023 - Business process type -->
<cbc:ID>156</cbc:ID> <!--IBT-001 - Invoice number -->
<cbc:IssueDate>2023-10-24</cbc:IssueDate> <!--IBT-002 - Invoice issue date -->
<cbc:InvoiceTypeCode>380</cbc:InvoiceTypeCode> <!--IBT-003 - Invoice type code -->
<cbc:DocumentCurrencyCode>JPY</cbc:DocumentCurrencyCode> <!--IBT-005 - Invoice currency code -->
<cac:InvoicePeriod> <!--IBG-14 - INVOICING PERIOD -->
<cbc:StartDate>2023-10-18</cbc:StartDate> <!--IBT-073 - Invoicing period start date -->
<cbc:EndDate>2023-10-18</cbc:EndDate> <!--IBT-074 - Invoicing period end date -->
</cac:InvoicePeriod>
<cac:AccountingSupplierParty> <!--IBG-04 - SELLER -->
<cac:Party>
<cbc:EndpointID schemeID="0188">1234567890123</cbc:EndpointID> <!--IBT-034 - Seller electronic address, IBT-034-1 - Scheme identifier -->
<cac:PostalAddress> <!--IBG-05 - SELLER POSTAL ADDRESS -->
<cac:Country>
<cbc:IdentificationCode>JP</cbc:IdentificationCode> <!--IBT-040 - Seller country code -->
</cac:Country>
</cac:PostalAddress>
<cac:PartyTaxScheme>
<cbc:CompanyID>T1234567890123</cbc:CompanyID> <!--IBT-031 - Seller TAX identifier -->
<cac:TaxScheme>
<cbc:ID>VAT</cbc:ID> <!--IBT-031, qualifier -->
</cac:TaxScheme>
</cac:PartyTaxScheme>
<cac:PartyLegalEntity>
<cbc:RegistrationName>株式会社 〇〇商事</cbc:RegistrationName> <!--IBT-027 - Seller name -->
</cac:PartyLegalEntity>
</cac:Party>
</cac:AccountingSupplierParty>
<cac:AccountingCustomerParty> <!--IBG-07 - BUYER -->
<cac:Party>
<cbc:EndpointID schemeID="0188">3210987654321</cbc:EndpointID> <!--IBT-049 - Buyer electronic address, IBT-049-1 - Scheme identifier -->
<cac:PostalAddress> <!--IBG-08 - BUYER POSTAL ADDRESS -->
<cac:Country>
<cbc:IdentificationCode>JP</cbc:IdentificationCode> <!--IBT-055 - Buyer country code -->
</cac:Country>
</cac:PostalAddress>
<cac:PartyLegalEntity>
<cbc:RegistrationName>株式会社 〇〇物産</cbc:RegistrationName> <!--IBT-044 - Buyer name -->
</cac:PartyLegalEntity>
</cac:Party>
</cac:AccountingCustomerParty>
<cac:TaxTotal>
<cbc:TaxAmount currencyID="JPY"> <!--26000-->20000</cbc:TaxAmount> <!--IBT-110 - Invoice total TAX amount -->
<cac:TaxSubtotal> <!--IBG-23 - TAX BREAKDOWN -->
<cbc:TaxableAmount currencyID="JPY"> <!--260000-->200000</cbc:TaxableAmount> <!--IBT-116 - TAX category taxable amount -->
<cbc:TaxAmount currencyID="JPY"> <!--26000-->20000</cbc:TaxAmount> <!--IBT-117 - TAX category tax amount -->
<cac:TaxCategory>
<cbc:ID>S</cbc:ID> <!--IBT-118 - TAX category code -->
<cbc:Percent>10</cbc:Percent> <!--IBT-119 - TAX category rate -->
<cac:TaxScheme>
<cbc:ID>VAT</cbc:ID> <!--IBT-118, qualifier -->
</cac:TaxScheme>
</cac:TaxCategory>
</cac:TaxSubtotal>
<cac:TaxSubtotal> <!--IBG-23 - TAX BREAKDOWN -->
<cbc:TaxableAmount currencyID="JPY">3490</cbc:TaxableAmount> <!--IBT-116 - TAX category taxable amount -->
<cbc:TaxAmount currencyID="JPY">0</cbc:TaxAmount> <!--IBT-117 - TAX category tax amount -->
<cac:TaxCategory>
<cbc:ID>E</cbc:ID> <!--IBT-118 - TAX category code -->
<cbc:Percent>0</cbc:Percent> <!--IBT-119 - TAX category rate -->
<cac:TaxScheme>
<cbc:ID>VAT</cbc:ID> <!--IBT-118, qualifier -->
</cac:TaxScheme>
</cac:TaxCategory>
</cac:TaxSubtotal>
</cac:TaxTotal>
<cac:LegalMonetaryTotal> <!--IBG-22 - DOCUMENT TOTALS -->
<cbc:LineExtensionAmount currencyID="JPY">255990</cbc:LineExtensionAmount> <!--IBT-106 - Sum of Invoice line net amount -->
<cbc:TaxExclusiveAmount currencyID="JPY">255990</cbc:TaxExclusiveAmount> <!--IBT-109 - Invoice total amount without TAX -->
<cbc:TaxInclusiveAmount currencyID="JPY">281990</cbc:TaxInclusiveAmount> <!--IBT-112 - Invoice total amount with TAX -->
<cbc:AllowanceTotalAmount currencyID="JPY">0</cbc:AllowanceTotalAmount> <!--IBT-107 - Sum of allowances on document level -->
<cbc:ChargeTotalAmount currencyID="JPY">0</cbc:ChargeTotalAmount> <!--IBT-108 - Sum of charges on document level -->
<cbc:PrepaidAmount currencyID="JPY">0</cbc:PrepaidAmount> <!--IBT-113 - Paid amount -->
<cbc:PayableRoundingAmount currencyID="JPY">0</cbc:PayableRoundingAmount> <!--IBT-114 - Rounding amount -->
<cbc:PayableAmount currencyID="JPY">281990</cbc:PayableAmount> <!--IBT-115 - Amount due for payment -->
</cac:LegalMonetaryTotal>
<cac:InvoiceLine> <!--IBG-25 - INVOICE LINE -->
<cbc:ID>1</cbc:ID> <!--IBT-126 - Invoice line identifier -->
<cbc:InvoicedQuantity unitCode="H87">5</cbc:InvoicedQuantity> <!--IBT-129 - Invoiced quantity, IBT-130 - Invoiced quantity unit of measure code -->
<cbc:LineExtensionAmount currencyID="JPY">250000</cbc:LineExtensionAmount> <!--IBT-131 - Invoice line net amount -->
<cac:InvoicePeriod> <!--IBG-26 - INVOICE LINE PERIOD -->
<cbc:StartDate>2023-10-18</cbc:StartDate> <!--IBT-134 - Invoice line period start date -->
<cbc:EndDate>2023-10-18</cbc:EndDate> <!--IBT-135 - Invoice line period end date -->
</cac:InvoicePeriod>
<cac:Item> <!--IBG-31 - ITEM INFORMATION -->
<cbc:Name>デスクチェア</cbc:Name> <!--IBT-153 - Item name -->
<cac:ClassifiedTaxCategory> <!--IBG-30 - LINE TAX INFORMATION -->
<cbc:ID>S</cbc:ID> <!--IBT-151 - Invoiced item TAX category code -->
<cbc:Percent>10</cbc:Percent> <!--IBT-152 - Invoiced item TAX rate -->
<cac:TaxScheme>
<cbc:ID>VAT</cbc:ID> <!--IBT-167 - Tax Scheme -->
</cac:TaxScheme>
</cac:ClassifiedTaxCategory>
</cac:Item>
<cac:Price> <!--IBG-29 - PRICE DETAILS -->
<cbc:PriceAmount currencyID="JPY">50000</cbc:PriceAmount> <!--IBT-146 - Item net price -->
<cbc:BaseQuantity unitCode="H87">1</cbc:BaseQuantity> <!--IBT-149 - Item price base quantity, IBT-150 - Item price base quantity unit of measure code -->
</cac:Price>
</cac:InvoiceLine>
<cac:InvoiceLine> <!--IBG-25 - INVOICE LINE -->
<cbc:ID>2</cbc:ID> <!--IBT-126 - Invoice line identifier -->
<cbc:InvoicedQuantity unitCode="H87">5</cbc:InvoicedQuantity> <!--IBT-130 - Invoiced quantity unit of measure code, IBT-129 - Invoiced quantity -->
<cbc:LineExtensionAmount currencyID="JPY">2500</cbc:LineExtensionAmount> <!--IBT-131 - Invoice line net amount -->
<cac:InvoicePeriod> <!--IBG-26 - INVOICE LINE PERIOD -->
<cbc:StartDate>2023-10-18</cbc:StartDate> <!--IBT-134 - Invoice line period start date -->
<cbc:EndDate>2023-10-18</cbc:EndDate> <!--IBT-135 - Invoice line period end date -->
</cac:InvoicePeriod>
<cac:Item> <!--IBG-31 - ITEM INFORMATION -->
<cbc:Name>コピー用紙(A4)</cbc:Name> <!--IBT-153 - Item name -->
<cac:ClassifiedTaxCategory> <!--IBG-30 - LINE TAX INFORMATION -->
<cbc:ID>S</cbc:ID> <!--IBT-151 - Invoiced item TAX category code -->
<cbc:Percent>10</cbc:Percent> <!--IBT-152 - Invoiced item TAX rate -->
<cac:TaxScheme>
<cbc:ID>VAT</cbc:ID> <!--IBT-167 - Tax Scheme -->
</cac:TaxScheme>
</cac:ClassifiedTaxCategory> <!--IBG-32 - ITEM ATTRIBUTES -->
</cac:Item>
<cac:Price> <!--IBG-29 - PRICE DETAILS -->
<cbc:PriceAmount currencyID="JPY">500</cbc:PriceAmount> <!--IBT-146 - Item net price -->
<cbc:BaseQuantity unitCode="H87">1</cbc:BaseQuantity> <!--IBT-149 - Item price base quantity, IBT-150 - Item price base quantity unit of measure code -->
</cac:Price>
</cac:InvoiceLine>
<cac:InvoiceLine> <!--IBG-25 - INVOICE LINE -->
<cbc:ID>3</cbc:ID> <!--IBT-126 - Invoice line identifier -->
<cbc:InvoicedQuantity unitCode="H87">10</cbc:InvoicedQuantity> <!--IBT-130 - Invoiced quantity unit of measure code, IBT-129 - Invoiced quantity -->
<cbc:LineExtensionAmount currencyID="JPY">3490</cbc:LineExtensionAmount> <!--IBT-131 - Invoice line net amount -->
<cac:InvoicePeriod> <!--IBG-26 - INVOICE LINE PERIOD -->
<cbc:StartDate>2023-10-18</cbc:StartDate> <!--IBT-134 - Invoice line period start date -->
<cbc:EndDate>2023-10-18</cbc:EndDate> <!--IBT-135 - Invoice line period end date -->
</cac:InvoicePeriod>
<cac:Item> <!--IBG-31 - ITEM INFORMATION -->
<cbc:Name>検定済教科書(算数)</cbc:Name> <!--IBT-153 - Item name -->
<cac:ClassifiedTaxCategory> <!--IBG-30 - LINE TAX INFORMATION -->
<cbc:ID>E</cbc:ID> <!--IBT-151 - Invoiced item TAX category code -->
<cbc:Percent>0</cbc:Percent> <!--IBT-152 - Invoiced item TAX rate -->
<cac:TaxScheme>
<cbc:ID>VAT</cbc:ID> <!--IBT-167 - Tax Scheme -->
</cac:TaxScheme>
</cac:ClassifiedTaxCategory>
</cac:Item>
<cac:Price> <!--IBG-29 - PRICE DETAILS -->
<cbc:PriceAmount currencyID="JPY">349</cbc:PriceAmount> <!--IBT-146 - Item net price -->
<cbc:BaseQuantity unitCode="H87">1</cbc:BaseQuantity> <!--IBT-149 - Item price base quantity, IBT-150 - Item price base quantity unit of measure code -->
</cac:Price>
</cac:InvoiceLine>
</Invoice>
このUBL2.1で定義されたXML文書に対応したTidy data形式の表を次に示します。

|
G00 |
G23 |
G25 |
ibt-001 |
ibt-002 |
ibt-003 |
ibt-005 |
ibt-023 |
ibt-024 |
ibt-027 |
ibt-031 |
ibt-034 |
ibt-034-1 |
ibt-040 |
ibt-044 |
ibt-049 |
ibt-049-1 |
ibt-055 |
ibt-073 |
ibt-074 |
ibt-106 |
ibt-107 |
ibt-108 |
ibt-109 |
ibt-110 |
ibt-112 |
