
Views: 0
ペポル時代の国内既存EDI連携と日本版コアインボイス(構造化CSV)
2026-06-21
1. はじめに
前稿 では,マーケットプレイス,業界EDI,卸売市場,農協等,流通業の仕入明細書等をペポル/JP PINTへ接続する場合に,SBDH Sender/Receiver と payload 側 Party/EndpointID をどのように整合させるべきかを整理した。
特に重要な点は,SBDH Sender が単なる技術的送信者ではないことである。通常のJP PINT Invoiceでは,SBDH Sender は原則として Seller / AccountingSupplierParty に対応し,JP BIS Self Billing Invoiceでは,SBDH Sender は Buyer / AccountingCustomerParty に対応する。
したがって,EDIプロバイダー,マーケットプレイス,購買プラットフォーム又は卸売市場が技術的に送信しているという理由だけで,それらのペポル IDをSBDH Sender又はReceiverに記載できるわけではない。
本稿では,この議論を一歩進めて,ペポルを日本国内の既存EDI連携における共通の相互接続ネットワークとして位置付ける可能性を検討する。
ここでいう既存EDIには,流通BMS,中小企業共通EDI,業界EDI,Web-EDI,購買プラットフォーム,販売管理システム,会計システム,さらに支払・消込領域のZEDI等を含めて考える。
また,本稿では,ペポル/JP PINTと既存EDIを直接相互変換するのではなく,EN 16931を参考にした日本版コアインボイスを定義し,その標準実装形式として構造化CSVを用いる構成を提案する。
本稿の基本的な整理は,次のとおりである。
ペポル:
国内外の取引先へ文書を届ける相互接続ネットワーク
JP PINT:
ペポル上で送信する日本向け電子インボイス構文
日本版コアインボイス(構造化CSV):
JP PINT,既存EDI,Web-EDI,ERP,会計,販売管理をつなぐ同時通訳モデル
2. 問題の所在:標準フォーマットだけでは到達性は保証されない
国内のEDIでは,長年にわたり,業界ごと,取引グループごと,プロバイダーごとに標準化が進められてきた。
代表例として,流通BMSは,小売,卸,メーカー間の取引で利用される標準メッセージ及び通信手順を提供している。通信手順としては,AS2,ebMS,JX手順等が用いられる。
また,中小企業共通EDIは,中小企業が多様な取引先と電子的に受発注等を行うため,業界横断的な共通EDIメッセージとプロバイダー間連携を志向している。
しかし,ここで注意すべきことがある。
標準メッセージがあることと,任意の取引先に到達できることは別問題である。
例えば,ある中小企業が取引先AとはプロバイダーX経由で接続し,取引先BとはプロバイダーY経由で接続し,取引先Cとは個別のWeb-EDIにログインするという状況が生じる。この場合,データ項目又はXML形式がある程度標準化されていても,利用者から見ると,取引先ごと,プロバイダーごと,ポータルごとの個別対応が残る。
つまり,問題は次の二つに分けられる。
| 論点 | 内容 |
|---|---|
|
構文・メッセージの標準化 |
どの項目を,どのXML,CSV,JSON,固定長等で表すか。 |
|
配送・到達性の標準化 |
どのプロバイダーから,どの相手先プロバイダー又は利用者に,標準的な方法で到達できるか。 |
従来のEDI標準は,前者には対応していても,後者を十分に解決していないことが多い。
3. ペポルを相互接続ネットワークとして捉える
3.1. 同時通訳としてのペポル
ペポルは,単一の中央サーバーに全ての文書を集める仕組みではない。
ペポルの基本構造は,4コーナーモデルである。
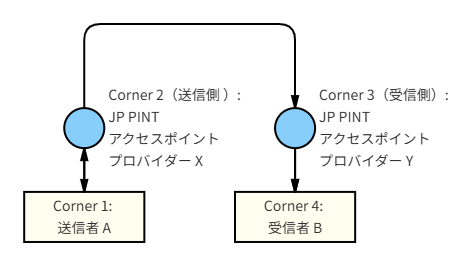
この構成では,送信者と受信者は,それぞれ自分が選択したAccess Pointに接続する。そして,Access Point間の相互接続により,送信者は受信者が契約しているAccess Pointを個別に意識せずに文書を送信できる。
したがって,ペポルは,標準化された相互接続ネットワークである。
一方,日本国内の既存EDI連携で必要となるのは,単なる配送だけではない。
JP PINT,中小企業共通EDI,流通BMS,業界EDI,Web-EDI,ERP,会計,販売管理では,それぞれ項目名,コード体系,データ粒度,業務上の意味が異なる。これらを単純に項目変換するだけでは,Seller,Buyer,Supplier,Customer,Payee,Tax Representative,EndpointID,適格請求書登録番号,取引先コード等の意味を正しく対応させることができない。
このため,日本版コアインボイス(構造化CSV)は,国内既存EDIとペポル/JP PINTをつなぐ「同時通訳モデル」として位置付けるのが適切である。
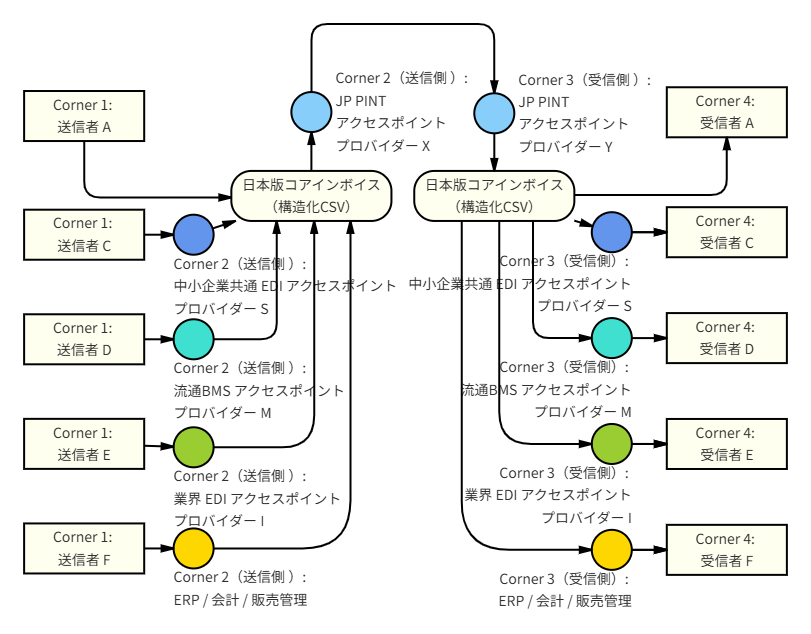
ここで,日本版コアインボイス(構造化CSV)は,単なる中間ファイルではない。
それぞれのEDIや業務システムが持つ項目を,請求書としての共通の意味に対応付けるためのセマンティックモデルである。
すなわち,日本版コアインボイス(構造化CSV)は,次の役割を担う。
| 役割 | 内容 |
|---|---|
|
意味の通訳 |
既存EDIの項目を,Seller,Buyer,Invoice Line,Tax Breakdown,Payment,Document Reference等の共通概念に対応付ける。 |
|
構文の通訳 |
CSV,XML,API,ERPデータ,JP PINT UBL等の異なる構文を相互に変換する。 |
|
コードの通訳 |
取引先コード,店舗コード,商品コード,税区分コード,支払方法コード等を共通コード又は対応表により変換する。 |
|
IDの通訳 |
ペポル Participant ID,法人番号,適格請求書登録番号,既存EDI利用者ID,社内取引先コードを対応付ける。 |
|
業務文脈の通訳 |
売手発行請求書,買手作成仕入明細書,月次締め,検収起点請求,媒介者交付特例等の違いを正しく扱う。 |
|
証跡の通訳 |
既存EDIの送受信記録,ペポルの送達記録,ERPの承認記録,支払・消込情報を関連付ける。 |
この意味で,ペポルは文書を届ける相互接続ネットワークであり,日本版コアインボイス(構造化CSV)は,国内既存EDIとペポル/JP PINTの間で意味を通訳する共通モデルである。
3.2. 流通BMSとの関係
流通BMSは,流通業における受発注,出荷,受領,返品,請求等の取引メッセージを標準化してきた重要な仕組みである。
しかし,ペポルのように,任意のAccess Point間で相互接続し,相手先のペポル IDをもとに到達性を解決するネットワークモデルとは異なる。
したがって,流通BMS利用企業が契約しているEDIサービスと,相手先が利用しているEDIサービスが異なり,そのプロバイダー間に中継又は相互接続の取り決めがない場合には,個別接続が必要となる可能性がある。
この課題は,次のように整理できる。
| 観点 | 流通BMS | ペポル型4コーナーモデル |
|---|---|---|
|
標準化対象 |
業務メッセージ及び通信手順 |
業務メッセージ,参加者識別,配送,AP間相互接続 |
|
通信方式 |
AS2,ebMS,JX手順等 |
ペポル eDelivery / AS4等 |
|
相手先解決 |
取引先・プロバイダーごとの設定が中心 |
ペポル Participant IDとSMP/SML等による宛先解決 |
|
プロバイダー変更 |
相手先又はプロバイダーごとに調整が必要となる場合がある |
送受信者はそれぞれ自分のAPを選択できる |
|
中小企業側の負担 |
取引先ごとに異なるWeb-EDI又はEDIサービス対応が残る可能性 |
原則として自社AP接続を通じて他AP利用者へ到達可能 |
このため,流通BMSを直ちにペポルへ置き換えるのではなく,まずは請求書,仕入明細書,支払通知,消込参照等の領域からペポルと連携させるのが現実的である。
流通BMS:
受発注,出荷,受領,返品,検収等
ペポル / JP PINT:
請求書,仕入明細書,請求関連参照
日本版コアインボイス(構造化CSV):
流通BMSとJP PINTの間の同時通訳モデル
ZEDI:
支払,入金消込,請求書番号・支払通知番号等の決済連携
3.3. 中小企業共通EDIとの関係
中小企業共通EDIは,流通BMSよりも明確に,プロバイダー間連携を意識している。多プロバイダー問題を防止し,複数の共通EDIプロバイダー間を多対多に接続することを目指している。
この点では,中小企業共通EDIは,ペポルの4コーナーモデルに近い問題意識を持つ。
しかし,中小企業共通EDIのプロバイダー間連携は,ペポルとは別のネットワーク及び連携方式である。したがって,ペポルと同様の国際的なAccess Point制度,Participant ID,SMP/SML,認定Service Provider制度,統一的な到達性管理がそのまま整備されているわけではない。
