
Views: 14
日本版コアインボイス ゲートウェイ
- はじめに
- コンテナの積み替え作業に例えれば
- 1. 適格請求書の記載事項とセマンティックモデル
- 1.1 デジタルインボイスのセマンティックモデル
- 1.2 デジタルインボイスの要素
- 2. XML構文とXPath
- [解説] XML構文とXPathの基本
- XMLの基本
- XPathの基本
- XML構文とXPathの使い方
- 3. 構文バインディングについて
- 4. 欧州規格における異なる構文間のバインディング
- 5. 日本版コアインボイスゲートウェイ
- 6. セマンティックモデルとXBRL
- 7. デジタルインボイスを契機とする会計のデジタル化
- 8. 中小企業にとって、コアインボイスゲートウェイと構文バインディングとは
- 9. 会計情報の共通化とCSVインタフェースの標準化
- 参考: 先行事例 北欧スマート政府&ビジネス
『日本版コアインボイス変換サービス試験公開』
はじめに
東京税理士会「情報通8月号」に「コアインボイスによる中小企業のデジタル化」 (外部リンク) を掲載しています
内閣官房IT総合戦略室が2020年に発表した「電子インボイスに係る取組状況について」では、日本における電子インボイスの仕様標準化がOpen Peppolを基礎として推進されることが発表されました。これにより、JP PINTがEIPAの取り組みの中から生まれ、Peppol Authorityが仕様及びその運用を監督する仕組みが整備されています。
しかし、業界EDIも対象とする請求データをやりとりするための共通基盤ネットワークを実現するには、「日本版コアインボイスモデル」と業界EDIの構文を対象とした「構文バインディング」による「コアインボイスゲートウェイ」が必要です。これにより、業界EDIとデジタルインボイスを接続し、異なる構文間の接続を実現することができます。
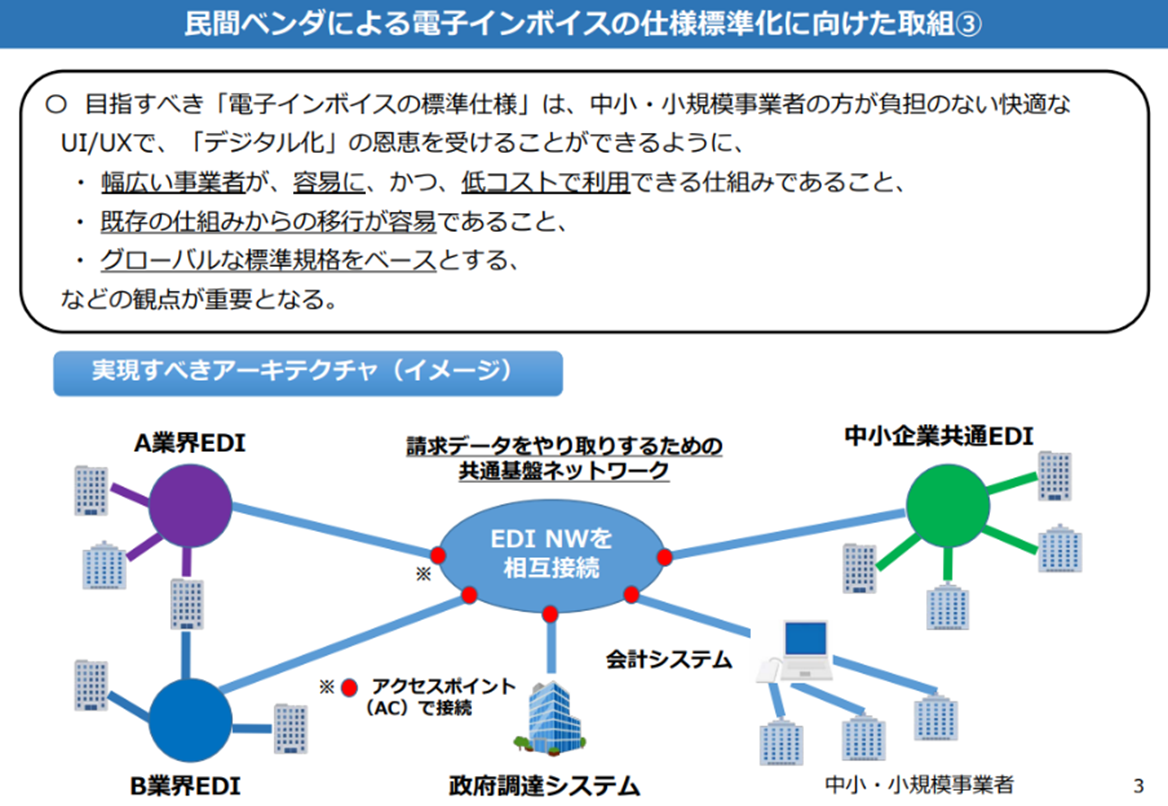
オープンペポル(JP PINT)のアクセスポイントのサービスプロバイダは、オープンペポルのデジタルインボイスしか受け付けていないため、対象範囲が限定されています。そこで、欧州のコアインボイスを中核とする構文バインディングが、EDIとデジタルインボイスを接続するための重要な手段となります。
構文バインディングは、異なるXML構文やセマンティックモデルを統合するための技術で、コアインボイスゲートウェイに適用することで、EDIとデジタルインボイスを相互運用することができます。これにより、取引先間でのデータのやり取りが効率化され、ビジネス関係の改善につながります。
さらに、企業の会計データを標準化し、共通のCSVインタフェースで参照可能にすることで、税理士や企業がより効率的な会計処理や税務申告を行うことができます。これにより、時間やコストの削減が期待できます。
オープンペポルは、OASISが制定したUBLを採用しており、中小企業共通EDIはUN/CEFACTが制定したCIIを採用しています。これらは独立して開発されましたが、データモデルの定義手法としてどちらもCCTSに準拠しており、UBLとCIIは共通のXML Schemaを使用しています。CCTSに基づいて定義された再利用可能なデータ型として知られているUniversal Business Language(UBL)Common Libraryと、UN/CEFACTのXML標準であるCross-Industry Invoice(CII)XML Schemaで使用されるQuality Declaration Type(qdt)とUnit of Measure Type(udt)のXML Schemaです。前世紀末にXMLが誕生したころ1999年にUN/CEFACTとOASISによって共同開発されたebXMLでもこのCCTSに基づいてebXMLのモデル定義を行い、ISO 15000-5:2014 Electronic Business Extensible Markup Language (ebXML) — Part 5: Core Components Specification (CCS)が制定されています。
このような共通の基盤により、構文バインディング技術を利用してEDIとデジタルインボイス間の相互運用性を向上させることができます。これによって、取引先との間で異なる構文を使用しても円滑なデータ交換が可能になり、ビジネスプロセスの効率化が実現できます。
今後、日本では業界EDIとデジタルインボイスの標準化が進むことが期待されており、オープンペポルやその他の標準化技術の普及が広がることで、より多くの企業が効率的なビジネスプロセスを実現することができるでしょう。これにより、企業間のデータ交換の効率化や取引先とのビジネス関係の改善が期待されます。
また、デジタルインボイスの普及により、会計データの標準化や経営に役立つ情報の共有が促進されることが考えられます。これにより、税理士や企業は効率的な会計処理や税務申告を行うことができ、経営の効率化やコスト削減が実現できるでしょう。
コンテナの積み替え作業に例えれば
貨物船の輸送におけるコンテナの積み替え作業を例えに取りながら、コアインボイスというシステムについて説明します。
コアインボイスは、中小企業共通EDIやJP PINTなどの異なるデータ形式で表現された請求書を、一つの共通の形式で統一的に扱うためのシステムです。港でコンテナを積み替える際に、ピッキングリストに従って請求金額、商品名、数量、金額、税率などを取り出し、指定された船倉に異なったまとめ方で格納します。
この作業は、自動運転されるクレーンによって行われ、コアインボイスの論理モデルの定義表やピッキングシート、格納指示リストなどに基づいて指示されます。これらの指示は、XBRLタクソノミで定義された辞書によって表現されます。
このように、コアインボイスは異なるデータ形式を統一的に扱い、効率的な請求書の処理を可能にするシステムです。日本版コアインボイス ゲートウェイは、このシステムを実現するための機能を提供するものです。
あなたが異なる形式の手紙をたくさん受け取った場合、それぞれの手紙の内容を把握するためには、それぞれの手紙の形式や書き方に合わせて読み解く必要があります。しかし、それぞれの手紙の内容を統一的なフォーマットに変換することで、一つのルールで手紙の内容を理解することができるようになります。