ibt-113 |
ibt-114 |
ibt-115 |
ibt-116 |
ibt-117 |
ibt-118 |
ibt-119 |
ibt-126 |
ibt-129 |
ibt-130 |
ibt-131 |
ibt-134 |
ibt-135 |
ibt-146 |
ibt-149 |
ibt-150 |
ibt-151 |
ibt-152 |
ibt-167 |
ibt-153 |
|
156 |
156 |
2023-10-24 |
380 |
JPY |
urn:fdc:peppol.eu:2017:poacc:billing:01:1.0 |
urn:fdc:peppol:jp:billing:3.0 |
株式会社 〇〇商事 |
T1234567890123 |
1234567890123 |
0188 |
JP |
株式会社 〇〇物産 |
3210987654321 |
0188 |
JP |
2023-10-18 |
2023-10-18 |
255990 |
0 |
0 |
255990 |
20000 |
281990 |
0 |
0 |
281990 |
|||||||||||||||||||
|
156 |
S10 |
200000 |
20000 |
S |
10 |
||||||||||||||||||||||||||||||||||||||||
|
156 |
E0 |
3490 |
0 |
E |
0 |
||||||||||||||||||||||||||||||||||||||||
|
156 |
1 |
1 |
5 |
H87 |
250000 |
2023-10-18 |
2023-10-18 |
50000 |
1 |
H87 |
S |
10 |
VAT |
デスクチェア |
|||||||||||||||||||||||||||||||
|
156 |
2 |
2 |
5 |
H87 |
2500 |
2023-10-18 |
2023-10-18 |
500 |
1 |
H87 |
S |
10 |
VAT |
コピー用紙(A4) |
|||||||||||||||||||||||||||||||
|
156 |
3 |
3 |
10 |
H87 |
3490 |
2023-10-18 |
2023-10-18 |
349 |
1 |
H87 |
E |
0 |
VAT |
検定済教科書(算数) |
G00は、インボイスに対応しておりインボイス番号156を記載しています。
G23は、TAX BREAKDOWNに対応して標準税率(S)の10%をS10、非課税(E)の0%をE0と区別できるように記載しています。
G25には、明細行の番号が1,2,3と記載されています。それ以降の欄には、項目に対応する値を記載しています。
目視確認のために、縦と横を転置した表を次にしまします。
こちらのほうが人には分かりやすいと思いますが、コンピュータ処理には上のTidy data形式が最適です。
この他のDownload resourcesに含まれているデジタルインボイスの例も併せてExample.xlsxにまとめましたのでご確認ください。
|
ibg-23 |
ibg-23 |
ibg-25 |
ibg-25 |
ibg-25 |
|||||
|
TAX BREAKDOWN |
TAX BREAKDOWN |
INVOICE LINE |
INVOICE LINE |
INVOICE LINE |
|||||
|
0 |
1 |
0 |
1 |
2 |
|||||
|
ibt-001 |
1 |
1..1 |
Invoice number |
156 |
|||||
|
ibt-002 |
1 |
1..1 |
Invoice issue date |
2023-10-24 |
|||||
|
ibt-003 |
1 |
1..1 |
Invoice type code |
380 |
|||||
|
ibt-005 |
1 |
1..1 |
Invoice currency code |
JPY |
|||||
|
ibt-023 |
2 |
1..1 |
Business process type |
urn:fdc:peppol.eu:2017:poacc:billing:01:1.0 |
|||||
|
ibt-024 |
2 |
1..1 |
Specification identifier |
urn:fdc:peppol:jp:billing:3.0 |
|||||
|
ibg-04 |
1 |
1..1 |
SELLER |
||||||
|
ibt-027 |
2 |
1..1 |
Seller name |
株式会社 〇〇商事 |
|||||
|
ibt-031 |
2 |
0..1 |
Seller TAX identifier |
T1234567890123 |
|||||
|
ibt-034 |
2 |
1..1 |
Seller electronic address |
1234567890123 |
|||||
|
ibt-034-1 |
3 |
1..1 |
Scheme identifier |
0188 |
|||||
|
ibg-05 |
2 |
1..1 |
SELLER POSTAL ADDRESS |
||||||
|
ibt-040 |
3 |
1..1 |
Seller country code |
JP |
|||||
|
ibg-07 |
1 |
1..1 |
BUYER |
||||||
|
ibt-044 |
2 |
1..1 |
Buyer name |
株式会社 〇〇物産 |
|||||
|
ibt-049 |
2 |
1..1 |
Buyer electronic address |
3210987654321 |
|||||
|
ibt-049-1 |
3 |
1..1 |
Scheme identifier |
0188 |
|||||
|
ibg-08 |
2 |
1..1 |
BUYER POSTAL ADDRESS |
||||||
|
ibt-055 |
3 |
1..1 |
Buyer country code |
JP |
|||||
|
ibg-13 |
1 |
0..1 |
DELIVERY INFORMATION |
||||||
|
ibg-14 |
2 |
0..1 |
INVOICING PERIOD |
||||||
|
ibt-073 |
3 |
0..1 |
Invoicing period start date |
2023-10-18 |
|||||
|
ibt-074 |
3 |
0..1 |
Invoicing period end date |
2023-10-18 |
|||||
|
ibg-22 |
1 |
1..1 |
DOCUMENT TOTALS |
||||||
|
ibt-106 |
2 |
1..1 |
Sum of Invoice line net amount |
255990 |
|||||
|
ibt-107 |
2 |
0..1 |
Sum of allowances on document level |
0 |
|||||
|
ibt-108 |
2 |
0..1 |
Sum of charges on document level |
0 |
|||||
|
ibt-109 |
2 |
1..1 |
Invoice total amount without TAX |
255990 |
|||||
|
ibt-110 |
2 |
1..1 |
Invoice total TAX amount |
20000 |
|||||
|
ibt-112 |
2 |
1..1 |
Invoice total amount with TAX |
281990 |
|||||
|
ibt-113 |
2 |
0..1 |
Paid amount |
0 |
|||||
|
ibt-114 |
2 |
0..1 |
Rounding amount |
0 |
|||||
|
ibt-115 |
2 |
1..1 |
Amount due for payment |
281990 |
|||||
|
ibg-23 |
1 |
1..n |
TAX BREAKDOWN |
||||||
|
ibt-116 |
2 |
1..1 |
TAX category taxable amount |
200000 |
3490 |
||||
|
ibt-117 |
2 |
1..1 |
TAX category tax amount |
20000 |
0 |
||||
|
ibt-118 |
2 |
1..1 |
TAX category code |
S |
E |
||||
|
ibt-119 |
2 |
0..1 |
TAX category rate |
10 |
0 |
||||
|
ibg-25 |
1 |
1..n |
INVOICE LINE |
||||||
|
ibt-126 |
2 |
1..1 |
Invoice line identifier |
1 |
2 |
3 |
|||
|
ibt-129 |
2 |
1..1 |
Invoiced quantity |
5 |
5 |
10 |
|||
|
ibt-130 |
2 |
1..1 |
Invoiced quantity unit of measure code |
H87 |
H87 |
H87 |
|||
|
ibt-131 |
2 |
1..1 |
Invoice line net amount |
250000 |
2500 |
3490 |
|||
|
ibg-26 |
2 |
0..1 |
INVOICE LINE PERIOD |
||||||
|
ibt-134 |
3 |
0..1 |
Invoice line period start date |
2023-10-18 |
2023-10-18 |
2023-10-18 |
|||
|
ibt-135 |
3 |
0..1 |
Invoice line period end date |
2023-10-18 |
2023-10-18 |
2023-10-18 |
|||
|
ibg-29 |
2 |
1..1 |
PRICE DETAILS |
||||||
|
ibt-146 |
3 |
1..1 |
Item net price |
50000 |
500 |
349 |
|||
|
ibt-149 |
3 |
0..1 |
Item price base quantity |
1 |
1 |
1 |
|||
|
ibt-150 |
3 |
0..1 |
Item price base quantity unit of measure code |
H87 |
H87 |
H87 |
|||
|
ibg-30 |
2 |
1..n |
LINE TAX INFORMATION |
||||||
|
ibt-151 |
3 |
1..1 |
Invoiced item TAX category code |
S |
S |
E |
|||
|
ibt-152 |
3 |
0..1 |
Invoiced item TAX rate |
10 |
10 |
0 |
|||
|
ibt-167 |
3 |
0..1 |
Tax Scheme |
VAT |
VAT |
VAT |
|||
|
ibg-31 |
2 |
1..1 |
ITEM INFORMATION |
||||||
|
ibt-153 |
3 |
1..1 |
Item name |
デスクチェア |
コピー用紙(A4) |
検定済教科書(算数) |
デジタルインボイスXML文書からTidy data形式のCSVを生成するプログラム
プログラムの処理の流れは、次の順序です。
1. JP PINT 0.9.3の定義表(Excel)からPINT変換辞書データを作成しておく。
2. Element Treeライブラリを使用してXML文書を読み込み、Element Treeデータ形式に展開する。
3. PINT変換辞書データをSemanticソート番号順に読み込み、項目ごとに定義されたXPathを使ってElement Treeの関数を使用して該当データの値を取得する。
4. データの値をTidy data形式のPythonの辞書データに登録する。
5. Tidy data形式のPythonの辞書データを転置形式のCSVとして出力する。
6. Tidy data形式のPythonの辞書データをxBRL-GD定義のメタデータファイル(JSON)およびCSVデータファイルに出力する。
#!/usr/bin/env python3
#coding: utf-8
#
# generate CSV and OIM-CSV from Open Peoopl e-Invoice (UBL 2.1)
#
# designed by SAMBUICHI, Nobuyuki (Sambuichi Professional Engineers Office)
# written by SAMBUICHI, Nobuyuki (Sambuichi Professional Engineers Office)
#
# MIT License
#
# (c) 2021-2022 SAMBUICHI Nobuyuki (Sambuichi Professional Engineers Office)
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
from termios import VERASE
import xml.etree.ElementTree as ET
import csv
import re
import sys
import json
import os
import argparse
import collections
from dic2etree import *
DEBUG = None
ET.register_namespace('', ns[''])
ET.register_namespace('xsd', ns['xsd'])
ET.register_namespace('xsi', ns['xsi'])
ET.register_namespace('cac', ns['cac'])
ET.register_namespace('cbc', ns['cbc'])
ET.register_namespace('qdt', ns['qdt'])
ET.register_namespace('udt', ns['udt'])
ET.register_namespace('ccts', ns['ccts'])
ET.register_namespace('cn', ns['cn'])
ET.register_namespace('ubl', ns['ubl'])
SEP = os.sep
invoiceNumber = ''
DocumentCurrencyCode = ''
TaxCurrencyCode = ''
SupplierTaxScheme = ''
pintList = []
pintDict = {}
pintSemSort = {}
pintMap = {}
root = None
bough0 = {'level': 0, 'id': 'ibg-00', 'count': ''}
boughs = {}
boughs[0] = [bough0]
def file_path(pathname):
if '/' == pathname[0:1]:
return pathname
else:
dir = os.path.dirname(__file__)
new_path = os.path.join(dir, pathname)
return new_path
def formatXPath(xpath):
global id
if '[not(@schemeID="SEPA")]' in xpath: # ETree doesn't supprt 'not'. Assume we don't use SEPA in Japan
xpath = xpath.replace('[not(@schemeID="SEPA")]','')
if re.match(r'.*\[cac:TaxScheme/cbc:ID.*\]', xpath):
xpath = re.sub(r'\[cac:TaxScheme/cbc:ID[ ]*=[ ]*(.*)\]','/cac:TaxScheme[cbc:ID=\\1]/..', xpath)
xpath = re.sub(r'\[cac:TaxScheme/cbc:ID[ ]*!=[ ]*(.*)\]','/cac:TaxScheme[cbc:ID!=\\1]/..', xpath)
# if VERBOSE: print(f'formatXPath xpath={xpath}')
if re.match(r'.*\[cbc:TaxAmount/@currencyID', xpath):
xpath = re.sub(r'\[cbc:TaxAmount/@currencyID[ ]*=[ ]*(.*)\]','/cbc:TaxAmount[@currencyID=\\1]/..', xpath)
xpath = re.sub(r'/Invoice/cbc:DocumentCurrencyCode(/text\(\))?','"'+DocumentCurrencyCode+'"', xpath)
if TaxCurrencyCode and re.match(r'.*/Invoice/cbc:TaxCurrencyCode(/text\(\))?', xpath):
xpath = re.sub(r'/Invoice/cbc:TaxCurrencyCode(/text\(\))?','"'+TaxCurrencyCode+'"', xpath)
xpath = re.sub(r'/Invoice', '/{'+ns['ubl']+'}Invoice', xpath)
xpath = re.sub(r'cac:', '{'+ns['cac']+'}', xpath)
xpath = re.sub(r'cbc:', '{'+ns['cbc']+'}', xpath)
if re.match(r'^.*/@[a-zA-Z]*$', xpath):
path = re.sub(r'(.*)/@.*$', '\\1', xpath)
attr = re.sub(r'.*/@(.*)$', '\\1', xpath)
xpath = [path, attr]
else:
xpath = re.sub(r'false\(\)', "'false'", xpath)
xpath = re.sub(r'true\(\)', "'true'", xpath)
# if DEBUG: print(f'{getframeinfo(currentframe()).lineno:03d}: xpath={xpath}')
return xpath
def updateBough(i, count):
global rows
global boughs
global n
data = pintList[i]
if '1'==data['card'][-1:]:
return
id = data['id']
BT = data['BT']
level = boughLevel[id]
# if DEBUG:
# print(f'{getframeinfo(currentframe()).lineno:03d}: n={n:02d} i={i:03d} updateBough rows[{n}] {id} {rows[n]["0001"]}({rows[n]["0000"]})\n boughs[{n}] {boughs[n]}')
n = len(rows) - 1