このため,中小企業共通EDIとペポルの関係は,次のように整理するのがよい。
| 方式 | 整理 |
|---|---|
|
中小企業共通EDIを独立ネットワークとして維持する |
既存の共通EDIプロバイダー間連携を発展させる。ただし,ペポル利用者との接続は別途ゲートウェイが必要となる。 |
|
共通EDIプロバイダーがペポル AP機能を持つ |
共通EDI利用者を,必要に応じてペポル Participantとして登録し,JP PINT又は他のペポル文書へ変換して送受信する。 |
|
共通EDIプロバイダーがペポル APと接続する |
共通EDIプロバイダー自身はAPでなくても,認定APと連携することで,ペポルネットワークへの出入口となる。 |
|
ペポルを共通EDIプロバイダー間の上位相互接続層として使う |
共通EDI独自のプロバイダー間接続を拡張する代わりに,ペポルを国内外の共通到達性基盤として利用する。 |
中小企業共通EDIが抱えていた「多プロバイダー問題」は,ペポルが解決しようとしている問題に近い。したがって,中小企業共通EDIをペポルと競合する別ネットワークとして見るのではなく,ペポルへ接続する国内業務ゲートウェイとして位置付けることが考えられる。
その際,日本版コアインボイス(構造化CSV)は,中小企業共通EDIとJP PINTの間で,項目,意味,コード,ID,業務文脈を通訳する役割を担う。
3.4. 3+1モデルの限界とペポル型相互接続
国内でしばしば見られるプロバイダー接続モデルは,実質的に3+1モデルである。
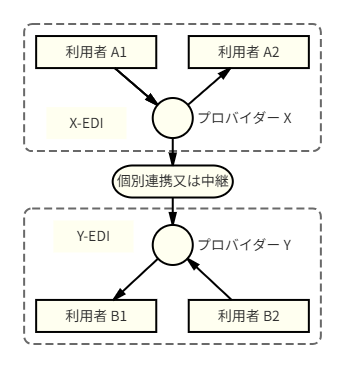
この構成では,一見するとプロバイダー間接続があるように見える。しかし,実際には,プロバイダーXとYの間に個別契約,個別設定,個別ID対応,個別フォーマット変換が必要となることが多い。
この構造は,20世紀のBBS型ネットワークに近い。各BBSの内部では標準的に利用できても,隣のBBSにメッセージを届けるには,個別のゲートウェイ又は相互接続対応が必要となる。
これに対して,ペポル型の4コーナーモデルでは,次の原則が重要である。
-
送信者は自分のAccess Pointを選べる。
-
受信者も自分のAccess Pointを選べる。
-
Access Point間は標準的に相互接続される。
-
受信者の到達性はParticipant IDにより解決される。
-
技術的送信者ではなく,business sender/receiverが文書上で識別される。
この違いは,中小企業にとって特に重要である。
中小企業が取引先ごとに別々のWeb-EDI,別々のEDIプロバイダー,別々のポータルに対応し続けるのであれば,デジタル化の効果は限定的である。ペポルを共通配送基盤として使えば,中小企業は自社が選択したプロバイダー又は業務アプリケーションを通じて,多様な取引先と接続できる可能性がある。
ただし,配送だけでは十分ではない。異なるEDIや業務システムの意味を通訳する共通モデルが必要である。その役割を担うのが,日本版コアインボイス(構造化CSV)である。
3.5. 欧州ViDAから得られる示唆
欧州のViDA(VAT in the Digital Age)は,日本でペポルを国内既存EDI連携基盤として検討するうえで重要な参考事例である。
ViDAは,単に電子インボイスのファイル形式を定めるものではない。電子インボイスとデジタル報告要件(Digital Reporting Requirements, DRR)を組み合わせ,VAT報告のリアルタイム化又は準リアルタイム化を進める制度的枠組みである。
ここで重要なのは,欧州全体で単一の中央EDIシステムを作るのではなく,次のような多層構造で進んでいることである。
EU ViDA:
VAT制度,電子インボイス,デジタル報告要求
EN 16931:
電子インボイスの共通セマンティック標準
ペポル:
事業者・サービスプロバイダー間の相互接続ネットワーク
各国制度・国内プラットフォーム:
国内税務報告,既存制度,認定プラットフォーム,政府ポータル等
企業側ERP・会計・既存EDI:
実務処理,取引先固有業務,業界慣行
ペポル ViDA Pilotでは,ペポル eInvoice仕様及びペポル Networkが,ViDA下のeInvoicing及びDRRに対応できることを実証することが目的とされている。
ここから得られる示唆は,次の点である。
| 示唆 | 日本での意味 |
|---|---|
|
電子インボイスは単独ではなく,税務報告・監査証跡と結び付く |
JP PINTを請求書交換だけでなく,支払,消込,監査証跡,税務データ連携と接続する必要がある。 |
|
ペポルは既存システムを全て置換しない |
流通BMS,中小企業共通EDI,業界EDI,ERP,会計システムを残しつつ,その間の共通相互接続層として使う。 |
|
各国制度との接続が必要 |
日本では適格請求書制度,仕入明細書等,代理交付,媒介者交付特例,卸売市場特例,農協等特例との整合が必要である。 |
|
送信者・受信者・売手・買手の識別が重要 |
SBDH Sender/Receiver,payload EndpointID,法人番号,適格請求書登録番号,既存EDI取引先コードを明確に対応付ける必要がある。 |
|
共通セマンティックモデルが必要 |
JP PINT,既存EDI,ERP,会計,支払,消込,監査データの意味を接続する日本版コアインボイスが必要である。 |
|
5コーナー又は6コーナーモデルへの発展可能性 |
将来,税務当局又は公的データ連携基盤が,ペポル交換データ又は派生データを受け取る可能性を考慮する必要がある。 |
日本においても,ペポルを単なる請求書XMLの送信手段として扱うのではなく,既存EDI,税務,決済,監査証跡を接続する相互運用基盤として考えるべきである。
3.6. EN 16931から学ぶべき点
欧州のEN 16931の重要な点は,電子インボイスを特定のXML構文として定義しているのではなく,まず「core invoice model」というセマンティックデータモデルを定義していることである。
すなわち,
を,特定のファイル形式に先立って定義している。
そのうえで,UBL,CII等の構文に対してsyntax bindingを定義する。
この考え方は,日本国内の既存EDI連携にもそのまま適用できる。
日本では,JP PINT,流通BMS,中小企業共通EDI,業界EDI,Web-EDI,販売管理システム,会計システム等がそれぞれ異なる構文,項目名,コード体系,データ粒度を持っている。これらを個別に相互変換しようとすると,組合せの数だけ変換定義が必要になる。
しかし,日本版コアインボイスを中間の意味モデルとして定義すれば,各システムは相互に直接変換するのではなく,日本版コアインボイスへのbindingを定義すればよい。
4. 日本版コアインボイス(構造化CSV)の位置付け
4.1. 共通論理モデルとして
日本版コアインボイスは,JP PINTの代替仕様ではない。
むしろ,JP PINTをペポルネットワーク上の正式な配送仕様としつつ,その前後,すなわちC1-C2間及びC3-C4間の業務システム連携で利用する共通論理モデルとして位置付けるべきである。
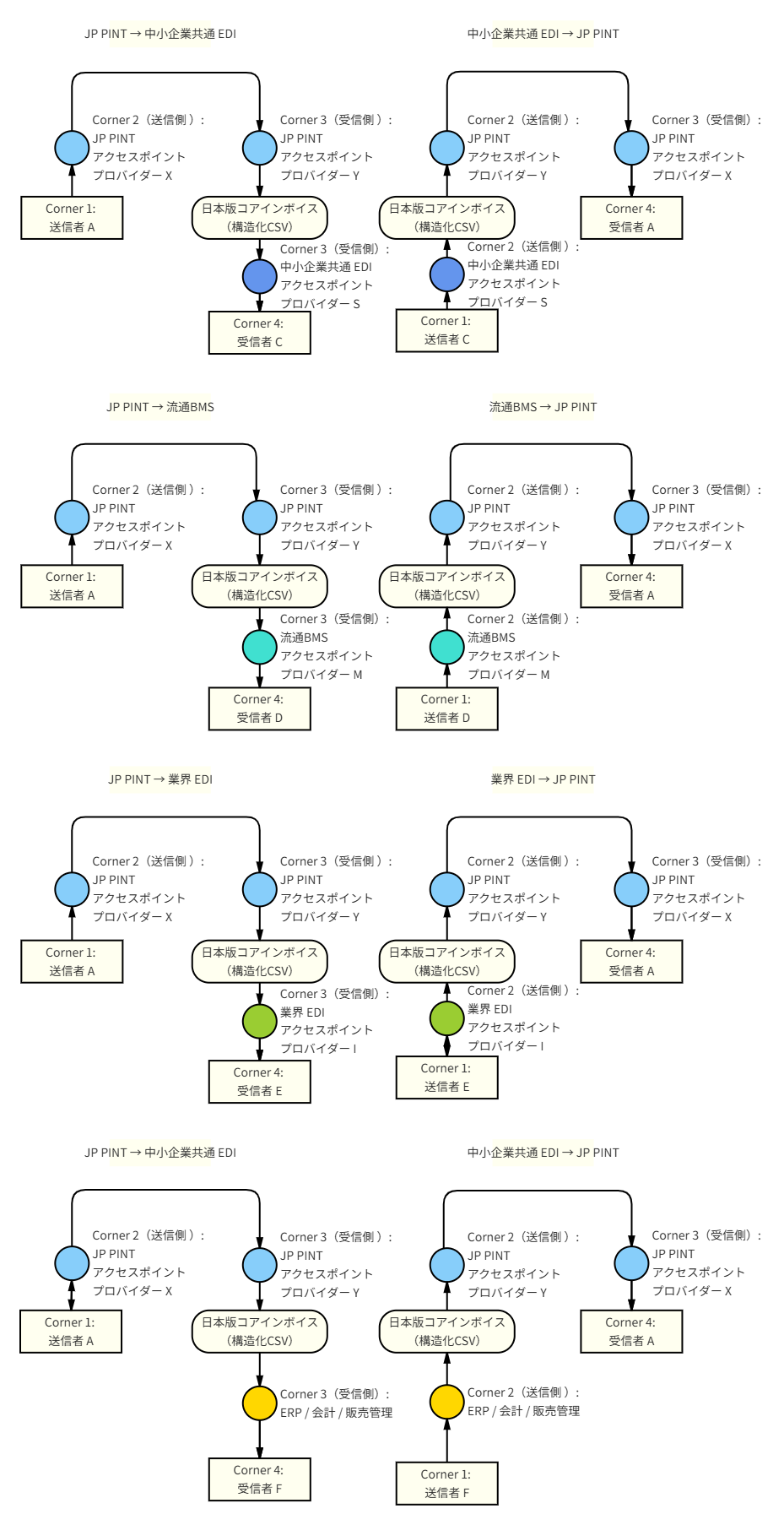
ペポルの標準が直接規定するのは,主としてC2-C3間の文書交換である。一方,C1-C2及びC3-C4間では,各国,各業界,各サービスプロバイダー,各業務アプリケーションの実装差異が残る。
この差異を吸収するために,日本版コアインボイスを定義し,その標準実装形式として構造化CSVを用いる。
ここで重要なのは,日本版コアインボイス(構造化CSV)を単なる中間ファイル形式としてではなく,国内電子インボイス連携の共通論理モデルとして位置付けることである。
この構成では,JP PINT,中小企業共通EDI,流通BMS,業界EDI,Web-EDI,ERP,会計,販売管理を相互に総当たりで変換する必要はない。
各形式は,日本版コアインボイス(構造化CSV)との対応関係だけを定義する。
JP PINTはペポルネットワークで配送するための標準構文であり,日本版コアインボイス(構造化CSV)は,ペポルの前後で既存EDI及び業務システムと接続するための国内共通データ表現である。
4.2. 日本版コアインボイスゲートウェイ
日本版コアインボイスゲートウェイは,ペポル Access Pointと,利用者向けパッケージ,業務アプリケーション,業界EDIサービス,Web-EDI等との間を接続するための仕組みである。
ここで対象となるのは,主としてC1-C2間及びC3-C4間のメッセージ交換である。この領域はペポルネットワークそのものの標準配送範囲ではなく,国内の業務システム,EDIサービス,パッケージベンダー,サービスプロバイダーが実装する接続領域である。
日本版コアインボイスゲートウェイでは,構文バインディングを用いて,各構文を日本版コアインボイスのセマンティックモデルに対応付ける。