同じように、企業間の取引においては、異なる形式の請求書を受け取ることがあります。しかし、コアインボイスというシステムを使うことで、異なる請求書の内容を一つの共通の形式で統一的に扱うことができます。これによって、請求書の処理が効率化され、取引のスムーズな進行が可能になります。
例えば、ある企業が別の企業から商品を購入した場合を考えてみましょう。この場合、請求書を受け取り、支払いを行う必要があります。しかし、購入した商品によっては、請求書の書き方やフォーマットが異なる場合があります。
例えば、A社からの請求書はExcel形式で送られてきて、商品名が「商品A」と表記され、税率が10%と表記されているとします。一方、B社からの請求書はPDF形式で送られてきて、商品名が「製品B」と表記され、税率が8%と表記されているとします。
こういった場合、異なる請求書の書き方に対応するためには、それぞれの請求書を個別に処理する必要があります。しかし、コアインボイスを使うことで、A社とB社の請求書を共通のフォーマットで統一的に扱うことができます。
つまり、A社とB社から送られてきた請求書をコアインボイスの形式に変換することで、商品名や税率の表記方法にかかわらず、同じように処理することができます。このように、請求書の処理を共通のフォーマットで行うことで、取引のスムーズな進行が可能になります。
1. 適格請求書の記載事項とセマンティックモデル
閑話休題
1.1 デジタルインボイスのセマンティックモデル
デジタルインボイスのセマンティックモデルは、インボイス情報を構造化し、標準化されたフォーマットで表現する方法です。これにより、情報の取得や効率的な処理が可能になります。データ構造化では、事業者、住所、期間、取引明細、品目情報、価格、税情報など共通のデータ構造を持つグループを定義し、階層構造で表現します。
1.2 デジタルインボイスの要素
請求書番号
請求書日付
発行企業情報
企業名
住所
電話番号
メールアドレス
受領企業情報
企業名
住所
電話番号
メールアドレス
商品・サービス情報
内容
数量
単位価格
金額
消費税額
税込み金額
支払情報
支払期日
支払方法
このような階層構造によって、デジタルインボイスの情報が標準化され、効率的に処理されることができます。また、各項目は業界標準に準拠したデータ型やコードリストを使用して定義されることで、異なるシステムや企業間でも容易にデータ交換が可能になります。デジタルインボイスの普及に伴い、企業は効率的な会計処理や税務申告を行い、経営の効率化やコスト削減が実現できるでしょう。
適格請求書では、次の項目を記載することが要請されています。
1 適格請求書発行事業者の氏名又は名称及び登録番号
2 課税資産の譲渡等を行った年月日
3 課税資産の譲渡等に係る資産又は役務の内容(課税資産の譲渡等が軽減対象資産の譲渡等である場合には、資産の内容及び軽減対象資産の譲渡等である旨)
4 課税資産の譲渡等の税抜価額又は税込価額を税率ごとに区分して合計した金額及び適用税率
5 税率ごとに区分した消費税額等
6 書類の交付を受ける事業者の氏名又は名称
これらの項目を含んだデジタルインボイスのセマンティックモデルは、次のような階層構成で定義されます。
請求書
請求書の番号
請求書の日付
売り手
氏名又は名称(1)
登録番号(1)
買い手
氏名又は名称(6)
税率ごとに区分した適用税情報 -複数回繰り返し-
合計した金額(4)
適用税率(4)
消費税額(5)
明細行 -複数回繰り返し-
課税資産の譲渡等を行った年月日(2)
商品やサービスの品目情報(3)
商品やサービスの課税区分および税率(3)
商品やサービスの数量、単位価格、金額
この論理的な階層定義情報がセマンティックモデルです。
ここで、国税庁Q&Aの問45 適格請求書の記載例をセマンティックモデルで表現してみましょう。
注:合計金額や税額合計は、Q&Aに記載された明細行に基づいて3件を合計した値に訂正しています。
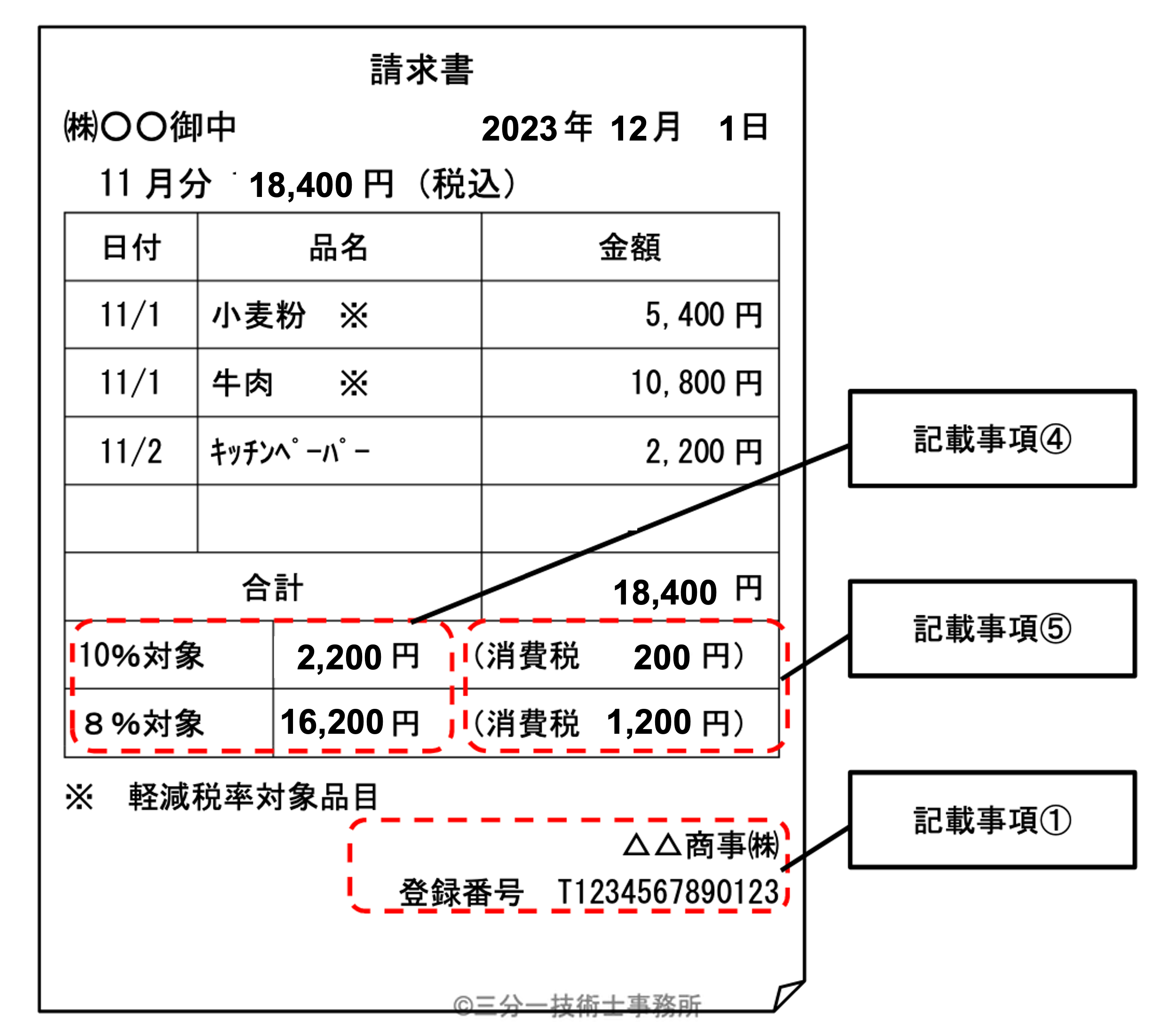
出典: 適格請求書に記載が必要な事項
このデータをセマンティックモデルの階層構造に当てはめた表を次に示します。
| 項目名 | C1 | C2 | C3 | C4 | C5 | C6 |
|---|---|---|---|---|---|---|
|
請求書番号 |
156 |
|||||
|
請求書発行日 |
2023-12-01 |
|||||
|
請求期間開始日 |
2023-11-01 |
|||||
|
請求期間終了日 |
2023-11-30 |
|||||
|
売り手登録番号(1) |
T1234567890123 |
|||||
|
売り手名称(1) |
株式会社 △△商事 |
|||||
|
買い手名称(6) |
株式会社 〇〇 |
|||||
|
請求書明細行金額の合計 |
17000 |
|||||
|
請求書合計金額(税抜き) |
17000 |
|||||
|
請求書消費税合計金額 |
1400 |
|||||
|
請求書合計金額(税込み) |
18400 |
|||||
|
差引請求金額 |
18400 |
|||||
|
税内訳情報(1..n) |
1 |
2 |
||||
|
* 課税分類毎の課税基準額(4) |
15000 |
2000 |
||||
|
* 課税分類毎の消費税額(5) |
1200 |
200 |
||||
|
* 課税分類コード(4) |
AA |
S |
||||
|
* 課税分類毎の税率(4) |
8 |
10 |
||||
|
請求書明細行(1..n) |
1 |
2 |
3 |
|||
|
* 請求書明細行ID |
1 |
2 |
3 |
|||
|
* 請求する数量 |
1 |
1 |
1 |
|||
|
* 請求書明細行金額(税抜き) |
5000 |
10000 |
2000 |
|||
|
* 請求書明細行の期間開始日(2) |
2023-11-01 |
2023-11-01 |
2023-11-02 |
|||
|
* 請求書明細行の期間終了日(2) |
2023-11-01 |
2023-11-01 |
2023-11-02 |
|||
|
* 品名(3) |
小麦粉 |
牛肉 |
キッチンペーパー |
|||
|
* 品目の課税分類(3) |