bough = boughs[n]
bough_id = bough[-1:][0]['id']
parentList = parents[id] # [1:]
if parentList and len(parentList) > 0:
if '-' == id[-2:-1]:
parent_id = parentList[1:2][0]
parent_BT = [v['BT'] for v in list(pintList) if parent_id == v['id']][0]
else:
parent_id = id
parent_BT = BT
else:
parent_id = id
parent_BT = BT
if id in L1multipleBG or 'ibg-38' == id or n > 0:
n = n + 1
if n > 0:
idx = n - 1
else:
idx = 0
_boughs = boughs[idx]
if 0 == len(parentList):
_boughs = _boughs[:1]
elif level < len(_boughs):
_boughs = _boughs[:level]
boughs[n] = _boughs + [{'level': len(_boughs), 'id': parent_id, 'count': count}]
rows[n] = {'0000': parent_id, '0001': parent_BT}
# if DEBUG:
# print(f'{getframeinfo(currentframe()).lineno:03d}: n={n:02d} i={i:03d} updateBough {id} rows[{n}] {rows[n]["0001"]}({rows[n]["0000"]}) boughs[{n}] {boughs[n]}')
def getAttribute(xpath,element):
text = None
if xpath[1]:
attrib = xpath[1]
if attrib and attrib in element.attrib:
text = element.attrib[attrib]
return text
def fillData(parent, parentXPath, i, count):
global n
global id
global boughs
if None == parent:
parent = root
data = pintList[i]
semSort = data['semSort']
id = data['id']
level = data['level']
BT = data['BT']
xpath = data['xpath']
if not xpath or len(xpath) < 9:
return
xpath = xpath[9:]
xpath = formatXPath(xpath)
text = None
try:
if isinstance(xpath, list): # xpath contains attribute
element = None
text = None
if parentXPath:
_xpath = xpath[0].replace(parentXPath+'/', '')
else:
_xpath = xpath[0]
if re.match(r'^.*\[not\(.*\)\]', _xpath):
# e.g. .*[not({urn:oasis:names:specification:ubl:schema:xsd:CommonBasicComponents-2}DocumentTypeCode='130')]
xpath_ = re.sub(r'^(.*)\[not\(.*\)\]', r'\1', _xpath)
__xpath = re.sub(r'^(.*)\[not\((.*)\)\]', r'\1[\2]', _xpath)
if parentXPath:
elements_ = parent.findall(xpath_)
else:
elements_ = root.findall(xpath_)
if len(elements_) > 0:
_elements = root.findall(__xpath)
elements = list(set(elements_) - set(_elements))
if len(elements) > 0:
element = elements[0]
text = getAttribute(xpath,element)
else:
element = parent.find(_xpath)
if not None == element and element.tag:
text = getAttribute(xpath,element)
else:
if re.match(r'^.*\[not\(.*\)\]', xpath): # and re.match(r''):
element = None
text = None
# e.g. .*[not({urn:oasis:names:specification:ubl:schema:xsd:CommonBasicComponents-2}DocumentTypeCode='130')]
xpath = formatXPath(xpath)
if parentXPath:
_xpath = xpath.replace(parentXPath, '')[1:]
else:
_xpath = xpath
xpath_ = re.sub(r'^(.*)\[not\(.*\)\]', r'\1', _xpath)
__xpath = re.sub(r'^(.*)\[not\((.*)\)\]', r'\1[\2]', _xpath)
if parentXPath:
elements_ = parent.findall(xpath_)
else:
elements_ = root.findall(xpath_)
if len(elements_) > 0:
_elements = root.findall(__xpath)
elements = list(set(elements_)-set(_elements))
if len(elements) > 0:
text = elements[0].text
else:
if parentXPath and not 'TaxTotal' in xpath:
_xpath = xpath.replace(parentXPath+'/', '')
else:
_xpath = xpath
if 'TaxTotal' in _xpath and not 'TaxSubtotal' in _xpath:
text = root.findtext(_xpath)
elif 'TaxSubtotal' in _xpath:
_xpath = xpath.replace(parentXPath+'/', '')
text = parent.findtext(_xpath)
if not text:
text = root.findtext(parentXPath+'['+str(n)+']/'+_xpath)
else:
text = parent.findtext(_xpath)
except SyntaxError:
print(f'-- SyntaxError {_xpath}')
if text:
if re.match(r'ibg-', id):
text = ''
text = text.strip().replace('\n', '\\n')
rows[n][semSort] = {'id': id, 'level': level, 'BT': BT, 'text': text}
if DEBUG:
print(f'{getframeinfo(currentframe()).lineno:03d}: n={n:02d} i={i:03d} * {rows[n][semSort]}')
return i + 1
def fillGroup(parent, parentPath, i, parentCount):
global n
global id
# if DEBUG:
# print(f'{getframeinfo(currentframe()).lineno:03d}: n={n:02d} i={i:03d} - fillGroup boughs[{n}]={boughs[n]}')
data = pintList[i]
id = data['id']
level = data['level']
BT = data['BT']
xpath = data['xpath']
if DEBUG:
print(f'{getframeinfo(currentframe()).lineno:03d}: n={n:02d} i={i:03d} - fillGroup {BT}({id})')
if not xpath or len(xpath) < 9:
return i + 1
while i < len(pintList):
data = pintList[i]
id = data['id']
level = data['level']
BT = data['BT']
xpath = data['xpath']
xpath = xpath[9:]
xpath = formatXPath(xpath)
if parentPath:
_xpath = xpath.replace(parentPath+'/', '')
else:
_xpath = xpath
if re.match(r'ibt-', id):
return None
elif re.match(r'ibg-', id):
if re.match(r'^.*\[not\(.*\)\]', _xpath):
# e.g. .*[not({urn:oasis:names:specification:ubl:schema:xsd:CommonBasicComponents-2}DocumentTypeCode='130')]
xpath_ = re.sub(r'^(.*)\[not\(.*\)\]', r'\1', _xpath)
__xpath = re.sub(r'^(.*)\[not\((.*)\)\]', r'\1[\2]', _xpath)
if parentPath:
elements_ = parent.findall(xpath_)
_elements = parent.findall(__xpath)
else:
elements_ = root.findall(xpath_)
_elements = root.findall(__xpath)
elements = list(set(elements_)-set(_elements))
else:
if 'InvoicePeriod' in xpath:
if 'InvoiceLine' in xpath and parent:
elements = parent.findall(_xpath)
else:
elements = root.findall(_xpath)
elif 'Contact' in xpath:
elements = root.findall(_xpath)
elif parentPath:
elements = parent.findall(_xpath)
else:
elements = root.findall(_xpath)
if not elements or 0 == len(elements):
return i + 1
next_i = None
# ibg-30:LINE TAX INFORMATION
if len(elements) > 1 or id in ['ibg-23', 'ibg-38', 'ibg-25', 'ibg-27', 'ibg-28', 'ibg-32']:
# ibg-23:TAX BREAK DOWN
# ibg-38:TAX BREAKDOWN IN ACCOUNTING CURRENCY
# ibg-25:INVOICE LINE
# ibg-27:INVOICE LINE ALLOWANCE
# ibg-28:INVOICE LINE CHARGE
# ibg-32:ITEM ATTRIBUTES
# print(boughs[n][-1])
count = 0
updateBough(i, count)
else:
count = ''
if not id in ['ibg-32', 'ibt-160', 'ibt-161']:
# ibg-32:ITEM ATTRIBUTES
# ibt-160:Item attribute name
# ibt-161:Item attribute value
n = len(rows) - 1
if id in L12_single_BTG + L1multipleBG:
n = 0
if parents[id][-1] != [x['id'] for x in boughs[n]][-1]:
current_bough = [[x['id'], x['level']] for x in boughs[n]] # [1:-1][-1]
if len(current_bough) > 1:
if len(current_bough) == 2:
current_bough_ = current_bough[-1]
else:
current_bough_ = current_bough[1:-1][-1]
for index, bough_ in boughs.items():
if len(bough_) == 2:
bough_1 = bough_[1]
# print(current_bough_,bough_1)
if current_bough_[0] == bough_1['id'] and current_bough_[1]-1 == bough_1['count']:
n = index
for element in elements:
if isinstance(count, int) and count > 0 and count < len(elements):
updateBough(i, count)
_i = i + 1
_data = pintList[_i]
_id = _data['id']
_level = _data['level']
_BT = _data['BT']
if DEBUG:
id = pintList[i]['id']
print(f'{getframeinfo(currentframe()).lineno:03d}: n={n:02d} i={_i:03d} - fillGroup -check- {BT}({id})[{count}] -> {_BT}({_id})')
while _level > level and _i < len(pintList):
next_i = None
if re.match(r'^ibg-', _id):
next_i = fillGroup(element, xpath, _i, count)
elif re.match(r'^ibt-', _id):
if _id in L12_single_BTG:
n = 0
next_i = fillData(element, xpath, _i, count)
if next_i:
if next_i < len(pintList):
next_data = pintList[next_i]
_id = next_data['id']
_level = next_data['level']
_i = next_i
if next_i == len(pintList):
_i = next_i
else:
_i += 1
if isinstance(count, int):
count += 1
if next_i:
i = next_i
next_i = None
else:
i = _i + 1
return i
if __name__ == '__main__':
# Create the parser
parser = argparse.ArgumentParser(prog='invoice2oim.py',
usage='%(prog)s infile -s PINT -o outfile -e encoding [options]',
description='電子インボイスXMLファイルをOIM-CSVファイルに変換')
# Add the arguments
parser.add_argument('inFile', metavar='infile', type=str, help='入力XMLファイル')
parser.add_argument('-c', '--csvfile')
parser.add_argument('-o', '--oimfile')
parser.add_argument('-s', '--source')
parser.add_argument('-e', '--encoding') # 'Shift_JIS' 'cp932' 'utf_8'
parser.add_argument('-v', '--verbose', action='store_true')
parser.add_argument('-d', '--debug', action='store_true')
args = parser.parse_args()
ncdng = args.encoding
if ncdng:
ncdng = ncdng.lstrip()
else:
ncdng = 'UTF-8'
in_file = None
if args.inFile:
in_file = args.inFile.strip()
in_file = in_file.replace('/', SEP)
in_file = file_path(args.inFile)
# Check if infile exists
if not in_file or not os.path.isfile(in_file):
print('入力ファイルがありません')
sys.exit()
pint_file = None
if args.source:
pint_file = args.source.lstrip()
pint_file = pint_file.replace('/', SEP)
pint_file = file_path(pint_file)
# Check if PINT exists
if not pint_file or not os.path.isfile(pint_file):
print('PINTファイルがありません')
sys.exit()
pre, ext = os.path.splitext(in_file)
if args.csvfile:
csv_file = args.csvfile.lstrip()
csv_file = csv_file.replace('/', SEP)
csv_file = file_path(csv_file)
else:
csv_file = pre+'.csv'
pre, ext = os.path.splitext(csv_file)
if args.oimfile:
oim_file = args.oimfile.lstrip()
oim_file = oim_file.replace('/', SEP)