この構成では,日本版コアインボイス(構造化CSV)は,単なるファイル変換の中間形式ではない。各構文に含まれる項目を,請求書としての共通概念に対応付けるための意味モデルである。
また,日本版コアインボイスのsyntax bindingをXBRLタクソノミで定義し,構造化CSVをxBRL-CSVとして表現することで,構造,意味,データ型,コード,検証規則をタクソノミとして管理できる。
これにより,システムごとの個別変換を積み上げるのではなく,変換仕様の維持管理をタクソノミの維持管理と連動させることができる。
4.3. 構造化CSVを採用する理由
中小企業や既存業務システムとの連携を考えると,XMLやJSONだけでは十分ではない。
多くの中小企業では,依然としてCSV,Excel,販売管理ソフト,会計ソフト,業務パッケージ,RPA,簡易データ連携ツールが実務の中心である。このため,ペポル/JP PINTの普及には,XMLを直接扱うだけでなく,CSVとして読み書きできる標準的な入出力形式が有効である。
ただし,ここでいう構造化CSVは,従来のように正規化された複数のテーブルをCSVとして出力し,必要に応じてJOIN操作で再構成する方式ではない。
従来の正規化モデルでは,例えば請求書ヘッダー,売手,買手,税率別内訳,明細行,支払条件,参照文書を,それぞれ別々のテーブルとして保持する。
invoice.csv
party.csv
tax_breakdown.csv
invoice_line.csv
allowance_charge.csv
document_reference.csv
payment.csv
この方式では,データベースとしては正規化されていても,利用者が請求書全体を扱うには,各テーブルをキーで結合する必要がある。すなわち,請求書ID,明細ID,税内訳ID,当事者ID等を用いたJOIN操作が必要となる。
これは,中小企業,Excel利用者,Pandas利用者,業務アプリケーション間のファイル連携にとっては重い。
本稿でいう構造化CSVは,この方式ではない。
構造化CSVは,請求書の階層構造を保持したまま,1枚のCSVとして表現する。ヘッダー,税率別内訳,明細行,支払情報,参照文書等は別テーブルに分割するのではなく,同一CSV内の行として表現し,階層を示すディメンション又は連番によって関連付ける。
日本版コアインボイス(構造化CSV)= 1枚のCSVに,請求書ヘッダー,税率別内訳,明細行,支払情報,参照文書等を保持する形式
この形式であれば,Pandas等のライブラリで1つのCSVファイルを読み込み,record_type,dInvoice,dTaxBreakdown,dInvoiceLine 等の列を条件として抽出するだけで,必要なデータを取得できる。
JOIN操作を前提にした正規化データではなく,階層構造を持ったままフラットな表として処理できる点が,構造化CSVの特徴である。
4.4. Ledger Explorerにおける構造化CSVの考え方
構造化CSVの考え方は,Ledger Explorerのデモにも表れている。
Ledger Explorerでは,構造化CSV,すなわち階層型のtidy dataを基礎データとして位置付けている。仕訳帳,総勘定元帳,試算表,貸借対照表,損益計算書などの表示は,別々の意味を持つデータを再作成しているのではなく,同じ構造化CSVデータから導出される表示である。
この考え方は,請求書データにもそのまま適用できる。
すなわち,日本版コアインボイス(構造化CSV)をsource of truthとし,そこから必要に応じて次の表示又は構文を生成する。
日本版コアインボイス(構造化CSV) -> JP PINT UBL -> 中小企業共通EDI -> 流通BMS向けデータ -> 業界EDI向けデータ -> ERP取込データ -> 会計仕訳 -> 消込データ -> 監査データ
ここで重要なのは,表示形式や出力形式が複数あっても,意味の基礎は同一の構造化CSVにあるという点である。
Ledger Explorerでは,Structured CSV viewが基礎となり,Journal,General Ledger,Trial Balance,Balance Sheet,Profit and Loss等の表示は同じデータセットから導出される。この方式により,複雑なJOINで意味を再構成するのではなく,構造化CSVに保持された文脈をもとに複数の表現を生成できる。
請求書でも同様に,日本版コアインボイス(構造化CSV)を基礎データとすれば,JP PINT,既存EDI,ERP,会計,支払,消込,監査データを,同じ意味モデルから生成又は受入れできる。
5. 請求書の構造化CSV
5.1. 構造化CSVとは
日本版コアインボイスを構造化CSVとして表現する場合,重要なのは,請求書データを正規化された複数テーブルに分解しないことである。
従来のデータベース設計では,請求書を次のような複数テーブルとして管理することが多い。
invoice_header invoice_party invoice_tax_breakdown invoice_line invoice_line_tax invoice_payment invoice_reference
この方式では,請求書全体を再構成するために,請求書番号,明細番号,税内訳番号,当事者番号等をキーとしてJOIN操作を行う必要がある。
しかし,構造化CSVの目的は,このような正規化テーブル群をCSVとして外部出力することではない。
構造化CSVは,請求書が本来持っている階層構造を保持したまま,1枚のCSVにフラットに展開する形式である。
請求書
├─ 売手
├─ 買手
├─ 税率別内訳
├─ 支払情報
├─ 参照文書
└─ 請求明細
├─ 品目
├─ 数量・単価・金額
└─ 明細税情報
この階層を,複数のCSVファイルに分割するのではなく,1枚のCSVの中で,ディメンション列と連番によって表現する。
5.2. xBRL-CSVに基づく構造
構造化CSVは,xBRL-CSVの考え方に基づく。
CSV本体には,請求書番号,明細番号,税内訳番号などのディメンション列と,金額,日付,コード,名称,数量などの事実列を記録する。
JSONメタデータには,CSV列の意味,データ型,ディメンション,タクソノミ上のコンセプトとの対応を定義する。
CSV:
実データを記録する1枚の表
JSONメタデータ:
列の意味,ディメンション,データ型,タクソノミ対応を定義
XBRLタクソノミ:
概念,ラベル,定義,コード,検証規則を定義
この構成により,CSVは単なる文字列の表ではなく,意味を持った構造化データとなる。
5.3. 請求書構造化CSVの例
次は,日本版コアインボイスを1枚の構造化CSVとして表現した簡略例である。
dInvoice,dInvoiceParty,dDocumentReference,dPayment,dTaxBreakdown,dInvoiceLine,invoiceNumber,issueDate,invoiceTypeCode,currencyCode,totalAmount,partyRole,partyName,partyTaxID,referenceType,referenceID,paymentDueDate,paymentMeansCode,paymentReference,taxCategoryCode,taxRate,taxableAmount,taxAmount,lineID,itemName,lineTaxCategoryCode,lineTaxRate,invoicedQuantity,unitCode,unitPriceAmount,lineExtensionAmount
1,,,,,,INV-26-861,2026-06-20,380,JPY,16802,,,,,,,,,,,,,,,,,,,,
1,1,,,,,,,,,,Seller,売手株式会社,T1234567890123,,,,,,,,,,,,,,,,,
1,2,,,,,,,,,,Buyer,買手株式会社,,,,,,,,,,,,,,,,,,
1,,1,,,,,,,,,,,,Order,PO-2026-0001,,,,,,,,,,,,,,,
1,,2,,,,,,,,,,,,Delivery,DN-2026-0001,,,,,,,,,,,,,,,
1,,,1,,,,,,,,,,,,,2026-07-31,30,INV-2026-0001,,,,,,,,,,,,
1,,,,1,,,,,,,,,,,,,,,S,10,12320,1232,,,,,,,,
1,,,,1,,,,,,,,,,,,,,,AA,8,3010,240,,,,,,,,
1,,,,,1,,,,,,,,,,,,,,,,,,INV-26-861-1,商品A,S,10,10,EA,1000,10000
1,,,,,2,,,,,,,,,,,,,,,,,,INV-26-861-2,商品B,S,10,4,EA,580,2320
1,,,,,3,,,,,,,,,,,,,,,,,,INV-26-861-3,食品C,AA,8,7,EA,430,30105.4. 構造化CSVの基本構造