AA |
AA |
S |
|||
|
* 品目の税率(3) |
8 |
8 |
10 |
|||
|
* 品目単価(税抜き) |
5000 |
10000 |
2000 |
この表の縦と横を転置して階層軸を左に寄せたた形式が、XBRL-CSVが提供する階層定義がある整然データ(Tidy data)です。
整然データは、ここで示す表の縦と横を転置した形で、各行が一意の観測値を持ち、各列が一意の変数を持つような形式のデータです。この形式は、データを処理する上で非常に便利であり、データの分析や可視化、統合などが容易になります。
| 請求書番号 | 税内訳情報(1..n) | 請求書明細行(1..n) | 請求書発行日 | 請求期間開始日 | 請求期間終了日 | 売り手登録番号(1) | 売り手名称(1) | 買い手名称(6) | 請求書明細行金額の合計 | 請求書合計金額(税抜き) | 請求書消費税合計金額 | 請求書合計金額(税込み) | 差引請求金額 | 課税分類毎の課税基準額(4) | 課税分類毎の消費税額(5) | 課税分類コード(4) | 課税分類毎の税率(4) | 請求書明細行ID | 請求する数量 | 請求書明細行金額(税抜き) | 請求書明細行の期間開始日(2) | 請求書明細行の期間終了日(2) | 品名(3) | 品目の課税分類(3) | 品目の税率(3) | 品目単価(税抜き) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
156 |
2023-12-01 |
2023-11-01 |
2023-11-30 |
T1234567890123 |
株式会社 △△商事 |
株式会社 〇〇 |
17000 |
17000 |
1400 |
18400 |
18400 |
|||||||||||||||
|
1 |
15000 |
1200 |
AA |
8 |
||||||||||||||||||||||
|
2 |
2000 |
200 |
S |
10 |
||||||||||||||||||||||
|
1 |
1 |
1 |
5000 |
2023-11-01 |
2023-11-01 |
小麦粉 |
AA |
8 |
5000 |
|||||||||||||||||
|
2 |
2 |
1 |
10000 |
2023-11-01 |
2023-11-01 |
牛肉 |
AA |
8 |
10000 |
|||||||||||||||||
|
3 |
3 |
1 |
2000 |
2023-11-02 |
2023-11-02 |
キッチンペーパー |
S |
10 |
2000 |
この表は、Tidy data(整然データ)と呼ばれる形式で記述されています。Tidy dataは、文書単位のデータと明細行で繰り返されるデータを一つの表で記載する方法で、以下のような特徴があります。
各行が一つの観測値を表し、各列が一つの変数を表します。
各表が一つの観測単位に対応し、データを分割せずに一つの表に記録します。
各明細行のデータは、文書単位のデータと同じ変数名で表現され、各明細行の数だけ新しい行が追加されます。
例えば、この表の場合、請求書番号や請求期間など、文書単位のデータは一つの行で表現され、課税分類毎の課税基準額や消費税額など、明細行で繰り返されるデータは複数の行で表現されています。
Tidy dataを使用すると、データの加工や集計が容易になり、データの可視化や機械学習などの応用もしやすくなります。例えば、この表の場合、請求書番号が同じ明細行の課税分類毎の課税基準額や消費税額を一つの表にまとめて集計したり、特定の買い手名称に対する売り手名称の売り上げをグラフ化することができます。
このように、Tidy dataはデータの扱いを統一的にすることでデータの管理や分析を容易にし、ビジネス上の意思決定に役立ちます。
また、XBRL-CSVが提供する階層定義に従うことで、データの相互運用性が高くなります。階層定義は、データを分類し、規定されたタグを用いて情報を構造化することで、データの解釈や比較が容易になります。さらに、XBRL-CSVは、このような整然データの形式を規定しているため、データの相互運用性が高く、データの共有や解析が容易になります。
例えば、企業の財務データを分析する場合、データの整形や加工を行う必要があります。しかし、Tidy data形式のデータは、処理のしやすい形式であるため、データ分析のプロセスを効率化することができます。また、XBRL-CSVのような標準規格を採用することで、複数の企業間でのデータ共有が容易になります。これにより、業界全体でのデータの可視化や分析が可能になり、より深い洞察やビジネスチャンスを発見することができます。
さらに、XBRL-CSVは、財務情報の報告に関する規制に準拠する必要がある場合にも有用です。例えば、会計監査においては、財務諸表のデータを検証する必要があります。この際、XBRL-CSV形式でデータが提供されている場合、データの正確性や信頼性を高めることができます。
以上のように、Tidy data形式のデータやXBRL-CSVは、データの処理や共有において非常に重要であり、データの有効活用を促進するためには、このような標準規格の採用が必要不可欠です。
『Tidy dataとXBRL-CSVの折鶴モデル』で紹介していますので、そちらも併せてお読みください。
デジタルインボイスはXML文書データです。セマンティックモデルをXML構文に適用し、該当するXML要素の値として登録したXMLファイルを対応付けることを「構文バインディング」と呼びます。構文バインディングでは、セマンティックモデルで定義された項目とXML要素を対応付けるために、XML文書中のデータがどの位置に定義されているかを指定する必要があります。XML文書中のXML要素の位置を指定するのがXPathです。
次に、XPathについて簡単に紹介します。
2. XML構文とXPath
以下にXML構文のComplexType定義の架空の例を示します。例として、複数の商品やサービスを含むインボイスの場合を考えます。定義する文書のセマンティックモデルは以下のようなものです。
Invoice 請求書
* InvoiceHeader 請求書ヘッダ
** InvoiceNumber 請求書番号
** InvoiceDate 請求書日付
...