oim_file = file_path(oim_file)
else:
oim_file = pre+'-oim.csv'
pre, ext = os.path.splitext(oim_file)
metadata_file = pre[:-4]+'-metadata.json'
VERBOSE = False
if args.verbose:
VERBOSE = args.verbose
DEBUG = False
if args.debug:
DEBUG = args.debug
from inspect import currentframe, getframeinfo
if VERBOSE:
print(f'** START ** {__file__}')
print(f'-- Input file {in_file}')
L12_single_BTG = ['ibt-006', 'ibt-007', 'ibt-008', 'ibt-009', 'ibt-010', 'ibt-011', 'ibt-012', 'ibt-013', 'ibt-014', 'ibt-015', 'ibt-016', 'ibt-017', 'ibt-018', 'ibt-018-1', 'ibt-019', 'ibg-02', 'ibt-023', 'ibt-024', 'ibg-04', 'ibt-027', 'ibt-028', 'ibt-029', 'ibt-029-1', 'ibt-090', 'ibt-090-1', 'ibt-030', 'ibt-030-1', 'ibt-031', 'ibt-032', 'ibt-032-1', 'ibt-033', 'ibt-034', 'ibt-034-1', 'ibg-05', 'ibt-035', 'ibt-036', 'ibt-162', 'ibt-037', 'ibt-038', 'ibt-039', 'ibt-040', 'ibg-06', 'ibt-041', 'ibt-042', 'ibt-043', 'ibg-07', 'ibt-044', 'ibt-045', 'ibt-046', 'ibt-046-1', 'ibt-047', 'ibt-047-1', 'ibt-048', 'ibt-048-1', 'ibt-049', 'ibt-049-1', 'ibg-08', 'ibt-050', 'ibt-051', 'ibt-163', 'ibt-052', 'ibt-053', 'ibt-054', 'ibt-055', 'ibg-09', 'ibt-056', 'ibt-057', 'ibt-058', 'ibg-10', 'ibt-059', 'ibt-060', 'ibt-060-1', 'ibt-061', 'ibt-061-1', 'ibg-11', 'ibt-062', 'ibt-063', 'ibt-063-1', 'ibg-12', 'ibt-064', 'ibt-065', 'ibt-164', 'ibt-066', 'ibt-067', 'ibt-068', 'ibt-069', 'ibg-13', 'ibt-070', 'ibt-071', 'ibt-071-1', 'ibt-072', 'ibg-14', 'ibt-073', 'ibt-074', 'ibg-15', 'ibt-075', 'ibt-076', 'ibt-165', 'ibt-077', 'ibt-078', 'ibt-079', 'ibt-080', 'ibg-22', 'ibt-106', 'ibt-107', 'ibt-108', 'ibt-109', 'ibt-110', 'ibt-111', 'ibt-112', 'ibt-113', 'ibt-114', 'ibt-115']
L2_multiple_BG = ['ibg-17', 'ibt-084', 'ibt-085', 'ibt-086']
TaxAccounting = ['ibg-37', 'ibt-111', 'ibg-38', 'ibt-190', 'ibt-192', 'ibt-193', 'ibt-194', 'ibt-195', 'ibt-199', 'igb-23', 'ibt-116', 'ibt-117', 'ibt-118', 'ibt-119']
tree = ET.parse(in_file)
root = tree.getroot()
invoiceNumber = root.findtext(".//{"+ns['cbc']+"}ID")
invoiceIssueDate = root.findtext(".//{"+ns['cbc']+"}IssueDate")
DocumentCurrencyCode = root.findtext(".//{"+ns['cbc']+"}DocumentCurrencyCode")
TaxCurrencyCode = root.findtext(".//{"+ns['cbc']+"}TaxCurrencyCode")
SupplierTaxScheme = root.findtext(".//{"+ns['cac']+"}AccountingSupplierParty/{"+ns['cac']+"}Party/{"+ns['cac']+"}PartyTaxScheme/{"+ns['cac']+"}TaxScheme/{"+ns['cbc']+"}ID")
# SemSort,ID,Section,PINTCard,Aligned,AlignedCard,Level,BT,BT_ja,DT,Desc,Desc_ja,Explanation,Explanation2,Example,SyntSort,element,UBLdatatype,SyntaxBinding,selectors,XPath,SyntaxCard,UBLOccurrence
# 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
#
COL_SemanticSort = 0
COL_ID = 1
COL_card = 5
COL_level = 6
COL_BT = 7
COL_datatype = 9
COL_SyntaxSort = 15
COL_xpath = 20
if VERBOSE:
print(f'*** JP PINT file {pint_file}')
with open(pint_file, encoding='utf_8', newline='') as f0:
reader = csv.reader(f0, delimiter=',')
header = next(reader)
for v in reader:
id = v[COL_ID].strip()
if id:
xpath = v[COL_xpath]
xpath = xpath.replace('/ubl:','/')
syntaxSort = v[COL_SyntaxSort]
if not syntaxSort:
syntaxSort = '9999'
if not xpath:
continue
card = ''+v[COL_card].strip()
maxcard = card[-1]
if '0'==maxcard:
continue
if len(v) > COL_xpath and '/' in xpath:
if re.match(r'.*\[cac:TaxScheme/cbc:ID.*\]', xpath):
xpath = re.sub(r'\[cac:TaxScheme/cbc:ID[ ]*=[ ]*(.*)\]','/cac:TaxScheme[cbc:ID=\\1]/..', xpath)
xpath = re.sub(r'\[cac:TaxScheme/cbc:ID[ ]*!=[ ]*(.*)\]','/cac:TaxScheme[cbc:ID!=\\1]/..', xpath)
if re.match(r'.*\[cbc:TaxAmount/@currencyID.*\]', xpath):
xpath = re.sub(r'\[cbc:TaxAmount/@currencyID[ ]*=[ ]*(.*)\]','/cbc:TaxAmount[@currencyID=\\1]/..', xpath)
if re.match(r'^.*@currencyID=/Invoice/cbc:DocumentCurrencyCode',xpath):
xpath = re.sub(r'^(.*@currencyID=)/Invoice/cbc:DocumentCurrencyCode(/text\(\))?(\].*)$', r'\1"' + DocumentCurrencyCode + r'"\3', xpath)
elif re.match(r'^.*@currencyID=/Invoice/cbc:TaxCurrencyCode',xpath):
if TaxCurrencyCode and id in TaxAccounting:
xpath = re.sub(r'^(.*@currencyID=)/Invoice/cbc:DocumentCurrencyCode(/text\(\))?(\].*)$', r'\1"' + TaxCurrencyCode + r'"\3', xpath)
semanticSort = v[COL_SemanticSort]
if v[COL_BT]:
BT = v[COL_BT]
else:
BT = ''
level = v[COL_level]
if '' == level:
level = 0
try:
level = int(level)
except:
print(f'-- Error {id} "{level}"')
level = 0
# IF ibt-001 HAS level 0
level = 1 + int(level)
v[COL_level] = level
datatype = ''+v[COL_datatype].strip()
data = {'semSort': semanticSort, 'id': id, 'level': level, 'BT': BT, 'card': card, 'datatype': datatype, 'xpath': xpath}
pintList.append(data)
pintDict[semanticSort] = data
pintSemSort[id] = semanticSort
pintMap[id] = data
sorted_rows = sorted(pintList, key=lambda x: x['semSort'])
pintList = sorted_rows
idxLevel = {}
idxLevel = []
parents = {}
for i in range(len(pintList)):
data = pintList[i]
level = int(data['level'])
id = data['id']
num = id
parent = id
if level > 0:
parent = idxLevel[:level]
while level > len(idxLevel) - 1:
idxLevel.append('')
idxLevel[level] = num
parents[id] = parent
L1multipleBG = [x['id'] for x in pintList if 1 == x['level'] and re.match(r'ibg-', x['id']) and 'n' == x['card'][3:]]
L2multipleBG = [x['id'] for x in pintList if 2 == x['level'] and re.match(r'ibg-', x['id']) and 'n' == x['card'][3:]]
bLevel = [{'id': v['id'], 'level':v['level']} for v in pintList if 'ibg' == v['id'][:3] and 'n' == v['card'][-1:]]
boughLevel = {}
for d in bLevel:
boughLevel[d['id']] = int(d['level'])
boughLevel['ibg-32'] = 2
rows = {}
rows[0] = {'0000': 'ibg-00', '0001': 'CONTENT'}
boughs[0] = [{'level': 0, 'id': 'ibg-00', 'count': ''}]
parent_xpath = None
count = ''
n = 0
i = 0
next_i = None
boughLvl = 1
while i < len(pintList):
data = pintList[i]
semSort = data['semSort']
id = data['id']
if not TaxCurrencyCode and id in TaxAccounting:
i += 1
continue
BT = data['BT']
level = data['level']
xpath = data['xpath']
if DEBUG:
print(f'{getframeinfo(currentframe()).lineno:03d}: n={n:02d} pintList[{i}] {BT}({id})')
if re.match(r'^ibt-', id):
i = fillData(None, '', i, None)
elif re.match(r'^ibg-', id):
i = fillGroup(None, '', i, None)
checkedParents = []
for id in rows[0].keys():
if re.match(r'^ibg-', id):
if not id in checkedParents:
checkedParents.append(id)
checkedData = []
for k, v in rows.items():
for semanticSort, data in v.items():
if semanticSort < '1000':
continue
id = data['id']
parentIDs = parents[id] # [1:]
for parentID in parentIDs:
if re.match(r'ibg-', parentID) and not parentID in checkedData and not parentID in checkedParents:
semanticSort = pintSemSort[parentID]
data = {'id': parentID, 'semanticSort': semanticSort}
if not data in checkedData:
checkedData.append(data)
for parent in checkedData:
id = parent['id']
semanticSort = parent['semanticSort']
data = pintDict[semanticSort]
if not semanticSort in rows[0].keys():
rows[0][semanticSort] = {'id': data['id'], 'level': data['level'], 'BT': data['BT'], 'text': ''}
maxBoughLvl = 1
for n, data in boughs.items():
for bough in data:
level = int(bough['level'])
if level > maxBoughLvl:
maxBoughLvl = level
checkedParents = []
for id in rows[0].keys():
if re.match(r'^ibg-', id):
if not id in checkedParents:
checkedParents.append(id)
checkedData = []
for k, v in rows.items():
for semanticSort, data in v.items():
if semanticSort < '1000':
continue
id = data['id']
parentIDs = parents[id]
for parentID in parentIDs:
if re.match(r'ibg-', parentID) and not parentID in checkedData and not parentID in checkedParents:
semanticSort = pintSemSort[parentID]
data = {'id': parentID, 'semanticSort': semanticSort}
if not data in checkedData:
checkedData.append(data)
for parent in checkedData:
id = parent['id']
semanticSort = parent['semanticSort']
data = pintDict[semanticSort]
if not semanticSort in rows[0].keys():
rows[0][semanticSort] = {'id': data['id'], 'level': data['level'], 'BT': data['BT'], 'text': ''}
maxBoughLvl = 1
for n, data in boughs.items():
for bough in data:
level = int(bough['level'])
if level > maxBoughLvl:
maxBoughLvl = level
bough_rows = {}
for n in rows.keys():
bough_rows[n] = {}
m = 0
for bough in boughs[n]:
level = int(bough['level'])
id = bough['id']
if 'ibg-00' == id:
BT = 'INVOICE'
else:
semSort = pintSemSort[id]
data = pintDict[semSort]
BT = data['BT']
count = str(bough['count'])
bough_rows[n]['000'+str(3*level)] = id
bough_rows[n]['000'+str(1 + 3*level)] = BT
bough_rows[n]['000'+str(2 + 3*level)] = count
m += 1
for i in range(maxBoughLvl - m):
bough_rows[n]['000'+str(3*(m + i))] = ''
bough_rows[n]['000'+str(1 + 3*(m + i))] = ''
bough_rows[n]['000'+str(2 + 3*(m + i))] = ''
# if DEBUG: print(f'{getframeinfo(currentframe()).lineno:03d}: n={n:02d} bough_rows[{n}] {bough_rows[n]}')
for n, row in rows.items():