構造化CSVでは,1行に1つの事実又は観測値を記録する。
各行は,その事実が請求書ヘッダーに属するのか,税率別内訳に属するのか,明細行に属するのか,支払情報に属するのかを,ディメンション列で示す。
例えば,次のような列を用いる。
| 列 | 意味 |
|---|---|
|
record_type |
行の種類。Invoice,Seller,Buyer,TaxBreakdown,InvoiceLine,Payment,DocumentReference等。 |
|
dInvoice |
請求書を識別する連番又はID。すべての行がどの請求書に属するかを示す。 |
|
dTaxBreakdown |
税率別内訳を識別する連番。税率別内訳行の場合に使用する。 |
|
dInvoiceLine |
請求明細行を識別する連番。明細行の場合に使用する。 |
|
dDocumentReference |
参照文書を識別する連番。注文,納品,検収,支払通知等への参照で使用する。 |
|
name |
項目名又は概念名。 |
|
value |
値。 |
|
datatype |
値のデータ型。Amount,Quantity,Code,Identifier,Date等。 |
|
unit |
数量の単位又は金額の通貨。 |
このように,階層を表す列と,値を表す列を同じCSV内に保持する。
このCSVでは,請求書ヘッダー,売手,買手,税率別内訳,請求明細,明細税情報,参照文書,支払情報が,すべて1枚のCSVに記録されている。
重要なのは,空欄を許容している点である。すべての行がすべての列に値を持つ必要はない。
例えば,請求書ヘッダー行では,invoiceNumber,issueDate,invoiceTypeCode,currencyCode に値が入る。一方,明細行では,lineID,itemName,invoicedQuantity,unitPriceAmount,lineExtensionAmount に値が入る。
それぞれの行は,dInvoice,dInvoiceLine,dTaxBreakdown 等のディメンションによって,どの階層に属するかが示される。
5.5. Pandasによる読込み
この形式であれば,Python Pandas等の一般的なライブラリで,1枚のCSVをそのまま読み込むことができる。
# df = pd.read_csv("core_invoice.csv")
df = pd.read_csv("/Users/nobuy/OneDrive/ドキュメント/技術士事務所/ホームページ/2026/202606/20260621/src/core_invoice.csv")
# 請求書ヘッダー
invoice_header = df[df["invoiceNumber"].notna()][
["dInvoice", "invoiceNumber", "issueDate", "invoiceTypeCode", "currencyCode"]
]
# 当事者
parties = df[df["dInvoiceParty"].notna()][
["dInvoice", "dInvoiceParty", "partyRole", "partyName", "partyTaxID"]
]
# 税率別内訳
tax_breakdown = df[df["dTaxBreakdown"].notna()][
[
"dInvoice",
"dTaxBreakdown",
"taxCategoryCode",
"taxRate",
"taxableAmount",
"taxAmount",
]
]
# 請求明細
lines = df[df["dInvoiceLine"].notna() & df["lineID"].notna()][
[
"dInvoice",
"dInvoiceLine",
"lineID",
"itemName",
"lineTaxCategoryCode",
"lineTaxRate",
"invoicedQuantity",
"unitCode",
"unitPriceAmount",
"lineExtensionAmount",
]
]
# 参照文書
references = df[df["dDocumentReference"].notna()][
["dInvoice", "dDocumentReference", "referenceType", "referenceID"]
]
# 支払情報
payments = df[df["dPayment"].notna()][
["dInvoice", "dPayment", "paymentDueDate", "paymentMeansCode", "paymentReference"]
]この処理では,複数CSVを読み込んでJOINする必要はない。
請求書全体が1枚のCSVに保持されており,必要な部分を列とディメンションで抽出するだけでよい。
5.6. JOINではなくフィルタとグループ化で扱う
構造化CSVでは,請求書ヘッダー表と明細表をJOINして請求書を復元するのではない。
すでに1枚のCSVの中に,請求書と明細の関係が保持されている。
例えば,明細行は dInvoice と dInvoiceLine で識別できる。
# 明細行
for line_no, group in lines.groupby("dInvoiceLine"):
item_name = group["itemName"].iloc[0]
quantity = group["invoicedQuantity"].iloc[0]
amount = group["lineExtensionAmount"].iloc[0]
print(line_no, item_name, quantity, amount)税率別内訳は dTaxBreakdown で抽出できる。
# 税率別内訳
tax_summary = tax_breakdown.groupby(["taxCategoryCode", "taxRate"], as_index=False)[
["taxableAmount", "taxAmount"]
].sum()
print(tax_summary)このように,構造化CSVでは,JOINではなく,フィルタ,グループ化,ピボット,集計によってデータを扱う。
これは,Excel,Pandas,R,BIツール,ETLツールとの相性がよい。
5.7. 構造化CSVの検証例(税率別の税額)
構造化CSVでは,請求書ヘッダー,税率別内訳,請求明細が1枚のCSVに含まれている。
そのため,請求明細の金額を税区分・税率別に集計し,文書に記載されている税率別内訳と比較する処理を,Pandasで簡潔に記述できる。
ここでは,上記の構造化CSVを対象とする。
このCSVでは,税率別内訳は dTaxBreakdown を持つ行として記録され,請求明細は dInvoiceLine を持つ行として記録されている。
したがって,1枚のCSVから次の二つを抽出すればよい。
| 抽出対象 | 条件 |
|---|---|
|
税率別内訳 |
|
|
請求明細 |
|
5.8. Pythonによる検証
次のPythonプログラムは,構造化CSVを1枚読み込み,明細行を税区分・税率別に合計し,文書に記載された税率別内訳と比較する。
import numpy as np
import pandas as pd
# 構造化CSVを1枚読み込む
df = pd.read_csv("2026/202606/20260621/src/core_invoice.csv")
# 税率別内訳
tax_breakdown = df[df["dTaxBreakdown"].notna()][
[
"dInvoice",
"dTaxBreakdown",
"taxCategoryCode",
"taxRate",
"taxableAmount",
"taxAmount",
]
]
# 請求明細
lines = df[df["dInvoiceLine"].notna() & df["lineID"].notna()][
[
"dInvoice",
"dInvoiceLine",
"lineID",
"itemName",
"lineTaxCategoryCode",
"lineTaxRate",
"invoicedQuantity",
"unitCode",
"unitPriceAmount",
"lineExtensionAmount",
]
]
def verify_tax_breakdown(lines, tax_breakdown):
# 明細行を税区分・税率別に合計し,
# 文書に記載された税率別内訳と比較する。
# 1. 明細行を税区分・税率別に合計する
line_total = (
lines.groupby(
["dInvoice", "lineTaxCategoryCode", "lineTaxRate"], as_index=False
)
.agg(lineTotal=("lineExtensionAmount", "sum"))
.rename(