* InvoiceLine 請求書明細行(複数回繰返し)
** ItemNameme 品名
** Quantity 数量
** Price 価格
...このセマンティックモデルの階層定義に基づいて定義したXML構文(XML Schema)のComplexType定義(xs:complexType定義)を次に示します。
<xs:complexType name="InvoiceType">
<xs:sequence>
<xs:element name="InvoiceHeader" type="InvoiceHeaderType"/>
<xs:element name="InvoiceLine" type="InvoiceLineType" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="InvoiceHeaderType">
<xs:sequence>
<xs:element name="InvoiceNumber" type="xs:string"/>
<xs:element name="InvoiceDate" type="xs:date"/>
<xs:element name="..." type="..."/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="InvoiceLineType">
<xs:sequence>
<xs:element name="LineNumber" type="xs:string"/>
<xs:element name="ItemName" type="xs:string"/>
<xs:element name="Quantity" type="xs:decimal"/>
<xs:element name="Price" type="xs:decimal"/>
<xs:element name="..." type="..."/>
</xs:sequence>
</xs:complexType>上記の例では、InvoiceTypeがトップレベルの要素となり、その中にInvoiceHeaderTypeとInvoiceLineTypeが含まれています。InvoiceLineTypeは、maxOccurs属性にunboundedを指定しているため、複数のInvoiceLine要素を含むことができます。また、InvoiceHeaderTypeとInvoiceLineTypeはそれぞれ、ItemName、Quantity、Priceなどの要素を含むことができます。
次は、このXML Schema定義に基づいて作成したデジタルインボイスのXML文書です。
<Invoice>
<InvoiceHeader>
<InvoiceNumber>abc-123</InvoiceNumber>
<InvoiceDate>2023-12-011</InvoiceDate>
</InvoiceHeader>
<InvoiceLine>
<LineNumber>1</LineNumber>
<ItemName>小麦粉</ItemName>
<Quantity>1</Quantity>
<Price>5000</Price>
</InvoiceLine>
<InvoiceLine>
<LineNumber>2</LineNumber>
<ItemName>牛肉</ItemName>
<Quantity>1</Quantity>
<Price>10000</Price>
</InvoiceLine>
</Invoice>このXML文書で定義された2件目の明細に何が記載されているか取り出したいとします。ここで使用するのがXPathです。XPathでは、どの要素のどの子孫要素かを /親要素/子要素/孫要素 といった形で指定します。上記のXML文書に対して、明細行を指定するには、 /Invoice/InvoiceLine と記述します。この指定条件では、2件の明細行が指定されます。それでは、次のXPathはどの要素を指しているのでしょう。
/Invoice/InvoiceLine[LineNumber=2]
このXPathは、/Invoice/InvoiceLine と指定することで、2件の明細行を指定していますが、それだけでなく[ ]の中に記述した条件文を用いることでどのような条件を満たす明細行か指定しています。ここでは、いくつかあるInvoiceLine要素の中でも、その子要素であるLineNumberの値が 2 の明細行を指定しています。
このように、XPathを使用すれば、XML文書中の特定の要素を明確に指定することができます。会計ソフトや業務ソフトから取り出したセマンティックモデルで定義されているデータをXML文書のどこに設定するかを指定するときや、XML文書からセマンティックモデルで定義されている必要なデータを取り出すときに使用するのがXPathです。
他の例を紹介します。AllowanceChargeという要素には、ChargeIndicatorという子要素があります。ChargeIndicatorが「false」に設定されている場合、この要素は「返金」として扱われます。一方、ChargeIndicatorが「true」に設定されている場合、この要素は「追加請求」として扱われます。XPathでは、AllowanceCharge[ChargeIndicator=false()]と書くことで、ChargeIndicatorが「false」に設定されているAllowanceCharge要素(返金)を選択できます。また、AllowanceCharge[ChargeIndicator=true()]と書くことで、ChargeIndicatorが「true」に設定されているAllowanceCharge要素(追加請求)を選択できます。このように、XPathを使って条件を指定することで、異なるXML構文の間の対応関係を定義することができます。