for semSort, data in row.items():
if int(semSort) < 1000:
continue
bough_rows[n][semSort] = data
max_col = len(bough_rows)
transposed = {}
lookup = {}
index = 0
for col, row in bough_rows.items():
for semSort, data in row.items():
if not semSort in transposed:
transposed[semSort] = {}
if semSort in pintDict:
d = pintDict[semSort]
transposed[semSort][0] = d['id']
transposed[semSort][1] = d['level']
transposed[semSort][2] = d['card']
transposed[semSort][3] = d['BT']
else:
transposed[semSort][0] = ''
transposed[semSort][1] = ''
transposed[semSort][2] = ''
transposed[semSort][3] = ''
if int(semSort) < 1000: # when'0000'==semSort or '0001'==semSort:
transposed[semSort][4+col] = data
elif data['text']:
transposed[semSort][4+col] = data['text']
od_transposed = collections.OrderedDict(sorted(transposed.items()))
del_list = []
for semSort, data in od_transposed.items():
check = ''
for k, v in data.items():
if k > 3:
check += v
if not check and not re.match(r'^ibg-', data[0]):
del_list.append(semSort)
for semSort in del_list:
del transposed[semSort]
max_col += 4
lst = []
i = 0
for row in od_transposed:
lst.append(['']*max_col)
i = 0
for semSort, data in od_transposed.items():
for j in range(max_col):
if j in od_transposed[semSort]:
lst[i][j] = od_transposed[semSort][j]
i += 1
with open(csv_file, 'w', encoding='utf-16') as f:
writer = csv.writer(f) # ,delimiter='\t')
n = 0
for l in lst:
if n < 3:
n += 1
continue
writer.writerow(l)
#
# xBRL-CSV
#
max_x = len(lst[0])
h = 0
while '' == lst[h][0]:
h += 1
max_h = int(h/3)
max_y = len(lst)
num_d = 0
header = []
for x in range(4, max_x):
for h in range(max_h):
ibg_id = lst[3*h][x]
if ibg_id and not ibg_id in header:
header.append(ibg_id)
num_d += 1
for y in range(3*max_h, max_y):
ibt_id = lst[y][0]
if re.match(r'^ibt-[0-9]*(-[0-9]*)?',ibt_id) and not ibt_id in header:
header.append(ibt_id)
records = []
for x in range(4, max_x):
record = {}
for i in range(len(header)):
record[header[i]] = ''
for h in range(max_h):
ibg_id = lst[3*h][x]
if ibg_id:
if 'ibg-00'==ibg_id:
v = invoiceNumber
else:
v = lst[3*h + 2][x]
record[ibg_id] = v
for y in range(3*max_h, max_y):
ibt_id = lst[y][0]
v = lst[y][x]
if v:
record[ibt_id] = v
records.append(record)
lineID = ''
for record in records:
if 'ibg-23' in record and len(record['ibg-23'])>0:
record['ibg-23'] = f"{record['ibt-118']}{record['ibt-119']}"
if ('ibg-25' in record and len(record['ibg-25']) > 0) or \
('ibg-27' in record and len(record['ibg-27']) > 0) or \
('ibg-28' in record and len(record['ibg-28']) > 0) or \
('ibg-32' in record and len(record['ibg-32']) > 0):
if 'ibt-126' in record and len(record['ibt-126']) > 0:
lineID= record['ibt-126']
record['ibg-25'] = lineID
header = [x.replace('ibg-','G') for x in header]
with open(oim_file,'w',encoding=ncdng,newline='') as oimfile:
writer = csv.DictWriter(oimfile, fieldnames=header)
writer.writeheader()
for record in records:
data = {}
for k,v in record.items():
k = k.replace('ibg-','G')
data[k] = v
writer.writerow(data)
if VERBOSE:
print(f'-- xBRL-CSV {oim_file}')
metadata = {
"documentInfo": {
"documentType": "https://xbrl.org/2021/xbrl-csv",
"namespaces": {
"pint": "http://www.xbrl.jp/eipa/peppol/0.9",
"ns0": "http://www.example.com",
"link": "http://www.xbrl.org/2003/linkbase",
"iso4217": "http://www.xbrl.org/2003/iso4217",
"xsi": "http://www.w3.org/2001/XMLSchema-instance",
"xbrli": "http://www.xbrl.org/2003/instance",
"xbrldi": "http://xbrl.org/2006/xbrldi",
"xlink": "http://www.w3.org/1999/xlink"
},
"taxonomy": [
"core.xsd"
],
},
"tableTemplates": {
"pint": {
"columns": {
},
"dimensions": {
"pint:_380": "$G00",
"period": "",
"entity": "ns0:Example co."
}
}
},
"tables": {
"pint": {
"url": ""
}
}
}
n = 4
for id in header:
if re.match(r'^G[0-9]*$',id) and n < max_x:
ID = id
metadata['tableTemplates']['pint']['columns'][ID] = {}
if 'G00'!=id:
metadata['tableTemplates']['pint']['dimensions'][f"pint:{ID}"] = f"${ID}"
elif re.match(r'^ibt-[0-9]*',id):
d = pintMap[id]
if d['datatype'] in ['Amount', 'Unit Price Amount']:
metadata['tableTemplates']['pint']['columns'][id] = {
'decimals': 0,
'dimensions': {
'concept': f'pint:{id}',
'unit': f'iso4217:{DocumentCurrencyCode}' # TODO TaxCurrencyCode
}
}
else:
metadata['tableTemplates']['pint']['columns'][id] = {
'dimensions': {
'concept': f'pint:{id}',
}
}
metadata['tableTemplates']['pint']['dimensions']['period'] = f'{invoiceIssueDate}T00:00:00'
metadata['tables']['pint']['url'] = os.path.basename(oim_file)
with open(metadata_file, 'w') as metadatafile:
json.dump(metadata, metadatafile, indent=4)
if VERBOSE:
print(f'-- metadata {metadata_file}')
print('** END')デジタルインボイスXML文書からTidy data形式のCSVを生成するプログラム
プログラムの処理の流れは、次の順序です。
1. JP PINT 0.9.3の定義表(Excel)からPINT変換辞書データを作成しておく。
2. xBRL-GD定義のCSVデータファイルを読み込み、PINT変換辞書データのSyntaxソート順に辞書データに展開する。
3. Syntaxソート順辞書データ展開したCSVレコードからPINT変換辞書データに項目ごとに定義されたXPathを使ってElement
Treeの関数を使用して該当データの値をXML文書に設定する。
4. Element Treeライブラリを使用してXML文書をファイルに出力する。
#!/usr/bin/env python3
#coding: utf-8
#
# generate Open Peoopl e-Invoice (UBL 2.1) from xBRL-CSV file
#
# designed by SAMBUICHI, Nobuyuki (Sambuichi Professional Engineers Office)
# written by SAMBUICHI, Nobuyuki (Sambuichi Professional Engineers Office)
#
# MIT License
#
# Copyright (c) 2021 SAMBUICHI Nobuyuki (Sambuichi Professional Engineers Office)
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
import xml.etree.ElementTree as ET
from collections import defaultdict
import csv
import re
import sys
import os
import argparse
from dic2etree import *
ET.register_namespace('', ns[''])
ET.register_namespace('xsd', ns['xsd'])
ET.register_namespace('xsi', ns['xsi'])
ET.register_namespace('cac', ns['cac'])
ET.register_namespace('cbc', ns['cbc'])
ET.register_namespace('qdt', ns['qdt'])
ET.register_namespace('udt', ns['udt'])
ET.register_namespace('ccts', ns['ccts'])
# if use ubl: namespace prefix
# ET.register_namespace('ubl', ns['ubl'])
# ET.register_namespace('cn', ns['cn'])
SEP = os.sep
TaxAccounting = ['ibg-37', 'ibt-111', 'ibg-38', 'ibt-190', 'ibt-192', 'ibt-193', 'ibt-194', 'ibt-195']
Allowances = []
Charges = []
allowance_exist = False
charge_exist = False
document_allowance_count = 0
line_allowance_count = 0
# index_AllowanceCharge = -1
# new_AllowanceCharge = False
def file_path(pathname):
if '/' == pathname[0:1]:
return pathname
else:
dir = os.path.dirname(__file__)
new_path = os.path.join(dir, pathname)
return new_path
def set_path_value(base, path, value, datatype):
global CurrencyCode
if DEBUG:
base_tag = re.sub(r'{.*}', '', str(base.tag))
print(f'{base_tag} - {"/".join(path)} {value}')
if len(path) > 1 and path[1].isdigit():
n = int(path[1])
path = path[:1] + path[2:]
else:
n = 0
elements = None
if len(path) > 1 and '@' == path[1][:1]:
_attr = path[1][1:]
p = path[0].split(':')
el = ET.QName(ns[p[0]], p[1])
elements = base.findall(str(el))
if len(elements) > 0:
element = elements[0]
else:
element = ET.SubElement(base, el)
element.set(_attr, value)
else:
if path[0] == 'Invoice':
p = path[1].split(':')
else:
p = path[0].split(':')
if not p[0] in ns:
print(p)
return
elif 2 == len(p):
el = ET.QName(ns[p[0]], p[1])
elements = base.findall(str(el))
else:
return
if elements and len(elements) > 0:
if len(elements) > n:
element = elements[n]
else:
element = ET.SubElement(base, el)
if 'cbc' == p[0]:
element.text = value
else:
_path = path[1:]
set_path_value(element, _path, value, datatype)
else:
element = ET.SubElement(base, el)
if 'cbc' == p[0]:
element.text = value
if 'Amount' == datatype or 'Unit Price Amount' == datatype:
element.set('currencyID', CurrencyCode)
elif 'PartyTaxScheme' == str(base.tag)[-14:] and 'CompanyID' == p[1]:
el1 = ET.QName(ns['cac'], 'TaxScheme')
element1 = ET.SubElement(base, el1)
el2 = ET.QName(ns['cbc'], 'ID')
element2 = ET.SubElement(element1, el2)
element2.text = 'VAT'
elif 'TaxCategory' == str(base.tag)[-11:] and 'Percent' == p[1]:
el1 = ET.QName(ns['cac'], 'TaxScheme')
element1 = ET.SubElement(base, el1)
el2 = ET.QName(ns['cbc'], 'ID')
element2 = ET.SubElement(element1, el2)
element2.text = 'VAT'
else:
_path = path[1:]
set_path_value(element, _path, value, datatype)
def set_record(record):
global root
global sorted_header
global CurrencyCode
global allowance_exist
global charge_exist
global document_allowance_count
global line_allowance_count
# global new_AllowanceCharge
# global index_AllowanceCharge
i = 0
head = []
seq1 = '0'
seq2 = '0'
head1_pathList = None
head2_pathList = None
base_path = None
while re.match(r'^G[0-9]*$',header[i]):
if record[i]:
data = {'id':'ibg-'+header[i][1:], 'value':record[i]}
head.append(data)
i += 1
head0_id = head[0]['id']
if len(head) > 0:
if head0_id and head0_id in pintDict and 'xpath' in pintDict[head0_id]:
head0_xpath = pintDict[head0_id]['xpath']
if re.match(r'^(.*)\[.*\](.*)$', head0_xpath):
head0_xpath = re.sub(r'^(.*)\[.*\](.*)$', r'\1\2', head0_xpath)
head0_pathList = head0_xpath[1:].split('/')[1:]
if 'ibt' == head0_id[:3]:
head0_pathList = head0_pathList[-1:]
base0_path = head0_pathList[:-1]
elif len(head0_pathList) > 0:
head0_pathList = []
base0_path = head0_pathList
if len(head0_xpath[1:].split('/')) > 1:
base = '/'+'/'.join(base0_path[:-1]) # head_xpath
else:
base = ''
base_path = []
if len(head) > 1:
head1_id = head[1]['id']
seq1 = head[1]['value']
if head1_id and head1_id in pintDict and 'xpath' in pintDict[head1_id]:
head1_xpath = pintDict[head1_id]['xpath']
if re.match(r'^(.*)\[.*\](.*)$', head1_xpath):
head1_xpath = re.sub(r'^(.*)\[.*\](.*)$', r'\1\2', head1_xpath)
head1_xpath = head1_xpath.replace(head0_xpath,'')
head1_pathList = head1_xpath[1:].split('/')
if 'ibt' == head1_id[:3]:
head1_pathList = head1_pathList[:-1] + [seq1] + head1_pathList[-1:]
base_path = head1_pathList[:-1]
elif len(head1_pathList) > 0:
head1_pathList = head1_pathList + [seq1]
base_path = head1_pathList
if len(head) > 2:
head2_id = head[2]['id']
seq2 = head[2]['value']
if head2_id and head2_id in pintDict and 'xpath' in pintDict[head2_id]:
head2_xpath = pintDict[head2_id]['xpath']
if re.match(r'^(.*)\[.*\](.*)$', head2_xpath):
head2_xpath = re.sub(r'^(.*)\[.*\](.*)$', r'\1\2', head2_xpath)
head2_xpath = head2_xpath.replace(head0_xpath,'')
head2_pathList = head2_xpath[1:].split('/')
if 'ibt' == head2_id[:3]:
head2_pathList = head1_pathList[:-1] + [seq1] + head2_pathList[:-1] + [seq2] + head2_pathList[-1:]
base_path = head2_pathList[:-1]
elif len(head2_pathList) > 0:
head2_pathList = head1_pathList + [seq1] + head2_pathList + [seq2]
base_path = head1_pathList
# traverse field in a record
for n in range(len(record)):
cell = record[n]
h = sorted_header[n]
if re.match(r'^G[0-9]*$',h):
continue
if len(cell) > 0:
id = sorted_header[n]
if not id in pintDict:
continue
if 'ibt-126' == id: # Invoice line identifier
allowance_exist = False
charge_exist = False
line_allowance_count = 0
# index_AllowanceCharge = -1
# new_AllowanceCharge = False
# if DEBUG:
# print(f'- id:{id} index_AllowanceCharge:{index_AllowanceCharge} allowance_exist:{allowance_exist}')
data = pintDict[id]
datatype = data['datatype']
xpath = data['xpath']
xpath_ = None
# remove [...] from xpath
if re.match(r'^(.*)\[.*\](.*)$', xpath):
xpath_ = re.sub(r'^(.*)\[.*\](.*)$', r'\1\2', xpath)
pathList = xpath_[1:].split('/')
else:
pathList = xpath[1:].split('/')
if "[cbc:DocumentTypeCode='130']" in xpath:
xpath = xpath.replace("[cbc:DocumentTypeCode='130']", '')
if 'cac:InvoiceLine' in pathList:
idxT188 = sorted_header.index('ibt-188')
index = 1 + pathList.index('cac:DocumentReference')
if record[idxT188]: # 1bt-188 and ibt-128,ibt-128-1 are cac:DocumentReference/cbc:ID
pathList = pathList[:2] + [seq1] + pathList[2:index] + ['1'] + pathList[index:]
else:
pathList = pathList[:2] + [seq1] + pathList[2:index] + ['0'] + pathList[index:]
path = pathList[1:]
CurrencyCode = DocumentCurrencyCode
set_path_value(root, path, cell, datatype)
if not '@schemeID' in pathList:
path = pathList[:-1] + ['cbc:DocumentTypeCode']
path = path[1:]
CurrencyCode = DocumentCurrencyCode
set_path_value(root, path, '130', datatype)
elif "[not(cbc:DocumentTypeCode='130')]" in xpath:
if 'cac:AdditionalDocumentReference' in xpath:
pathList = pathList[:2] + [seq1] + pathList[2:]
path = pathList
elif 'cac:InvoiceLine' in xpath:
pathList = pathList[:2] + [seq1] + pathList[2:]
path = pathList
else:
path = pathList
path = path[1:]
CurrencyCode = DocumentCurrencyCode
set_path_value(root, path, cell, datatype)
elif '/Invoice/cac:TaxTotal' in xpath:
if 'DocumentCurrencyCode' in xpath:
_xpath = re.sub(r'^(.*)\[.*\](.*)$', r'\1\2', xpath)
path = _xpath[1:].split('/')
if 'cac:TaxSubtotal' in path:
path = ['cac:TaxTotal', '0', 'cac:TaxSubtotal'] + [seq1] + path[3:]
CurrencyCode = DocumentCurrencyCode
set_path_value(root, path, cell, datatype)
else:
path = ['cac:TaxTotal', '0'] + path[2:]
CurrencyCode = DocumentCurrencyCode
set_path_value(root, path, cell, datatype)
elif 'TaxCurrencyCode' in xpath:
_xpath = re.sub(r'^(.*)\[.*\](.*)$', r'\1\2', xpath)
path = _xpath[1:].split('/')
if 'cac:TaxSubtotal' in path:
path = ['cac:TaxTotal', '1', 'cac:TaxSubtotal'] + [str(seq1)] + path[3:]
CurrencyCode = TaxCurrencyCode
set_path_value(root, path, cell, datatype)
else:
path = ['cac:TaxTotal', '1'] + path[2:]
CurrencyCode = TaxCurrencyCode
set_path_value(root, path, cell, datatype)
else:
if 'cac:TaxTotal' in Dic['Invoice'] and isinstance(Dic['Invoice']['cac:TaxTotal'], list):
if 'ibt-117-1' in header:
if DocumentCurrencyCode == record[header.index('ibt-117-1')]:
loc = '0'
else:
loc = '1'
else:
loc = '0'
pathList = xpath[1:].split('/')
path = pathList[:2] + [loc] + pathList[2:]
path = path[:4] + [seq1] + path[4:]
path = path[1:]
CurrencyCode = DocumentCurrencyCode
set_path_value(root, path, cell, datatype)
else:
pathList = re.sub(base, '', xpath)[1:].split('/')
path = base_path + pathList
path = path[1:]
CurrencyCode = DocumentCurrencyCode
set_path_value(root, path, cell, datatype)
elif 'ChargeIndicator=' in xpath:
_xpath = xpath[9:]
# remove [] condition from xpath
allowanceCharge = re.sub(r'(.*)\[cbc:ChargeIndicator=(true|false)\(\)\](.*)', r'\1', _xpath)
chargeIndicator = re.sub(r'.*\[cbc:ChargeIndicator=(true|false)\(\)\](.*)', r'\1', _xpath)
pathList = allowanceCharge.split('/')
if 'cac:InvoiceLine' in _xpath:
if len(pathList) > 1:
pathList = pathList[:1] + [seq1] + pathList[1:]
else:
pathList = pathList + [seq1]
if 'cac:Price' in pathList:
path = pathList
path.append('cbc:ChargeIndicator')
set_path_value(root, path, chargeIndicator, 'Indicator')
path = re.sub(r'(.*)\[cbc:ChargeIndicator=false\(\)\](.*)', r'\1\2', xpath)[1:].split('/')
path = path[:2] + [seq1] + path[2:]
path = path[1:]
CurrencyCode = DocumentCurrencyCode
set_path_value(root, path, cell, datatype)
else:
# if 'ibt-146'==id:
if id in [v['id'] for k, v in semDict.items() if 'ibg-29' == v['parent']]: # PRICE DETAILS
path = pathList + ['0']
path.append('cbc:ChargeIndicator')
set_path_value(root, path, chargeIndicator, 'Indicator')
elif id in [v['id'] for k, v in semDict.items() if 'ibg-20' == v['parent']] and not allowance_exist:
# children of DOCUMENT LEVEL ALLOWANCES
allowance_exist = True
document_allowance_count += 1
path = pathList + [seq1]
path.append('cbc:ChargeIndicator')
set_path_value(root, path, chargeIndicator, 'Indicator')
elif id in [v['id'] for k, v in semDict.items() if 'ibg-21' == v['parent']] and not charge_exist:
# children of DOCUMENT LEVEL CHARGES
charge_exist = True
seq1 = str(document_allowance_count + int(seq1))
path = pathList + [seq1]
path.append('cbc:ChargeIndicator')
set_path_value(root, path, chargeIndicator, 'Indicator')
elif id in [v['id'] for k, v in semDict.items() if 'ibg-27' == v['parent']] and not allowance_exist:
# children of INVOICE LINE ALLOWANCES
allowance_exist = True
line_allowance_count += 1
path = pathList + [seq2]
path.append('cbc:ChargeIndicator')
set_path_value(root, path, chargeIndicator, 'Indicator')
elif id in [v['id'] for k, v in semDict.items() if 'ibg-28' == v['parent']] and not charge_exist:
# children of INVOICE LINE CHARGES
charge_exist = True
seq2 = str(line_allowance_count + int(seq2))
path = pathList + [seq2]
path.append('cbc:ChargeIndicator')
set_path_value(root, path, chargeIndicator, 'Indicator')
# seq_ = str(index_AllowanceCharge)
# if new_AllowanceCharge:
# path = pathList + [seq_]
# path.append('cbc:ChargeIndicator')
# if 'Invoice' == path[0]:
# path = path[1:]
# set_path_value(root, path, chargeIndicator, 'Indicator')
# new_AllowanceCharge = False
xpath = re.sub(r'(.*)\[cbc:ChargeIndicator=(true|false)\(\)\](.*)', r'\1\3', xpath)
pathList = xpath[1:].split('/')
if 'cac:InvoiceLine' in pathList:
path = pathList[:2] + [seq1] + pathList[2:3] + [seq2] + pathList[3:]
else:
path = pathList[:2] + [seq1] + pathList[2:]
path = path[1:]
CurrencyCode = DocumentCurrencyCode
set_path_value(root, path, cell, datatype)
else:
if 'cac:InvoiceLine' in pathList:
if 'cac:AdditionalItemProperty' in pathList:
pathList = pathList[:2] + [seq1] + pathList[2:4] + [seq2 or '0'] + pathList[4:]
else:
pathList = pathList[:2] + [seq1] + pathList[2:]
if 'cac:DespatchLineReference' in pathList:
path_ = pathList[1:4] + ['cbc:LineID']
set_path_value(root, path_, '0000', 'Identifier')
path = pathList[1:]
CurrencyCode = DocumentCurrencyCode
set_path_value(root, path, cell, datatype)
if 'ibt-087' == id:
# UBL requires cbc:NetworkID when cbc:PrimaryAccountNumberIDPayment card primary account number (4 to 6 digits) is used.
path[-1] = 'cbc:NetworkID'
set_path_value(root, path, 'NA', datatype)
def writeET(root,out_file):
element = ET.ElementTree(root)
ET.indent(element,space='\t')
element.write(out_file, xml_declaration=True, encoding='utf-8')
if __name__ == '__main__':
# Create the parser
parser = argparse.ArgumentParser(prog='csv2invoice',
usage='%(prog)s [options] infile -o outfile',
description='OIM-CSVファイルから電子インボイスXMLを作成')
# Add the arguments
parser.add_argument('inFile', metavar='infile', type=str, help='入力OIM-CSVファイル')
parser.add_argument('-s', '--source')
parser.add_argument('-o', '--out')
parser.add_argument('-e', '--encoding') # e.g. utf-16 Shift_JIS cp932
parser.add_argument('-t', '--transpose', action='store_true')
parser.add_argument('-v', '--verbose', action='store_true')
parser.add_argument('-d', '--debug', action='store_true')
args = parser.parse_args()
in_file = None
if args.inFile:
in_file = args.inFile
in_file = in_file.replace('/', SEP)
in_file = file_path(in_file)
# Check if infile exists
if not in_file or not os.path.isfile(in_file):
print('入力ファイルがありません')
sys.exit()
pre, ext = os.path.splitext(in_file)
pint_file = None
if args.source:
pint_file = args.source.lstrip()
pint_file = pint_file.replace('/', SEP)
pint_file = file_path(pint_file)
# Check if PINT exists
if not pint_file or not os.path.isfile(pint_file):
print('PINTファイルがありません')
sys.exit()
if args.out:
out_file = args.out.lstrip()
out_file = file_path(out_file)
else:
out_file = pre+'.xml'
# tmp_file = pre+'.txt'
ncdng = args.encoding.lstrip()
if not ncdng:
ncdng = 'UTF-8'
TRANSPOSE = args.verbose
VERBOSE = args.verbose
DEBUG = args.debug
if VERBOSE:
print('** START ** ', __file__)
# initialize globals
pintDict = {}
semDict = {}
syntaxDict = {}
header_id = None
header_count = 0
DocumentCurrencyCode = None
TaxCurrencyCode = None
CurrencyCode = None
Dic = defaultdict(type(''))
Dic['Invoice'] = {}
sortedDic = defaultdict(type(''))
sortedDic['Invoice'] = {}
pintDict = defaultdict(type(''))
pintL1 = []
multipleBG = []
# SemSort,ID,Section,PINTCard,Aligned,AlignedCard,Level,BT,BT_ja,DT,Desc,Desc_ja,Explanation,Explanation2,Example,SyntSort,element,UBLdatatype,SyntaxBinding,selectors,XPath,SyntaxCard,UBLOccurrence,SharedRule,AlignedRule
# 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
COL_SemanticSort = 0
COL_ID = 1
COL_card = 5
COL_level = 6
COL_BT = 7
COL_datatype = 9
COL_syntSort = 15
COL_xpath = 20
if VERBOSE:
print(f'*** XPath file {pint_file}')
with open(pint_file, encoding='utf-8', newline='') as f0:
reader = csv.reader(f0) # , delimiter='\t')
header = next(reader)
for v in reader:
id = v[COL_ID].strip()
if id:
semSort = v[COL_SemanticSort]
xpath = v[COL_xpath]
xpath = xpath.replace('/ubl:','/')
syntSort = v[COL_syntSort]
if not syntSort:
syntSort = '9999'
if not xpath:
continue
if len(v) > COL_xpath and '/' in xpath:
if v[COL_BT]:
BT = v[COL_BT]
else:
BT = None
level = v[COL_level]
if level:
level = 1+int(level)
level = str(level)
else:
level = '0'
card = ''+v[COL_card].strip()
datatype = ''+v[COL_datatype].strip()
data = {'syntSort': syntSort, 'id': id, 'level': level, 'BT': BT, 'card': card, 'datatype': datatype, 'xpath': xpath}
pintDict[id] = data
semDict[semSort] = {'id': id, 'level': int(level)}
sorted_semDict = sorted(semDict.items(), key=lambda x: x[0])
level = 0
parent = ['ibg-00']
for k, v in dict(sorted_semDict).items():
if v['level'] == level:
semDict[k]['parent'] = parent[level-1]
parent[level] = v['id']
elif v['level'] == level+1:
semDict[k]['parent'] = parent[level]
level = v['level']
if level == len(parent):
parent.append(None)
parent[level] = v['id']
else:
level = v['level']
semDict[k]['parent'] = parent[level-1]
parent[level] = v['id']
for i in range(len(parent)):
if i > level:
parent[i] = None
if VERBOSE:
print(f'*** Input file {in_file}')
with open(in_file, encoding=ncdng, newline='') as f:
reader = csv.reader(f) # , delimiter='\t')
rows = []
count = 0
for record in reader:
if 0 == count:
header = []
for field in record:
header.append(field)
elif 1==count:
for n in range(0,len(record)):
id = header[n]
data = pintDict[id]
if 'ibt-005' == id:
DocumentCurrencyCode = record[n]
elif 'ibt-006' == id:
TaxCurrencyCode = record[n]
count += 1
rows.append(record)
# change to occurence sequence
idxG00 = header.index('G00')
idxG23 = header.index('G23')
idxG25 = header.index('G25')
currentG00 = ''
currentG23 = ''
currentG25 = ''
countG00 = 0
countG23 = 0
countG25 = 0
for i in range(1,len(rows)):
row = rows[i]
# G00
if not currentG00:
if len(row[idxG00]) > 0:
currentG00 = row[idxG00]
countG00 = 0
else:
if len(row[idxG00]) > 0 and currentG00 != row[idxG00]:
currentG00 = row[idxG00]
countG00 += 1
if row[idxG00]:
row[idxG00] = str(countG00)
# G23
if not currentG23:
if len(row[idxG23]) > 0:
currentG23 = row[idxG23]
countG23 = 0
else:
if len(row[idxG23]) > 0 and currentG23 != row[idxG23]:
currentG23 = row[idxG23]
countG23 += 1
if row[idxG23]:
row[idxG23] = str(countG23)
# G25
if not currentG25:
if len(row[idxG25]) > 0:
currentG25 = row[idxG25]
countG25 = 0
else:
if len(row[idxG25]) > 0 and currentG25 != row[idxG25]:
currentG25 = row[idxG25]
countG25 += 1
if row[idxG25]:
row[idxG25] = str(countG25)
rows[i] = row
if 'ibt-018' in header:
index = rows[0].index('G24')
for row in rows:
if row[index] and 'G24'!=row[index]:
g24 = row[index]
row[index] = str(1 + int(g24))
# sort order by stntax sort
header = rows[0]
dim_n = 0
while re.match(r'^G[0-9]*$',header[dim_n]):
dim_n += 1
dim_header = []
for n in range(dim_n):
dim_header.append({'id':header[n],'num':n})
sorted_dimHeader = sorted(dim_header, key=lambda x: pintDict[f"ibg-{x['id'][-2:]}"]['syntSort'])
element_header = []
for n in range(dim_n,len(header)):
element_header.append({'id':header[n],'num':n})
sorted_elementHeader = sorted(element_header, key=lambda x: pintDict[x['id']]['syntSort'])
sorted_header = []
for d in sorted_dimHeader:
sorted_header.append(d['id'])
for d in sorted_elementHeader:
sorted_header.append(d['id'])
sorted_rows = []
sorted_rows.append(sorted_header)
for j in range(1,len(rows)):
row = rows[j]
sorted_row = ['']*len(row)
for k in range(dim_n):
num = sorted_dimHeader[k]['num']
sorted_row[k] = row[num]
for k in range(dim_n,len(row)):
num = sorted_elementHeader[k - dim_n]['num']
sorted_row[k] = row[num]
sorted_rows.append(sorted_row)
idxG24 = None
idxG25 = None
idxG27 = None
idxG28 = None
idxG32 = None
if 'G24' in sorted_rows[0]:
idxG24 = sorted_rows[0].index('G24')
if 'G25' in sorted_rows[0]:
idxG25 = sorted_rows[0].index('G25')
if 'G27' in sorted_rows[0]:
idxG27 = sorted_rows[0].index('G27')
if 'G28' in sorted_rows[0]:
idxG28 = sorted_rows[0].index('G28')
if 'G32' in sorted_rows[0]:
idxG32 = sorted_rows[0].index('G32')
dimsDocument = [
{'id':'G03', 'BT':'PRECEDING INVOICE REFERENCE'},
{'id':'G24', 'BT':'ADDITIONAL SUPPORTING DOCUMENTS'},
{'id':'G16', 'BT':'PAYMENT INSTRUCTIONS'},
{'id':'G33', 'BT':'INVOICE TERMS'},
{'id':'G35', 'BT':'Paid amounts'},
{'id':'G20', 'BT':'DOCUMENT LEVEL ALLOWANCES'},
{'id':'G21', 'BT':'DOCUMENT LEVEL CHARGES'},
{'id':'G23', 'BT':'TAX BREAKDOWN'},
{'id':'G38', 'BT':'TAX BREAKDOWN IN ACCOUNTING CURRENCY'}]
dimsLine = [
{'id':'G25', 'BT':'INVOICE LINE'},
{'id':'G27', 'BT':'INVOICE LINE ALLOWANCES'},
{'id':'G28', 'BT':'INVOICE LINE CHARGES'},
{'id':'G30', 'BT':'LINE TAX INFORMATION'},
]