columns={"lineTaxCategoryCode": "taxCategoryCode", "lineTaxRate": "taxRate"}
)
)
# 2. 文書に記載されている税率別内訳を取り出す
reported = tax_breakdown[
["dInvoice", "taxCategoryCode", "taxRate", "taxableAmount", "taxAmount"]
]
# 3. 明細行合計と記載値を比較する
check = line_total.merge(
reported, on=["dInvoice", "taxCategoryCode", "taxRate"], how="outer"
)
# 4. 税額は,切捨て・切上げ・四捨五入のいずれかに一致すればOK
raw_tax = check["lineTotal"] * check["taxRate"] / 100
check["taxFloor"] = np.floor(raw_tax)
check["taxCeil"] = np.ceil(raw_tax)
check["taxRound"] = np.floor(raw_tax + 0.5)
check["taxableOK"] = check["lineTotal"] == check["taxableAmount"]
check["taxOK"] = (
(check["taxAmount"] == check["taxFloor"])
| (check["taxAmount"] == check["taxCeil"])
| (check["taxAmount"] == check["taxRound"])
)
check["OK"] = check["taxableOK"] & check["taxOK"]
return check
# 検証を実行する
check = verify_tax_breakdown(lines, tax_breakdown)
# 結果を表示する
print(
check[
[
"dInvoice",
"taxCategoryCode",
"taxRate",
"lineTotal",
"taxableAmount",
"taxAmount",
"taxFloor",
"taxCeil",
"taxRound",
"OK",
]
]
)この処理の流れは,次の4段階である。
| 段階 | 内容 |
|---|---|
|
1 |
構造化CSVを1枚読み込む。 |
|
2 |
|
|
3 |
|
|
4 |
明細行から計算した税率別合計と,文書に記載された |
税額については,実務上,端数処理として切捨て,切上げ,四捨五入のいずれもあり得る。
そのため,この例では,次のいずれかに一致すれば税額は正しいものと判定している。
check["taxOK"] = (
(check["taxAmount"] == check["taxFloor"])
| (check["taxAmount"] == check["taxCeil"])
| (check["taxAmount"] == check["taxRound"])
)5.9. 実行結果
実行結果は,次のようになる。
dInvoice taxCategoryCode taxRate lineTotal taxableAmount taxAmount taxFloor taxCeil taxRound OK
0 1 AA 8.0 3010.0 3010.0 240.0 240.0 241.0 241.0 True
1 1 S 10.0 12320.0 12320.0 1232.0 1232.0 1232.0 1232.0 True税区分 AA,税率 8% の明細行合計は 3010 であり,文書に記載された課税対象額 3010 と一致している。
税額は,3010 × 8% = 240.8 である。
この場合,切捨てでは 240,切上げ及び四捨五入では 241 となる。文書に記載された税額は 240 であり,切捨て計算と一致するため,OK は True となる。
税区分 S,税率 10% についても,明細行合計 12320,記載課税対象額 12320,記載税額 1232 が一致している。
5.10. 構造化CSVで処理が簡単になる理由
この例で重要なのは,請求書ヘッダー,税率別内訳,請求明細が,別々のCSVファイルに分かれていないことである。
従来の正規化モデルでは,例えば次のような複数テーブルを用意し,請求書IDや明細IDでJOINして検証する必要がある。
invoice_header.csv invoice_line.csv tax_breakdown.csv
これに対して,構造化CSVでは,すべての情報が1枚のCSVに記録されている。
core_invoice.csv ├─ 請求書ヘッダー行 ├─ 当事者行 ├─ 参照文書行 ├─ 支払情報行 ├─ 税率別内訳行 └─ 請求明細行
そのため,処理は次のように単純になる。
1枚のCSVを読む -> 必要な行を条件で抽出する -> 明細行を groupby で税率別に集計する -> 記載された税率別内訳と merge で比較する -> OK / NG を判定する
このように,構造化CSVは,複数の正規化テーブルをJOINして請求書を復元する方式ではない。
1枚のCSVの中に階層構造を保持したまま,Pandas等の一般的なライブラリで簡単に検証,集計,変換できることが特徴である。
5.11. 正規化CSVとの違い
構造化CSVと正規化CSVの違いは,次のように整理できる。
| 観点 | 正規化CSV | 構造化CSV |
|---|---|---|
|
基本構成 |
複数CSVファイル |
1枚のCSVファイル |
|
階層構造 |
テーブル間の外部キーで表現 |
ディメンション列と連番で表現 |
|
請求書全体の復元 |
JOIN操作が必要 |
1枚のCSVから抽出できる |
|
明細の扱い |
invoice_line.csv等の別表 |
同一CSV内の |
|
税率別内訳の扱い |
tax_breakdown.csv等の別表 |
同一CSV内の |
|
処理方法 |
SQL,merge,JOIN |
filter,groupby,pivot,集計 |
|
利用者 |
データベース設計者向き |
Excel,Pandas,業務アプリ,データ交換向き |
|
意味定義 |
DBスキーマに依存 |
JSONメタデータ及びタクソノミで定義 |
したがって,請求書の構造化CSVは,RDBの外部出力ではない。
請求書の階層構造を保持したまま,1枚のCSVとして交換し,Pandas等で簡単に読み書きできる形式である。
5.12. JP PINTとの対応
ペポルネットワークでは,JP PINT UBLを送信構文として使用する。
一方,C1-C2間及びC3-C4間,すなわち利用者の業務システムとペポル Access Pointとの間では,日本版コアインボイス(構造化CSV)を使用できる。
この場合,日本版コアインボイス(構造化CSV)からJP PINT UBLへのsyntax bindingを定義する。
例えば,次のような対応である。
| 構造化CSV | JP PINT UBL |
|---|---|
|
invoiceNumber |
cbc:ID |
|
issueDate |
cbc:IssueDate |
|
invoiceTypeCode |
cbc:InvoiceTypeCode |
|
currencyCode |
cbc:DocumentCurrencyCode |
|
partyRole = Seller |
cac:AccountingSupplierParty |
|
partyRole = Buyer |
cac:AccountingCustomerParty |
|
partyTaxID |
cac:PartyTaxScheme / cbc:CompanyID |
|
dTaxBreakdown |
cac:TaxTotal / cac:TaxSubtotal |
|
dInvoiceLine |
cac:InvoiceLine |
|
itemName |
cac:Item / cbc:Name |
|
invoicedQuantity |
cbc:InvoicedQuantity |
|
unitPriceAmount |
cac:Price / cbc:PriceAmount |
|
lineExtensionAmount |
cbc:LineExtensionAmount |
|
referenceType = Order |
cac:OrderReference |
|
referenceType = Delivery |
cac:DespatchDocumentReference 又は AdditionalDocumentReference |
|
paymentDueDate |
cac:PaymentTerms 又は cbc:DueDate相当項目 |
|
paymentReference |
cbc:PaymentID 等 |