蛇足:
JP PINT 1.0において、Syntax bindingでの選択条件の記載は、Syntax Elementの要素名の下に[条件]として示されています。しかしながら、cac:PartyTaxSchemeに対して[cac:TaxScheme = “VAT”]といった記述があり、XMLの正確な理解が疑われる部分が存在します。
次のリンクでは、JP PINT V1.0に関する問題点を詳しく説明しています。確認してください: 『JP PINT V1.0間違い探し』
また、Syntax bindingの定義は、以下の当事務所の検証用サイトからも確認いただけます: https://www.wuwei.space/jp_pint/billing-japan/syntax2/ubl-invoice/tree/en/
XPathを使用することで、XML文書中の特定の要素を明確に指定できます。会計ソフトや業務ソフトから取り出したセマンティックモデルで定義されているデータをXML文書のどこに設定するかを指定する際や、XML文書からセマンティックモデルで定義されている必要なデータを取り出す際に役立ちます。
このような問題点を踏まえ、JP PINTの改善が求められています。今後のバージョンでは、XMLの理解に基づいた適切な条件指定が行われることが期待されます。XPathを活用して、適切な条件を指定し、異なるXML構文間の対応関係を定義することで、JP PINTの改善が図られるでしょう。
[解説] XML構文とXPathの基本
XMLとは、データを構造化して記述するための言語で、インターネット上で情報をやり取りする際に広く利用されています。XPathは、XML文書内の特定の要素や属性にアクセスするための言語です。このドキュメントでは、XML構文とXPathの基本について初心者にもわかりやすく説明します。
XMLの基本
XMLでは、データを要素と呼ばれるタグで囲むことで構造化します。以下は、簡単なXML文書の例です。
<book>
<title>XML入門</title>
<author>山田 太郎</author>
<price>1500</price>
</book>この例では、<book>`要素の中に<title>`、<author>、`<price>`という子要素が含まれています。
XPathの基本
XPathを使って、XML文書内の特定の要素や属性にアクセスすることができます。以下は、先ほどのXML文書から`<author>`要素を選択するためのXPathの例です。
/book/authorこのXPathは、<book>`要素の子要素である<author>`要素を指定しています。
XML構文とXPathの使い方
XML構文とXPathを使って、データの追加や変更、検索が容易になります。例えば、以下のようなXML文書があるとします。
<books>
<book id="1">
<title>XML入門</title>
<author>山田 太郎</author>
<price>1500</price>
</book>
<book id="2">
<title>HTML入門</title>
<author>佐藤 次郎</author>
<price>1800</price>
</book>
</books>このXML文書に対して、次のようなXPathを使ってデータを検索できます。
- すべての`<book>`要素を選択:
/books/book - id属性が1の`<book>`要素を選択:
/books/book[@id='1'] - すべての`<book>`要素の`<title>`要素を選択:
/books/book/title
このように、XML構文とXPathを使ってデータを簡単に検索、整理できます。初心者でもわかりやすい形でデータの構造化と操作が可能となります。
3. 構文バインディングについて
JP PINTやUN/CEFACT CIIは、デジタルインボイスを表現するXML構文です。UBLとCIIは、インボイスのXML構文として広く使われています。両者は、商品やサービスの明細行が繰り返される階層構造を持ち、それに基づいて定義されています。しかし、コンポーネントとその構成方法が異なるため、デジタルインボイスの形が大きく異なります。
UBLでは、Invoiceがトップ要素で、その中に複数のInvoiceLineが含まれます。InvoiceLineは、商品やサービスの明細行を表し、詳細情報が含まれます。これにより、複数の商品やサービスを1つのインボイスで定義できます。
CIIのXMLでは、Invoiceがトップ要素で、その中にTradeTransactionが含まれます。TradeTransactionには、商品やサービスの情報を含むLineTradeItemが複数含まれ、詳細情報が含まれます。こちらも、複数の商品やサービスを1つのインボイスで定義できます。
これらのXML構文は、階層構造に基づいて設計されています。構文バインディングにより、デジタルインボイスの情報を容易に取得/設定できるようになります。使用しているコンポーネントや構成の違いから、それぞれで異なったXML構文バインディングが必要となります。
4. 欧州規格における異なる構文間のバインディング
欧州では、欧州議会および理事会の「指令 2014/55/EU」に基づいて、欧州規格EN 16931シリーズが規定され、デジタルインボイスの推進が進められています。2014年当時は各加盟国それぞれでeInvoiceやeProcurementを政府調達を中心として進めていましたが、国ごとに異なる標準を採用していたため国境を越えた商取引が阻害されていました。欧州議会は、電子請求書の最低限の共通構成要素を「電子請求書のコア要素」(コアインボイス)として規定し、各国で採用されているXML構文のなかから普及しているものを選択し、「構文バインディング」を規定することとしました。