leading_ibt = ['ibt-024','ibt-023','ibt-001','ibt-002','ibt-168','ibt-009','ibt-003','ibt-022','ibt-007','ibt-005','ibt-006','ibt-019','ibt-010','ibg-14','ibt-073','ibt-074','ibt-008','ibt-013','ibt-014','ibg-03','ibt-025','ibt-026','ibt-016','ibt-015','ibt-017','ibt-012','ibt-018','ibt-018-1']
item_ibt = ['ibt-154','ibt-153','ibt-156','ibt-155','ibt-157','ibt-157-1','ibt-159','ibt-158','ibt-158-1','ibt-158-2','ibt-151','ibt-152','ibt-166','ibt-167','ibt-160','ibt-161']
price_ibt = ['ibt-146','ibt-149','ibt-147','ibt-148','ibt-150']
l = len(row)
reviced_rows = []
reviced_rows.append(sorted_rows[0])
row = sorted_rows[1]
leading = [sorted_rows[0][n] in leading_ibt for n in range(l)]
trailing = [not leading[n] for n in range(l)]
leading_row = ['']*l
for n in range(l):
if n < dim_n or leading[n]:
leading_row[n] = row[n]
reviced_rows.append(leading_row)
trailing_row = ['']*l
for n in range(l):
if n < dim_n or trailing[n]:
trailing_row[n] = row[n]
reviced_rows.append(trailing_row)
sorted_rows2 = sorted_rows[2:]
for dim in dimsDocument:
id = dim['id']
if id in sorted_rows[0]:
index = sorted_rows[0].index(id) # id is dimension of document level
for row in sorted_rows2:
if row[index]:
if 'G24'==id:
last_i = len(reviced_rows)-1
previous_row = reviced_rows[last_i]
reviced_rows[last_i] = row
reviced_rows.append(previous_row)
else:
reviced_rows.append(row)
l = len(sorted_header)
# countG27 = 0
for i in range(len(sorted_rows2)):
row = sorted_rows2[i]
if idxG25 and row[idxG25]:
if idxG27 or idxG28:
if not((idxG27 and row[idxG27]) or (idxG28 and row[idxG28]) or (idxG32 and row[idxG32])):
before = [not sorted_header[n] in item_ibt + price_ibt for n in range(l)]
after = [sorted_header[n] in item_ibt + price_ibt for n in range(l)]
row1 = ['']*l
for n in range(l):
if n < dim_n or before[n]:
row1[n] = row[n]
reviced_rows.append(row1)
row2 = ['']*l
for n in range(l):
if n < dim_n or after[n]:
row2[n] = row[n]
reviced_rows.append(row2)
elif (idxG27 and row[idxG27]):
print(row[idxG27])
last_i = len(reviced_rows) - 1
previous_row = reviced_rows[last_i]
reviced_rows[last_i] = row
reviced_rows.append(previous_row)
elif (idxG28 and row[idxG28]):
print(row[idxG28])
last_i = len(reviced_rows) - 1
previous_row = reviced_rows[last_i]
reviced_rows[last_i] = row
reviced_rows.append(previous_row)
else:
reviced_rows.append(row)
else:
reviced_rows.append(row)
invoiceText = '''
<Invoice \n
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="urn:oasis:names:specification:ubl:schema:xsd:Invoice-2"
xmlns:cac="urn:oasis:names:specification:ubl:schema:xsd:CommonAggregateComponents-2"
xmlns:cbc="urn:oasis:names:specification:ubl:schema:xsd:CommonBasicComponents-2"
xmlns:ccts="urn:un:unece:uncefact:documentation:2"
xmlns:ext="urn:oasis:names:specification:ubl:schema:xsd:CommonExtensionComponents-2"
xmlns:qdt="urn:oasis:names:specification:ubl:schema:xsd:QualifiedDatatypes-2"
xmlns:udt="urn:un:unece:uncefact:data:specification:UnqualifiedDataTypesSchemaModule:2"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xsi:schemaLocation="urn:oasis:names:specification:ubl:schema:xsd:Invoice-2 http://docs.oasis-open.org/ubl/os-UBL-2.1/xsd/maindoc/UBL-Invoice-2.1.xsd" />
'''
root = ET.XML(invoiceText)
set_path_value(root, ['cbc:UBLVersionID'], '2.1', 'Code')
for i in range(1, len(reviced_rows)):
record = reviced_rows[i]
if DEBUG:
elements = [f"{reviced_rows[0][i]}:{pintDict[reviced_rows[0][i].replace('G','ibg-')]['BT']} {record[i]}"
for i in range(len(record)) if record[i]]
print('\n'.join(elements))
set_record(record)
writeET(root,out_file)
if VERBOSE:
print(f'** END ** {out_file}')__init__.py
# print("Load pint_ja/generate_ubl/dic2etree/__init__.py")
from .dic2etree import dict_to_etree
from .dic2etree import etree_to_dict
ns = {
'': 'urn:oasis:names:specification:ubl:schema:xsd:Invoice-2',
'xsd': 'http://www.w3.org/2001/XMLSchema',
'xsi': 'http://www.w3.org/2001/XMLSchema-instance',
'cac': 'urn:oasis:names:specification:ubl:schema:xsd:CommonAggregateComponents-2',
'cbc': 'urn:oasis:names:specification:ubl:schema:xsd:CommonBasicComponents-2',
'qdt': 'urn:oasis:names:specification:ubl:schema:xsd:QualifiedDataTypes-2',
'udt': 'urn:oasis:names:specification:ubl:schema:xsd:UnqualifiedDataTypes-2',
'ccts': 'urn:un:unece:uncefact:documentation:2',
'cn': 'urn:oasis:names:specification:ubl:schema:xsd:CreditNote-2',
'ubl': 'urn:oasis:names:specification:ubl:schema:xsd:Invoice-2',
'sch': 'http://purl.oclc.org/dsdl/schematron'
}
__all__ = ['dict_to_etree', 'etree_to_dict', 'ns']
XML文書とPython辞書データの変換プログラム
# print("Load dic2etree.py")
import xml.etree.ElementTree as ET
# import defusedxml.ElementTree as ET
from collections import defaultdict
# import csv
import pprint
ET.register_namespace('cac', 'urn:oasis:names:specification:ubl:schema:xsd:CommonAggregateComponents-2')
ET.register_namespace('cbc', 'urn:oasis:names:specification:ubl:schema:xsd:CommonBasicComponents-2')
ET.register_namespace('qdt', 'urn:oasis:names:specification:ubl:schema:xsd:QualifiedDataTypes-2')
ET.register_namespace('udt', 'urn:oasis:names:specification:ubl:schema:xsd:UnqualifiedDataTypes-2')
ET.register_namespace('ccts', 'urn:un:unece:uncefact:documentation:2')
ET.register_namespace('', 'urn:oasis:names:specification:ubl:schema:xsd:Invoice-2')
# https://stackoverflow.com/questions/7684333/converting-xml-to-dictionary-using-elementtree
def etree_to_dict(t):
d = {t.tag: {} if t.attrib else None}
children = list(t)
if children:
dd = defaultdict(list)
for dc in map(etree_to_dict, children):
for k, v in dc.items():
dd[k].append(v)
d = {t.tag: {k: v[0] if len(v) == 1 else v
for k, v in dd.items()}}
if t.attrib:
d[t.tag].update(('@' + k, v)
for k, v in t.attrib.items())
if t.text:
text = t.text.strip()
if children or t.attrib:
if text:
d[t.tag]['#text'] = text
else:
d[t.tag] = text
return d
def dict_to_etree(d, root):
def _to_etree(d, root):
if not d:
pass
elif isinstance(d, str):
root.text = d
elif isinstance(d, dict):
for k,v in d.items():
assert isinstance(k, str)
if k.startswith('#'):
try:
assert k == '#text' and isinstance(v, str)
root.text = v
except (Exception, ValueError, TypeError) as e:
print(e, v)
elif k.startswith('@'):
if isinstance(v, str): # 2021-06-05
root.set(k[1:], v)
else:
pass
elif isinstance(v, list):
for e in v:
_to_etree(e, ET.SubElement(root, k))
else:
_to_etree(v, ET.SubElement(root, k))
else:
assert d == 'invalid type', (type(d), d)
assert isinstance(d, dict) and len(d) == 1
tag, body = next(iter(d.items()))
_to_etree(body, root)
return root
エラー箇所
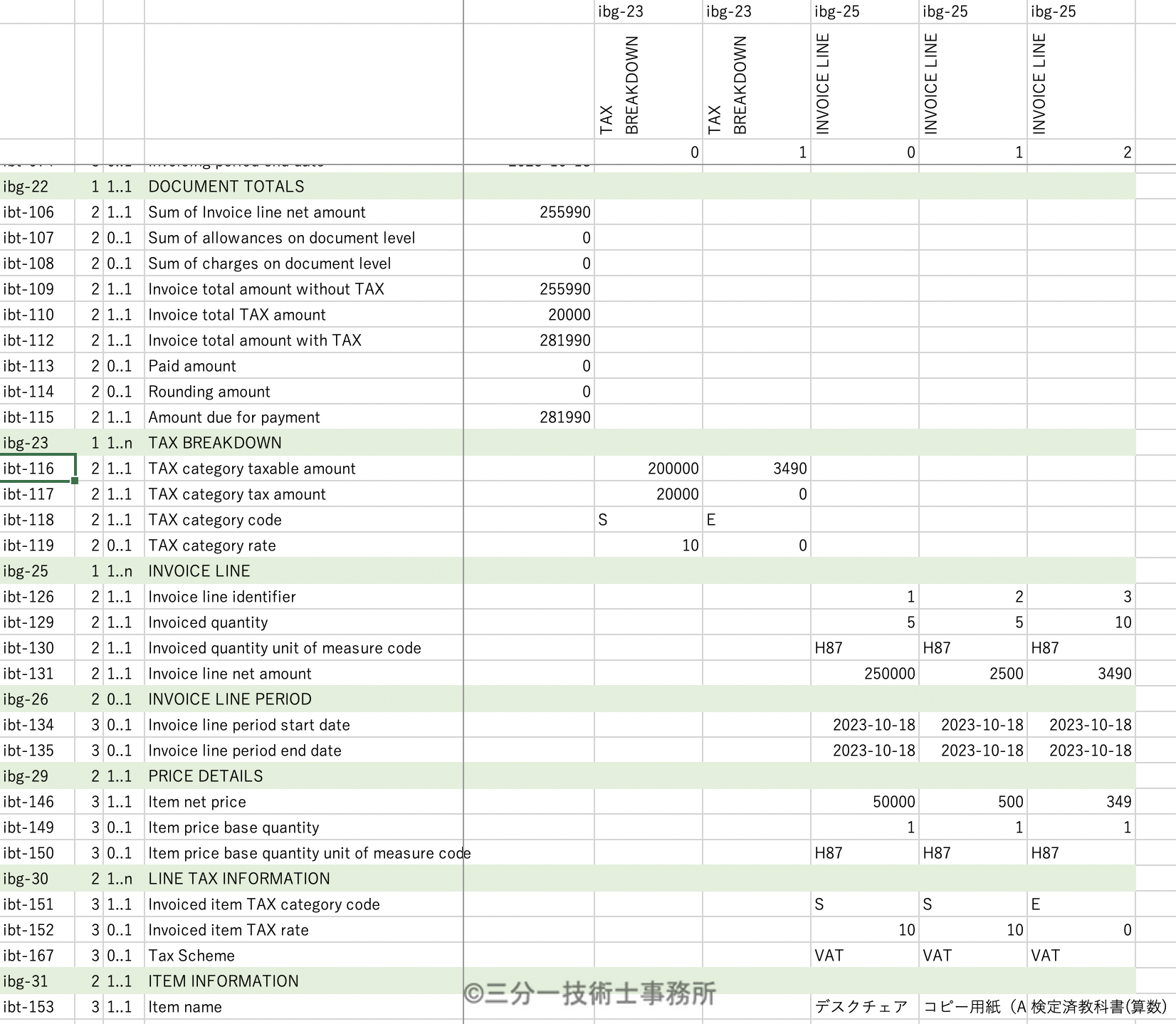
PINT-UBL-validation-preprocessed.schでスキーマトロンチェックしたところ、次のメッセージでした。
[ibr-co-15]-Invoice total amount with Tax (ibt-112) = Invoice total amount without Tax (ibt-109) + Invoice total Tax amount (ibt-110).
これは、税込合計金額の計算が間違っているということですから、検算してみると。
ibt-109 + ibt-110 = 255990 + 20000 = 275990 ですから、ibt-112に記載された281990が間違っていました。
ibt-112を275990に訂正したところ、今度は、
[ibr-co-16]-Amount due for payment (ibt-115) = Invoice total amount with Tax (ibt-112) – Paid amount (ibt-113) + Rounding amount (ibt-114).
ibt-112だけでなくibt-115も同様の訂正が必要でした。
今度は、Validation sucsessfulです。
さて、他の箇所は大丈夫でしょうか?税額計算は、ibt-116課税対象金額 200000に標準税率10%をかけた金額20000ですから正しそうです。
標準税率10%の明細行は、250000 + 2500 = 252500 ですので、ibt-116課税対象金額は、 200000でなく252500でなければなりません。
JP PINT 0.9.3では、BIS Billing 3.0で提供されていた、税率ごとの明細行の請求金額の合計計算についてのチェックが提供されていません。
このため、C4での検算が不可欠となっています。
詳しくは、BIS Billing 3.0からJP PINT 0.9.3に引き継がれなかった検証ルールをお読みください。