このように,日本版コアインボイス(構造化CSV)は,JP PINTを置き換えるものではない。
JP PINTへ変換する前段,及びJP PINTから受信した後段で,既存業務システムが扱いやすい共通形式として機能する。
5.13. まとめ
請求書の構造化CSVは,正規化された複数CSVファイル群ではない。
また,単なる明細一覧CSVでもない。
請求書ヘッダー,売手,買手,税率別内訳,明細,支払,参照文書といった階層構造を,1枚のCSVに保持する形式である。
構造化CSV = 1枚のCSV * ディメンション列 * 連番による階層表現 * JSONメタデータ * XBRLタクソノミによる意味定義
この形式であれば,中小企業の業務システム,Excel,Pandas,販売管理,会計ソフト,ペポル Access Pointが,同じ請求書データを扱いやすくなる。
日本版コアインボイス(構造化CSV)は,JP PINT,中小企業共通EDI,流通BMS,業界EDI,Web-EDI,ERP,会計,販売管理をつなぐ同時通訳モデルとして有効である。
6. 構造化CSVと正規化CSVの違い
構造化CSVと従来の正規化CSVの違いは,次のように整理できる。
| 観点 | 正規化CSV | 構造化CSV |
|---|---|---|
|
基本単位 |
複数のテーブル |
1枚のCSV |
|
データ構造 |
ヘッダー,明細,税内訳,支払等を別表に分割 |
1枚のCSV内で階層を保持 |
|
関連付け |
請求書ID,明細ID等でJOIN |
ディメンション列又は連番で階層を表現 |
|
処理方法 |
SQL又はPandasのmerge処理が必要 |
filter,groupby,pivot等で処理可能 |
|
利用者負担 |
テーブル構造と結合条件の理解が必要 |
1枚のCSVを読み,行種別とディメンションで処理できる |
|
中小企業対応 |
やや重い |
Excel,Pandas,簡易ツールで扱いやすい |
|
意味定義 |
テーブル定義又はDBスキーマに依存 |
タクソノミ又はメタデータで列・概念・階層を定義 |
|
主な用途 |
RDBへの格納,業務DB設計 |
データ交換,変換,検証,監査,ペポル前後の連携 |
したがって,日本版コアインボイス(構造化CSV)は,RDBの外部出力形式ではない。
むしろ,JP PINT,中小企業共通EDI,流通BMS,業界EDI,Web-EDI,ERP,会計,販売管理の間で,意味を保持したままデータを受け渡すための標準形式である。
7. 日本版コアインボイスとsyntax binding
日本版コアインボイスでは,少なくとも次のbindingを定義する必要がある。
| Binding | 内容 |
|---|---|
|
JP PINT binding |
日本版コアインボイス(構造化CSV)からJP PINT UBL 2.1への対応。ペポルネットワーク送信用。 |
|
JP BIS Self Billing binding |
仕入明細書,買手作成請求書,検収起点の支払明細等への対応。 |
|
中小企業共通EDI binding |
中小企業共通EDIのXML又はAPIデータと,日本版コアインボイス(構造化CSV)との対応。 |
|
流通BMS binding |
受発注,納品,検収,返品,請求等の既存流通BMS項目と,日本版コアインボイス(構造化CSV)との対応。 |
|
業界EDI binding |
業界固有コード,取引先コード,商品コード,店舗コード等と,日本版コアインボイス(構造化CSV)との対応。 |
|
Web-EDI binding |
取引先ポータル,購買ポータル,マーケットプレイス等から出力されるCSV,Excel,APIデータとの対応。 |
|
ERP / 会計 / 販売管理 binding |
既存業務システムの取引先マスタ,商品マスタ,請求データ,入金消込データとの対応。 |
|
XBRL-CSV binding |
タクソノミに基づく意味定義,データ型,多重度,検証規則,階層構造の管理。 |
この構成では,JP PINTはペポル配送用の構文であり,日本版コアインボイス(構造化CSV)は国内業務システム間の共通論理モデルである。
重要なのは,日本版コアインボイス(構造化CSV)を複数の正規化CSVファイル群として定義しないことである。
構造化CSVは,1枚のCSVに階層構造を保持し,Pandas等で容易に読み書きできる標準交換形式である。
8. 日本版コアインボイスが国内EDI連携に有効な理由
日本版コアインボイス(構造化CSV)を導入すると,次の効果が期待できる。
| 効果 | 説明 |
|---|---|
|
個別変換の削減 |
JP PINT,流通BMS,中小企業共通EDI,業界EDIを相互に直接変換せず,日本版コアインボイスを介して変換できる。 |
|
JOIN操作の削減 |
請求書ヘッダー,明細,税内訳,支払情報,参照文書を別表に分割せず,1枚のCSV内で階層として保持できる。 |
|
Pandas等での処理容易性 |
1つのCSVを読み込み,record_typeやディメンション列で抽出,集計,変換できる。 |
|
中小企業対応 |
XMLを直接扱えない中小企業でも,CSV又は会計ソフト連携でペポルに参加しやすくなる。 |
|
セマンティック整合 |
Seller,Buyer,Payee,Tax Representative,EndpointID,登録番号等の意味を明確に管理できる。 |
|
税務要件対応 |
適格請求書,仕入明細書,区分記載請求書,免税事業者取引等を一貫したモデルで扱える。 |
|
既存EDI参照 |
注文番号,納品書番号,検収番号,支払通知番号等を同一CSV内の参照行として保持できる。 |
|
ZEDI連携 |
請求書番号,支払参照,消込キーを構造化CSVで保持し,支払・入金消込へ接続できる。 |
|
監査証跡 |
変換前後のデータ,送達記録,承認・差戻し・再送等を記録しやすくなる。 |
|
タクソノミ管理 |
列名,意味,データ型,コードリスト,検証規則をタクソノミとして管理できる。 |
特に重要なのは,構造化CSVが「ペポルの前後」を簡素化することである。
ペポルネットワーク上ではJP PINTを使う。しかし,企業内部,既存EDI,業務アプリケーション,CSV,Excel,会計ソフトとの接続では,日本版コアインボイス(構造化CSV)を使う。
これにより,ペポルと既存EDIの間に意味的な橋を架けることができる。
9. ペポルを国内既存EDI連携に利用する構成
ペポルを国内既存EDI連携の共通相互接続ネットワークとして使う場合,実装構成は次のようになる。
既存EDI利用者 | | 流通BMS / 中小企業共通EDI / 業界EDI / Web-EDI / ERP / 会計 v 既存EDIプロバイダー又は業務アプリケーション | | 日本版コアインボイス(構造化CSV) | 1枚のCSVとして階層構造を保持 | マッピング,変換,参加者ID対応 v ペポル Access Point 又は ペポル連携ゲートウェイ | | JP PINT | ペポル 4コーナーネットワーク v 相手側 ペポル Access Point | | 日本版コアインボイス(構造化CSV) | 1枚のCSVとして階層構造を保持 | 変換,取込,既存システム連携 v 相手側ERP / 会計 / 既存EDI / Web-EDI
この構成では,既存EDIを全面的に廃止する必要はない。
むしろ,既存EDIは業界固有の受発注,納品,検収,返品,月次締め等を引き続き処理し,ペポルはプロバイダー間の請求書・仕入明細書・支払参照・証跡連携の共通ネットワークとして利用する。
その前後で,日本版コアインボイス(構造化CSV)が,既存EDI,ERP,会計,販売管理とJP PINTとの間の同時通訳モデルとして機能する。
10. ID対応表と国内ディレクトリの必要性
ペポルを国内EDI連携の共通基盤にするうえで,最大の課題はID対応である。
既存EDIでは,次のようなIDが使われている。
-
法人番号
-
適格請求書発行事業者登録番号
-
ペポル Participant ID
-
GLN
-
業界EDI利用者ID
-
中小企業共通EDIユーザーID
-
流通BMS取引先コード
-
仕入先コード
-
得意先コード
-
店舗コード
-
事業所コード
-
出品者ID
-
加盟店ID
-
市場コード
-
生産者コード
-
農協・漁協等の組合員コード
-
会計システム内の取引先コード
これらを混同してはならない。
SBDH Sender/Receiver及びpayload Party/EndpointIDに記載できるのは,ペポル Participant IDとして表現できる識別子である。一方,既存EDI利用者IDや取引先コードは,通常,ペポル Participant IDではない。
したがって,必要なのは,次のようなID対応表である。
| ID種別 | 用途 | ペポル上の扱い |
|---|---|---|
|
ペポル Participant ID |
ペポルネットワーク上の配送・到達性 |
SBDH Sender/Receiver,EndpointIDに使用 |
|
法人番号 |
国内法人識別 |