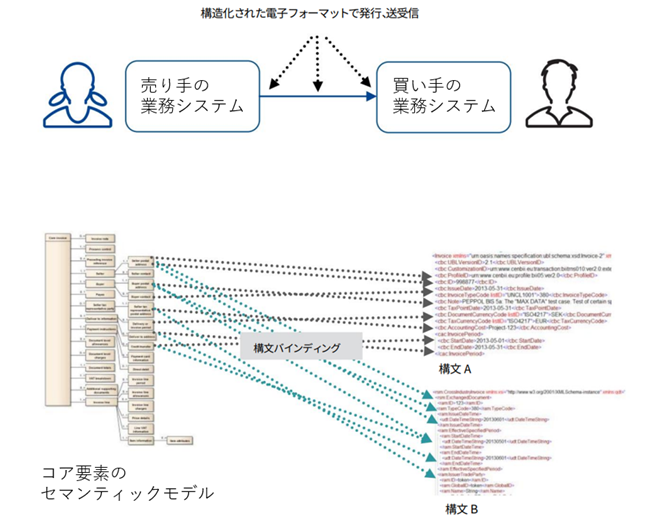
eInvoicing from a user’s perspective
欧州では、指令 2014/55/EUに基づき、EN 16931シリーズが規定され、デジタルインボイスが推進されています。各国では、異なる標準を採用していたため、国境を越えた商取引が阻害されていました。欧州議会は、「コアインボイス」として、構文バインディングを規定しました。
JP PINTは、UBLを採用し、中小企業共通EDIは、UN/CEFACT CIIを採用しています。それぞれの構文バインディングでは、共通の要素があるものの、UBLとCIIの要素名や構造が異なるため、対応付けが必要です。欧州規格では、EN 16931-1でセマンティックモデルを定義し、CEN/TS 16931-3-2でUBLとの、16931-3-3でUN/CEFACT CIIとの構文バインディングを定義しています。
例えば、請求書の発行者に相当する要素が、UBLではcac:AccountingSupplierPartyに、CIIではram:SellerCITradePartyにあたり、これらを対応付けるために、コアインボイスゲートウェイでは、セマンティックモデルで「売り手」を定義し、その項目とUBLおよびCIIへの構文バインディング定義しています。セマンティックモデルで定義された「支払条件」と、それぞれの要素が示す意味を正確に把握する必要があります。
CEN/TS 16393-3-1では、XML構文間のクロスマッピングについて説明されています。マッピングに問題がある場合は情報の損失が発生することがあります。マッピングの問題は、セマンティックレベル、構造レベル、繰返し回数の相違レベル、またはデータ型レベルで発生する可能性があります。マッピングは、異なる構文間のバインディングを可能にするための重要な手段です。正確なマッピングは情報の損失を最小限に抑えることができます。
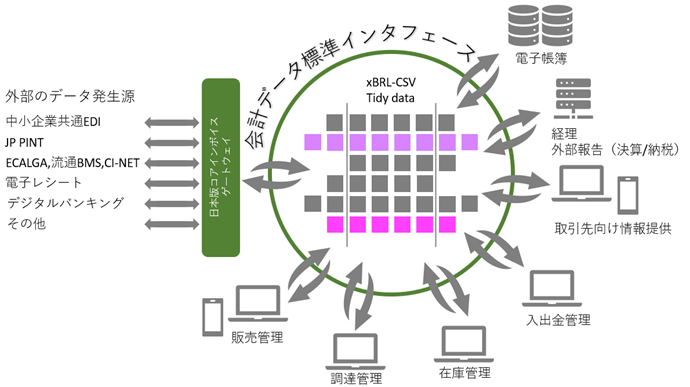
5. 日本版コアインボイスゲートウェイ
Open Peppolのサービスプロバイダーやデジタルインボイスサービス事業者同士がつながる方法は、C1-C2やC3-C4間でメッセージをやり取りすることです。このやり取りは、Open Peppolの管理範囲外で行われます。
デジタルインボイスサービスを利用する人は、Open PeppolのユーザーIDを取得することで、従来のデジタルインボイスの交換をOpen Peppolを通じて行うことができます。
サービスプロバイダーや利用者がパッケージやサービス事業者同士でメッセージ交換を行う際には、欧州の「電子請求書(eInvoicing)」の標準をもとにした日本版コアインボイスを使ったコアインボイスゲートウェイの利用をおすすめします。
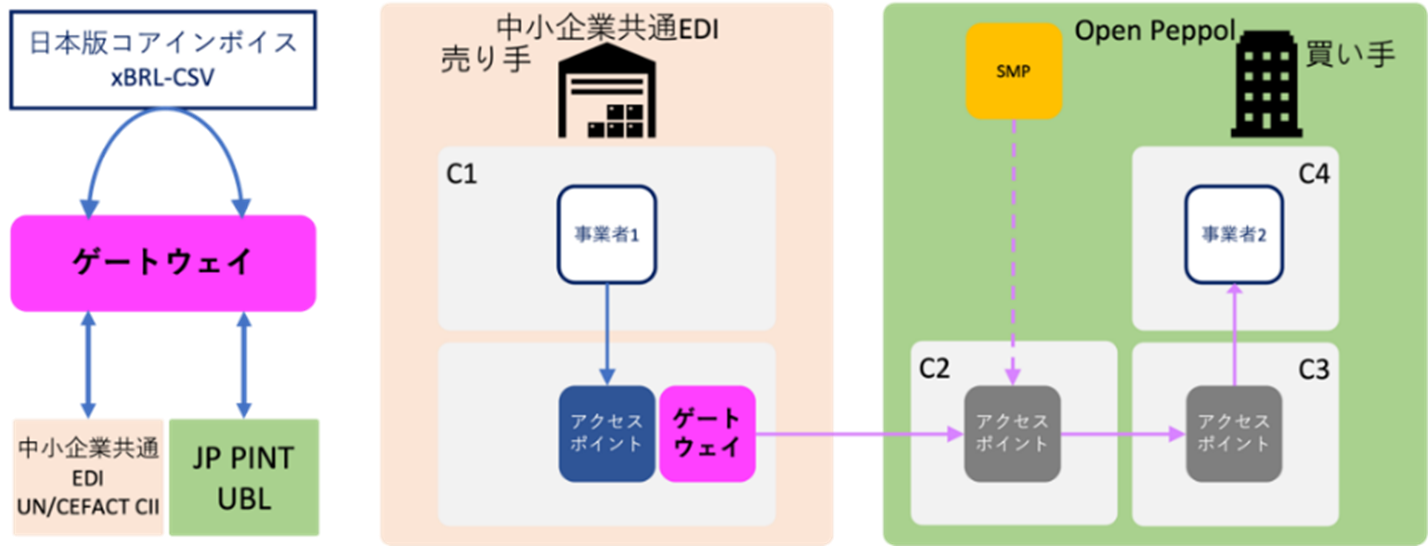
ユーザー向けのパッケージやサービス事業者には、業界別のEDIサービスを提供するサービスプロバイダーも含まれます。例えば、中小企業向けの共通EDIユーザー(C1/C4)は、日本版コアインボイスゲートウェイを使ってOpen Peppolのアクセスポイントに接続できます。ゲートウェイでは、日本版コアインボイスのセマンティックモデルに対応したxBRL-CSV(Tidy data)を標準データ形式として使い、中小企業共通EDI(UN/CEFACT CII 22B)とJP PINT v1(UBL 2.1)間のデータ変換が行われます。
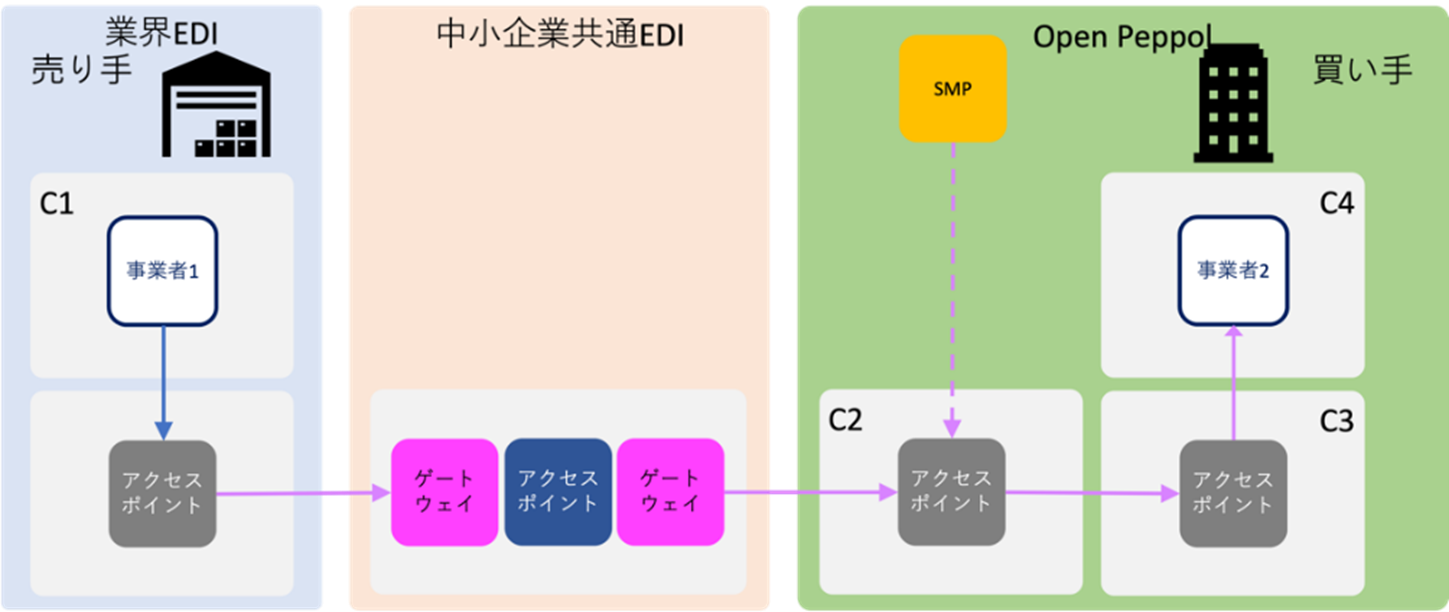
他の業界EDIのユーザーでも、Open PeppolのSMPに登録していれば、買い手は日本版コアインボイスゲートウェイを介してデジタルインボイスを送信できます。
ただし、買い手側の業務システムでは、接続先ごとにデータ処理インターフェースが必要になります。大手企業では、4コーナーのEDIアクセスポイントや3コーナーのEDIサービスに加え、個別に仕入先向けの調達ポータルを提供している場合もあります。しかし、これらの個別対応は、それぞれに対する個別対応が必要であり、その維持管理が大きな負担になることがあります。
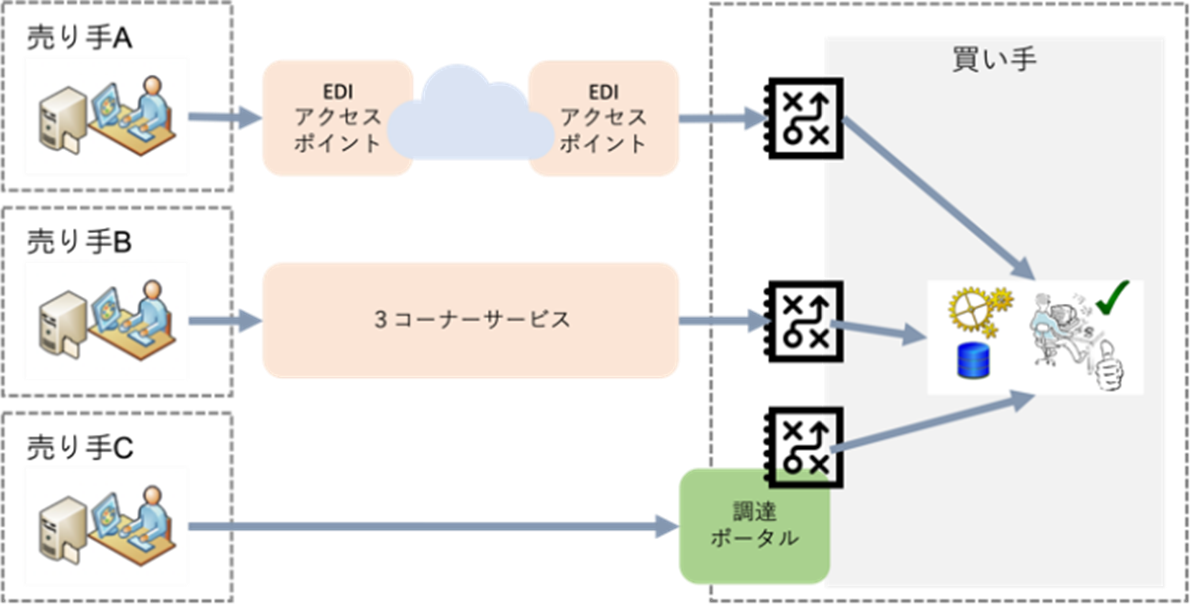
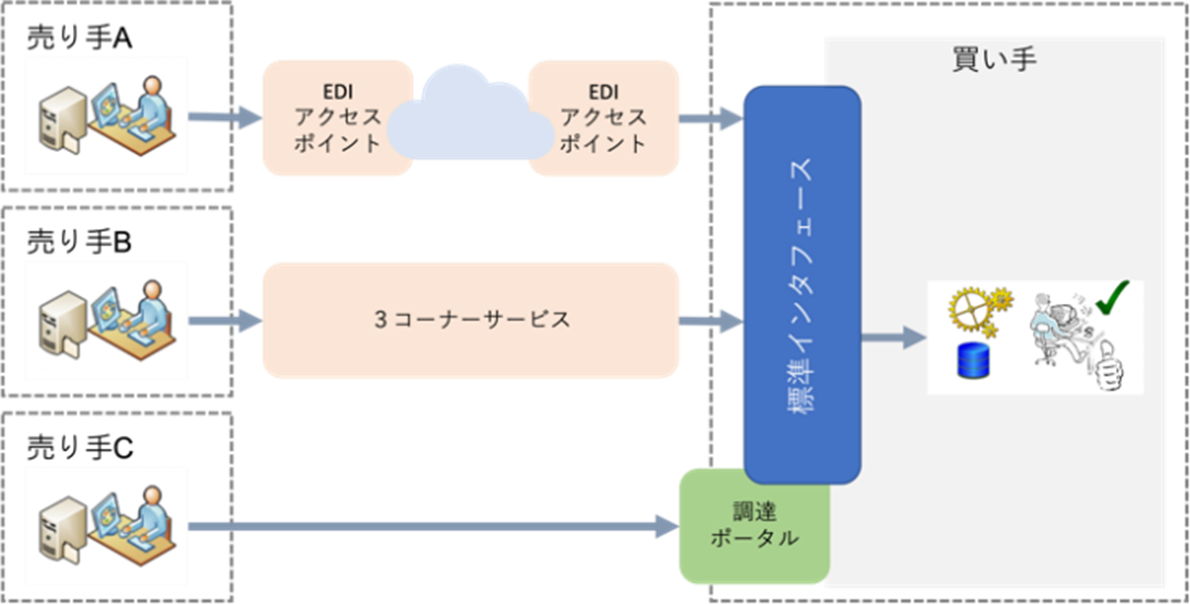
日本版コアインボイスゲートウェイで使用される標準データインタフェースは、社内システムを連携させるためのもので、アクセスポイントでの使用と同様、足し算の対応で組み合わせが可能になります。また、CSVファイルはxBRL-CSV形式であり、X B R Lタクソノミでその構造や意味を定義しているため、タクソノミの維持変更管理と連動することでシステムの維持管理を機械化できます。
6. セマンティックモデルとXBRL
入力データ形式と出力データ形式の間の変換プログラムを開発するには、入力データ形式がN種類、出力データ形式がM種類ある場合、N x M個のプログラムが必要になりますが、セマンティックレベルでの汎用インタフェースとしての論理階層モデルを定義することで、N + M個のプログラムで済ませることができます。そして、どれかが変更されても、影響を受けるのはその形式と汎用データ形式との変換プログラムだけです。
セマンティックモデルで定義された階層構造は論理的な定義ですから、どのXML構文を使用しているか(オープンペポルのJP PINTか、中小企業共通EDIのUN/CEFACT CIIか、あるいは業界で広く使われているEDI構文なのか)に依存しません。また、会計ソフトや業務ソフトが内部でどのようなデータベースの表を組み合わせて構成しているかにも依存しません。個別の構文同士の対応表ではなく、セマンティックモデルの階層構造定義を中心として、それぞれの構文へのバインディングを定義することで、対応先が増えた場合にも、追加した構文定義とセマンティックモデルの対応付けをXPathで指定するだけで済みます。
セマンティックモデルをそのままデータ交換の中間フォーマットとして使用するには、セマンティックモデルをそのまま物理ファイルに対応づける標準仕様が必要です。そのため、日本版コアインボイスデータウェイではXBRLタクソノミを採用しました。
XBRL(eXtensible Business Reporting Language)は、20世紀末にアメリカの会計士の発想に基づいてAICPA(アメリカ公認会計士協会)での実証検証をへて制定されました。他のXMLデータ標準では困難であった多様な観点が交差したセマンティックな定義をXBRLタクソノミを使用することで、異なる業界のEDI構文や会計ソフトウェアのデータベース構成など、さまざまなデータ形式間の変換プログラムの数を減らすことができます。また、中間フォーマットとしてのxBRL-CSVは、表形式のデータを扱いやすく、処理効率も高いため、データ変換における負担を軽減することができます。
さらに、XBRLタクソノミは、多次元のデータ構造を定義することができるため、様々なデータを柔軟に扱うことができます。この柔軟性は、ビジネスにおいて必要とされる多様なデータ要件に対応することができ、EDIを含むビジネスデータ交換においても、その有用性が高く評価されています。
日本版コアインボイスデータウェイでは、このようなセマンティックモデルを活用し、業界の枠を超えたEDIやデジタルインボイスの実現を目指しています。
セマンティックな階層データをCSVとして扱う整然データ Tidy Data について興味のある方は、次のカテゴリーの記事をご確認ください。
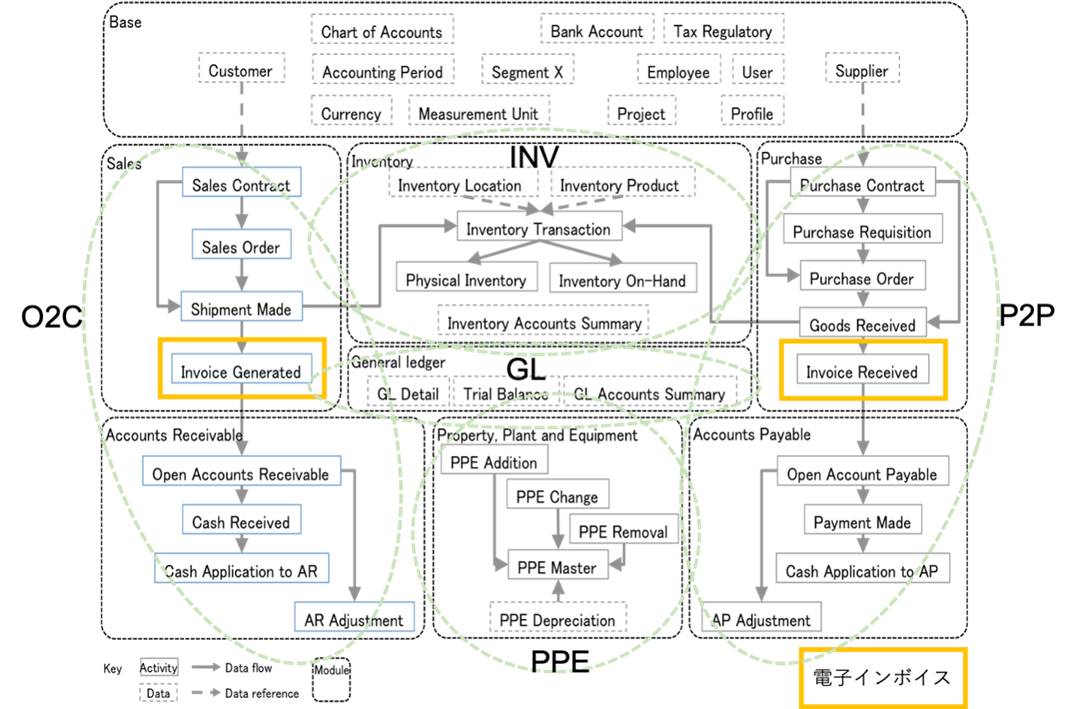
7. デジタルインボイスを契機とする会計のデジタル化
デジタルインボイスは、会計のデジタル化に大きな役割を果たしています。国際標準化機構(ISO)のTC 295 Audit data servicesでは、監査対象データの中でも重要な請求書をはじめとして各種の帳簿データや商取引文書を対象として、これらのデータを標準化することを目指しています。そのため、ISO TC 295 Audit data servicesで私がConvenerを務めているStudy group 1 (semantic model)では、これらの会計監査対象データをセマンティックモデルとして定義することで、異なる業界や国の会計データを共通のデータ形式で表現することを目指しています。
このような標準データに基づく会計データ標準インタフェースを、xBRL-CSV(Tidy data)を用いた標準APIで提供し、XBRLタクソノミで管理することで、会計のデジタル化が実現されます。そして、デジタルインボイスはその一環として、会計データの標準化に向けた重要なステップの一つとなっています。
8. 中小企業にとって、コアインボイスゲートウェイと構文バインディングとは
中小企業にとって、コアインボイスゲートウェイと構文バインディングは、請求書の作成や取引先とのやりとりを効率的に行うために重要なツールです。コアインボイスゲートウェイは、異なるフォーマットの請求書を統一的に処理することができ、請求書の標準化を促進します。また、構文バインディングは、自動的にデータを抽出して正確な情報を含む請求書を作成することができ、請求書作成の手間やミスを減らし、業務の効率化を図ることができます。
さらに、企業の会計データを標準化し、共通のCSVインタフェースで参照可能にすることで、取引先とのビジネス関係を改善することができます。共通のインタフェースを用いることで、データのやり取りがスムーズに行われ、取引先とのコミュニケーションも円滑になります。また、会計データの標準化により、会計処理の効率化や精度向上が期待できます。
中小企業の経営にとって、これらの取り組みは大きなメリットがあります。効率的な業務処理やビジネス関係の改善により、企業の業績向上が期待できます。また、税理士は、会計データの標準化や共通インタフェースの導入に関するアドバイスや支援を提供することで、企業の経営に貢献することができます。税務申告や決算書作成などの業務に加えて、企業の業務プロセスの改善にも取り組むことで、より総合的なサポートを提供することができます。
9. 会計情報の共通化とCSVインタフェースの標準化
正確な情報の提供や時間・コストの節約、経営上の正確な決定、税務申告の効率化、実務の効率化、新規ビジネスチャンスの創出など、標準化された会計情報に基づくCSVインタフェースの導入には、多くのメリットがあります。中小企業は、これらのメリットを十分に享受することができるため、コアインボイスゲートウェイと構文バインディングの導入を検討することが重要です。また、税理士や会計士は、このような標準化された会計情報に基づくCSVインタフェースの導入により、より高度な業務に取り組むことができます。企業の経営プロセスの改善やビジネスチャンスの創出に貢献することで、企業の発展につながることが期待されます。
例えば、取引先との関係改善についてです。企業が共通のCSVインタフェースを使用することで、取引先に正確な情報を提供できるため、誤解や不満を回避することができます。具体的には、請求書に関する情報が正確に記載され、誤解がないようになります。また、CSVインタフェースは標準的な形式であるため、取引先に簡単に共有することができ、時間とコストを節約することができます。
次に、実務の効率化についてです。CSVインタフェースを使用することで、会計情報の取り扱いに関する煩雑な作業を自動化することができます。例えば、請求書から必要な情報を自動的に抽出し、データベースに格納することができます。このような自動化により、会計士や税理士はより高度な業務に集中することができ、企業は効率的に業務を進めることができます。