ペポル IDスキームの候補又は補助識別子 |
|
適格請求書登録番号 |
税務上の適格請求書発行事業者識別 |
PartyTaxScheme等で表現。EndpointIDと同一とは限らない。 |
|
業界EDI利用者ID |
既存EDI内の利用者識別 |
ペポル IDとの対応表で管理。SBDHには直接使用しない。 |
|
取引先コード |
当事者間又は社内の取引先識別 |
PartyIdentification等の補助識別子,又は外部マスタで管理 |
|
出品者ID・加盟店ID |
マーケットプレイス内の売手識別 |
Sellerそのものを表す場合はペポル ID対応が必要。内部IDとしてはEndpointIDに使わない。 |
|
仕入先コード |
買手側システム内のSupplier識別 |
Self Billing Invoiceでは補助識別子として管理。Supplier EndpointIDの代替にしない。 |
|
市場コード・生産者コード |
市場取引・一次産業取引の識別 |
取引明細又は精算データで管理。ペポル Participant IDと同一視しない。 |
ペポルを国内EDI連携に利用するためには,ペポルのSMP/SMLだけでなく,国内の既存EDI識別子とペポル Participant IDを対応させるディレクトリ又はマスタ連携が不可欠である。
11. プロバイダーの役割:変換業者ではなく同時通訳を担うゲートウェイへ
国内既存EDIプロバイダーがペポルと連携する場合,単なるXML変換業者として考えるべきではない。
必要な役割は,少なくとも次のとおりである。
| 役割 | 内容 |
|---|---|
|
参加者登録支援 |
利用者をペポル Participantとして登録し,ペポル IDを管理する。 |
|
ID対応管理 |
既存EDI利用者ID,取引先コード,法人番号,登録番号,ペポル IDの対応表を管理する。 |
|
日本版コアインボイス変換 |
既存EDIメッセージ,CSV,API,ERPデータを日本版コアインボイス(構造化CSV)へ変換する。 |
|
JP PINT変換 |
日本版コアインボイス(構造化CSV)をJP PINT又はSelf Billing Invoiceへ変換する。 |
|
意味変換 |
単なる項目変換ではなく,Seller,Buyer,Supplier,Customer,Payee,Tax Representative等の意味を正しく対応させる。 |
|
配送 |
ペポル AP又はAP連携ゲートウェイとして相手先APへ送信する。 |
|
受信・取込 |
相手側から受信したペポル文書を日本版コアインボイス(構造化CSV)又は既存EDI形式へ変換する。 |
|
送達・証跡管理 |
送信,受信,承認,差戻し,再送,取消,応答を証跡として管理する。 |
|
責任分界管理 |
技術的送信者,文書作成者,請求書発行者,Seller,Buyer等の責任分界を明確にする。 |
このうち最も重要なのは,意味変換である。
既存EDIの「取引先コード」をペポルのEndpointIDへ単純にコピーすることはできない。また,EDIプロバイダー自身のペポル IDを,売手又は仕入先の代替として安易に使うこともできない。
11.1. 日本での段階的実装案
ペポルを国内既存EDI連携の共通相互接続ネットワークとして使う場合,いきなり全ての業務文書をペポル化するのは現実的ではない。
段階的には,次の順序が考えられる。
11.2. 第1段階:請求書・仕入明細書のペポル化
最初に取り組むべきは,請求書及び仕入明細書等である。
通常の売手発行請求書はJP PINT Invoiceとして扱う。買手作成の仕入明細書等については,通常のJP PINT Invoiceに無理に当てはめるのではなく,JP BIS Self Billing Invoiceの適用を検討する。
この段階では,既存EDIの受発注,出荷,検収,返品等はそのまま残してよい。
受発注・出荷・検収:
既存EDI
請求書:
JP PINT Invoice
仕入明細書等:
JP BIS Self Billing Invoice
C1-C2 / C3-C4:
日本版コアインボイス(構造化CSV)
支払・消込:
ZEDI又は会計システム連携
11.3. 第2段階:既存EDI文書への参照連携
次に,ペポル Invoice又はSelf Billing Invoiceから,既存EDI文書への参照を明確にする。
例えば,次の参照である。
| 参照対象 | 例 |
|---|---|
|
注文 |
注文番号,注文明細番号,発注者コード,受注者コード |
|
出荷・納品 |
納品書番号,出荷案内番号,納品明細番号 |
|
検収 |
検収番号,検収明細番号,検収日,検収差異 |
|
返品・値引 |
返品伝票番号,値引明細番号,調整理由 |
|
仕入明細 |
仕入明細書番号,支払通知番号,月次締め番号 |
|
決済・消込 |
支払通知番号,振込番号,ZEDIのEDI情報,入金消込キー |
この方式では,ペポル Invoiceに全ての業界EDI明細を詰め込むのではなく,ペポル文書を基準文書として,既存EDI文書又は構造化CSV等の補助データを参照する。
ペポル Invoice / Self Billing Invoice ├─ Order Reference ├─ Despatch / Delivery Reference ├─ Acceptance / Inspection Reference ├─ Statement / Monthly Closing Reference ├─ Payment Reference └─ Supporting Document Reference
11.4. 第3段階:国内ペポルプロファイルの拡張
請求書だけでなく,注文,注文応答,出荷案内,受領,検収,インボイス応答,支払通知等について,必要な国内プロファイルを整備する。
ペポルには,Billingだけでなく,Post Award領域の文書仕様が存在する。したがって,日本国内でも,将来的には次の文書を検討対象にできる。
| 文書 | 国内での候補 |
|---|---|
|
Order |
発注書,購買依頼,取引条件通知 |
|
Order Response |
受注確認,納期回答,欠品回答 |
|
Despatch Advice |
出荷案内,納品予定,納品書 |
|
Receipt Advice |
受領通知,入荷通知 |
|
Invoice Response |
請求書受領,承認,差戻し,異議通知 |
|
Statement |
月次請求明細,取引明細,精算書 |
|
Payment related data |
支払通知,消込情報,ZEDI連携 |
ただし,この段階では,単なるXML変換では不十分である。日本の商慣行,締め請求,返品,値引,リベート,検収差異,仕入明細,媒介者交付特例,卸売市場特例等を,ペポルのsemantic modelとどう対応させるかを検討する必要がある。
11.5. ViDA時代の国内コアインボイス
欧州ViDAでは,電子インボイスは単なる取引文書ではなく,デジタル報告要件,税務,監査証跡と結び付く基盤となる。
日本でも,将来的に電子インボイス,支払情報,消込情報,監査データ,税務報告が連携していく場合,個別XML仕様だけでは不十分である。
必要なのは,次の三層である。
セマンティック層:
日本版コアインボイス
構文層:
JP PINT, Self Billing, 流通BMS, 中小企業共通EDI, 構造化CSV, XBRL-CSV
配送層:
ペポル, 既存EDI, API, ファイル連携, ZEDI
この三層を分けることで,制度変更,税率変更,業界固有項目追加,ペポル仕様変更,CSV項目変更に柔軟に対応できる。
11.6. 検討すべき制度・仕様課題
ペポルを国内既存EDI連携基盤として利用するには,次の課題を整理する必要がある。
| 課題 | 検討内容 |
|---|---|
|
ペポル IDの国内方針 |
法人番号,登録番号,GLN等のどれをペポル Participant IDの中心にするか。 |
|
既存EDI IDとの対応 |
流通BMS,中小企業共通EDI,業界EDIの利用者IDとペポル IDをどう対応させるか。 |
|
代理登録・代理運用 |
小規模事業者のペポル Participant IDをプロバイダーが代理運用できるか。 |
|
日本版コアインボイス |
EN 16931を参考に,JP PINTと既存EDIをつなぐ国内共通論理モデルをどう定義するか。 |
|
構造化CSV |
ヘッダー,明細,税率別内訳,当事者,支払,参照文書等を,1枚のCSVで階層構造を保持したままどう表現するか。 |
|
SBDH/payload整合性 |
SBDH Sender/Receiverとpayload EndpointIDの一致をどこで検証するか。 |
|
Self Billing Invoice |
仕入明細書,支払通知,検収明細等をJP BIS Self Billing Invoiceで扱える範囲。 |
|
媒介者交付特例 |
媒介者が自己名義で交付する場合,payload Sellerを媒介者としてよいか。 |
|