さらに、新規ビジネスチャンスの創出についても、CSVインタフェースは役立ちます。例えば、ビジネスプロセスを自動化することにより、従来よりも多くの情報を取り扱うことができるようになります。これにより、新たなビジネスチャンスを見つけ出すことができます。また、CSVインタフェースは標準的な形式であるため、他の企業や業界とのデータの共有が容易になります。これにより、新たなビジネスチャンスを見つけ出すことができる可能性が高まります。
以上のように、共通のCSVインタフェースを使用することで、企業には多くのメリットがあります。
中小企業がEDIネットワークに参加することは、コストや技術的なハードルなどの問題があり、採用には障壁があります。しかし、デジタルインボイスの利点を享受するためには、EDIネットワークに参加する必要はありません。例えば、XBRLには、Inline XBRLという表現形式があり、EDINETの有価証券報告書でも採用されています。このInline XBRLを埋め込んだPDFの請求書をメールに添付することで、中小企業でもデジタルインボイスのメリットを享受することができます。
デジタルインボイスの採用は、中小企業の業務効率化やコスト削減に貢献するだけでなく、取引先との信頼関係の強化にもつながります。より身近な形式の採用により、中小企業もデジタルインボイスのメリットを享受できるようになることで、ビジネスの発展が促進されます。
次の文章は政府主導で中小企業のデジタル化を促進しようとする北欧の事例です、日本でもこうした取り組みが必要という提言に整理してください。
参考: 先行事例 北欧スマート政府&ビジネス
Nordic Smart Government & Business [1]では、中小企業向けにOpen Accountingサービス提供を計画しています。
北欧の先進事例であるOpen Accountingは、中小企業が自ら選んだ第三者とデジタルビジネス文書からデータを共有するための安全な方法を提供します。これは、標準化されたコンテンツと相互運用可能なAPIを介して行われます。APIは、デジタルシステム間でデータを共有するためのインタフェースであり、相互運用性は異なるシステム間の通信を可能にすることを意味します。
たとえば、スマートな倉庫管理アプリは、どのビジネスシステムにも接続して、最新の取引データを読み取り、製品の現在の在庫を計算してチェックできます。また、中小企業は、クレジット評価プロセス中に銀行とビジネスシステムを接続し、銀行のシステムに直接読み取り専用アクセスを許可することもできます。これにより、中小企業は、データを輸出して表を作成し、更新する手間を省き、最新の状況を把握することができます。
Open Accountingの目的は、中小企業の利益のために、革新的なソリューションやサービスの競争市場を作ることです。標準化は開発コストを削減し、新しいサービスが他のシステムやサービスと連携して使用できるようにします。従来の非標準的なデータ共有の方法では、ビジネスシステムに接続する場合に新しいサービスやアプリケーションを事実上ゼロから構築する必要がありました。将来的に提供される標準APIによって提供される相互運用性により、このコストが大幅に削減され、中小企業はデータを活用するサービスのより広い選択肢にアクセスすることができます。Open Accountingは、過去のデータを別のシステムに移行できる移植性を提供し、競争市場にとって必要不可欠なサービスプロバイダを変更できるようにします。
北欧では、スマート政府とビジネスが共同で事業者の財務取引データを第三者に提供するためのシステムが導入されています。これにより、中小企業はデータを所有する事業者の同意のもと、第三者にアクセスすることができます。また、会計データの標準化によって、データは規格化され、調和された定義によって構造化される必要があります。現在、SAF-TやXBRL-GLなどの複数のファイル形式が存在し、監査の目的やシステム間のデータ移行などに有用です。このデータの共有には、事業システムベンダーや銀行などの第三者のビジネスモデルを尊重する妥協点を見つけるため、私的・公的なアクターが自主的な方法を好む場合があります。必要に応じて、相互運用性と移植性が規制されることもあります。
データの共有には、プライバシーや営業秘密の規制を遵守し、GDPR(一般データ保護規則)に違反しないようにする必要があります。GDPRは、機密保持と個人情報の保護を求めるものであり、ビジネスデータの非常に限られたセットにしか影響しません。ただし、機密情報は常に保護される必要があります。ここで説明されているデータ共有は、ビジネスシステム内の会計情報をアクセスして読むための標準的な方法に限定されます。ただし、会計情報を作成したり更新したりすることはできません。
北欧の事例から見ると、政府主導で中小企業のデジタル化を促進することが重要であることがわかります。Open Accountingサービスは、中小企業が自由に選んだ第三者とデジタルビジネス文書からデータを共有するための安全な方法を提供し、標準化されたコンテンツと相互運用可能なAPIを介して行われます。このような標準化によって、新しいサービスが他のシステムやサービスと連携して使用できるようになり、中小企業はデータを活用するサービスのより広い選択肢にアクセスすることができます。また、会計データの標準化により、データは規格化され、調和された定義によって構造化される必要があります。このようなデータ共有には、プライバシーや営業秘密の規制を遵守する必要があります。北欧の事例から、政府やビジネスが共同でデジタル化を推進することが必要であり、日本でも同様の取り組みが必要であると言えます。