卸売市場・農協等特例 |
市場又は農協等が作成する書類をJP PINT Invoice,Self Billing Invoice,又は別文書として扱うか。 |
|
既存EDI文書参照 |
注文,納品,検収,返品,値引,月次締め等の参照IDをどう保持するか。 |
|
応答・承認 |
Invoice Response,業界EDI応答,ポータル承認,無応答確認等をどう証跡化するか。 |
|
支払・消込 |
JP PINT請求書番号,支払通知番号,消込キーをどう対応させるか。 |
|
税務報告・DRR |
将来,ViDA型のデジタル報告又は国内税務データ連携へ拡張できるか。 |
12. 関係者へ確認すべき事項
この構想を進めるには,個別プロバイダーの実装判断ではなく,関係者による共通方針が必要である。
確認すべき事項は次のとおりである。
-
ペポル/JP PINTを,日本国内の既存EDIプロバイダー間相互接続基盤として位置付けることが可能か。
-
流通BMS,中小企業共通EDI,業界EDIプロバイダーがペポル AP又はAP連携ゲートウェイとして機能する場合の要件は何か。
-
既存EDI利用者ID,取引先コード,仕入先コード,出品者ID等をペポル Participant IDと対応させる国内ディレクトリ又はマスタ連携の方針はあるか。
-
SBDH Sender/Receiverとpayload Party/EndpointIDの一致を,JP PINT検証でどのように扱うか。
-
既存EDIプロバイダーが技術的送信者である場合,SBDH Senderをプロバイダー自身としてよい場面はあるか。
-
中小企業又は小規模事業者のペポル IDを,EDIプロバイダー又は業務アプリケーション事業者が代理登録・代理運用する場合のルールは何か。
-
仕入明細書,支払通知,検収明細,月次締め請求等をペポル文書で扱う方針はあるか。
-
ViDA型のeInvoicing/DRRを参考に,日本でも将来,ペポルを税務報告又は監査データ連携へ拡張する可能性をどう考えるか。
13. おわりに
ペポルを国内既存EDI連携の共通相互接続ネットワークとして使う可能性は十分にある。
ただし,それは,既存EDIを一挙に廃止して全てをペポルに置き換えるという意味ではない。むしろ,流通BMS,中小企業共通EDI,業界EDI,Web-EDI,ERP,会計システムを残しつつ,それらの間に共通の相互接続層と同時通訳モデルを設けるという考え方である。
欧州ViDAの動きから学ぶべき点は,電子インボイス標準だけではない。重要なのは,既存制度,各国プラットフォーム,サービスプロバイダー,企業システムをつなぐ相互運用基盤としてペポルを活用しようとしている点である。
日本でも,JP PINTをペポルネットワーク上の請求書配送仕様とし,その前後の国内業務システム連携には日本版コアインボイス(構造化CSV)を用いれば,既存EDIごとの個別接続問題を緩和できる。
そのためには,単なるフォーマット変換では不十分である。
必要なのは,次の五点である。
-
日本版コアインボイスという共通セマンティックモデル
-
その標準実装形式としての構造化CSV
-
ペポル IDと既存EDI IDの対応表
-
SBDH Sender/Receiverとpayload Party/EndpointIDの厳格な整合
-
プロバイダー間の配送・変換・責任分界・証跡管理
ここでいう構造化CSVは,正規化された複数テーブルをJOINして請求書を復元する方式ではない。1枚のCSVに請求書の階層構造と意味を保持し,Pandas等の一般的なライブラリで容易に抽出,集計,変換,検証できる形式である。
ペポルを「請求書XMLを送る仕組み」としてだけ捉えると,日本国内の既存EDI問題は解決しない。
必要なのは,ペポルを相互接続ネットワークとして利用し,その前後で日本版コアインボイス(構造化CSV)を同時通訳モデルとして機能させることである。
日本版コアインボイス(構造化CSV)は,JP PINT,中小企業共通EDI,流通BMS,業界EDI,Web-EDI,ERP,会計,販売管理の間で,意味,構文,コード,ID,業務文脈を通訳する国内共通モデルである。
参考文献
-
[1] OpenPeppol, Peppol Business Message Envelope (SBDH) v2.0.1, 2023-08-17
https://docs.Peppol.eu/edelivery/envelope/Peppol-EDN-Business-Message-Envelope-2.0.1-2023-08-17.pdf -
[2] OpenPeppol, Peppol BIS Billing 3.0, Compliance to BIS, Enveloping compliance
https://docs.Peppol.eu/poacc/billing/3.0/compliance/ -
[3] OpenPeppol, JP PINT compliance, Enveloping compliance
https://docs.Peppol.eu/poac/jp/pint-jp/compliance/ -
[4] OpenPeppol, JP BIS Self Billing Invoice
https://docs.Peppol.eu/poac/jp/pint-jp-sb/bis/ -
[5] Digital Agency, JP PINT
https://www.digital.go.jp/policies/electronic_invoice -
[6] OpenPeppol, Peppol ViDA Pilot
https://Peppol.org/Peppol-vida-pilot/ -
[7] European Commission, Adoption of the VAT in the Digital Age package, 2025-03-11
https://taxation-customs.ec.europa.eu/news/adoption-vat-digital-age-package-2025-03-11_en -
[8] European Commission, VAT in the Digital Age (ViDA)
https://taxation-customs.ec.europa.eu/taxation/vat/vat-digital-age-vida_en -
[9] European Commission, Navigating the eInvoicing standard documentation
https://ec.europa.eu/digital-building-blocks/sites/spaces/DIGITAL/pages/467108931/Navigating%2Bthe%2BeInvoicing%2Bstandard%2Bdocumentation -
[10] OpenPeppol, Peppol BIS Billing 3.0
https://docs.Peppol.eu/poacc/billing/3.0/bis/ -
[11] GS1 Japan, 流通BMS標準仕様 通信基盤関連の標準
https://www.gs1jp.org/ryutsu-bms/standard/standard04.html -
[12] GS1 Japan, 流通BMS導入の手引き
https://www.gs1jp.org/ryutsu-bms/info/pdf/tebiki.pdf -
[13] ITコーディネータ協会, 中小企業共通EDI実装ガイドライン
https://www.itc.or.jp/datarenkei/dlfiles/edi/3itca_edi_deployguideline_ver2_20190619.pdf -
[14] つなぐITコンソーシアム, 中小企業共通EDIとは
https://tsunagu-cons.jp/about-edi/ -
[15] 全国銀行協会, ZEDI(全銀EDIシステム)
https://www.zenginkyo.or.jp/abstract/efforts/smooth/xml/ -
[16] 三分一信之, 日本版コアインボイス変換サービス
https://www.sambuichi.jp/core-japan/ -
[17] 三分一信之, 会計のデジタル化は日本版コアインボイスから
https://www.sambuichi.jp/?p=8933 -
[18] 三分一信之, Ledger Explorer demo: Structured CSV / hierarchical tidy data for xBRL GL 2.0
https://www.sambuichi.jp/ledger/about_en.html -
[19] 三分一信之, Ledger Explorer Structured CSV demo
https://www.sambuichi.jp/ledger/?view=tidy&month=2021-04&lang=ja&mode=server

コメントを残す