
Views: 5
ISO/TC295/SG1 Semantic modelでのZoom会議の記録音声から話者別に文字起しを実行した。
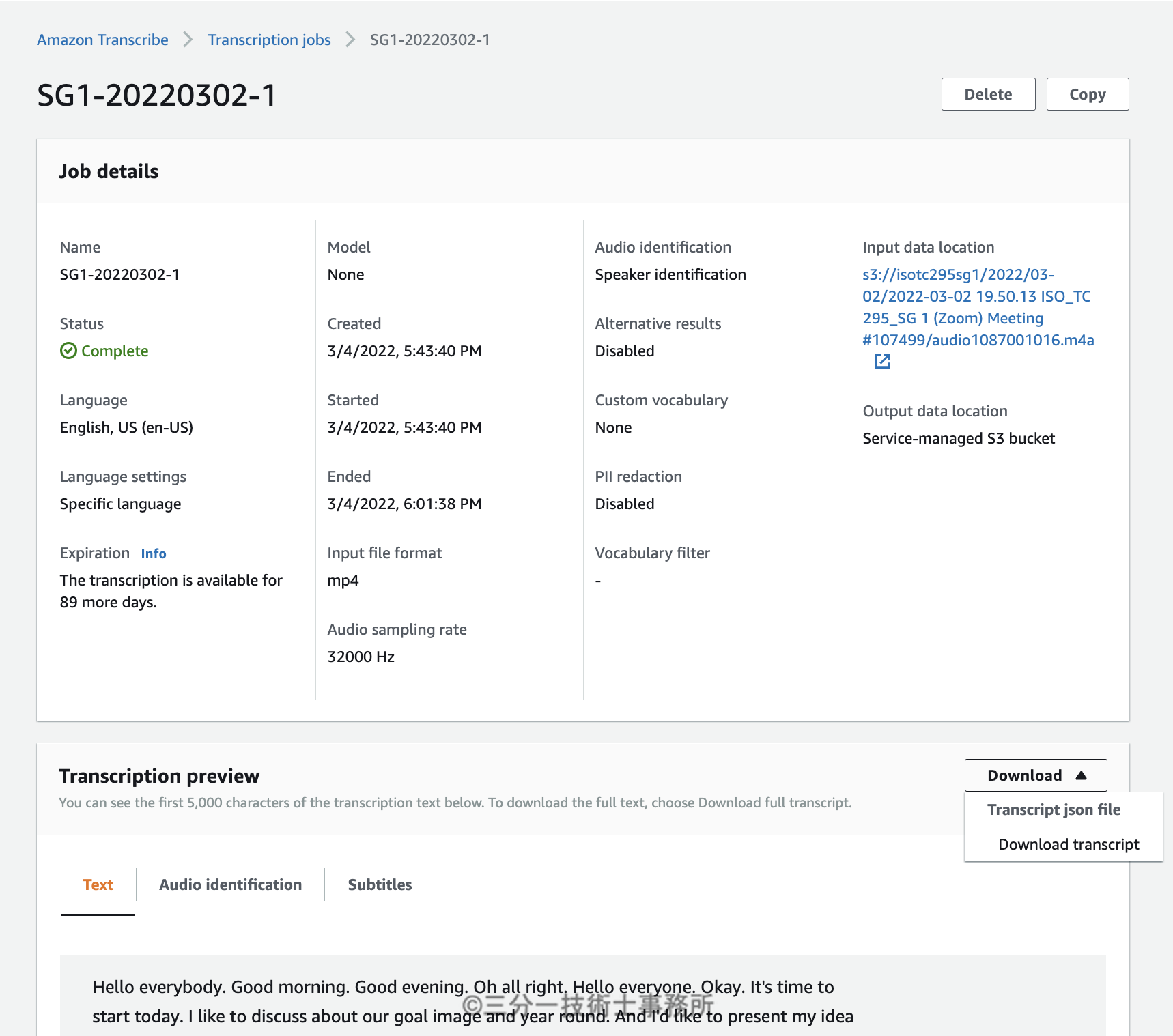
Transcribeの指定
ジョブ名他を指定
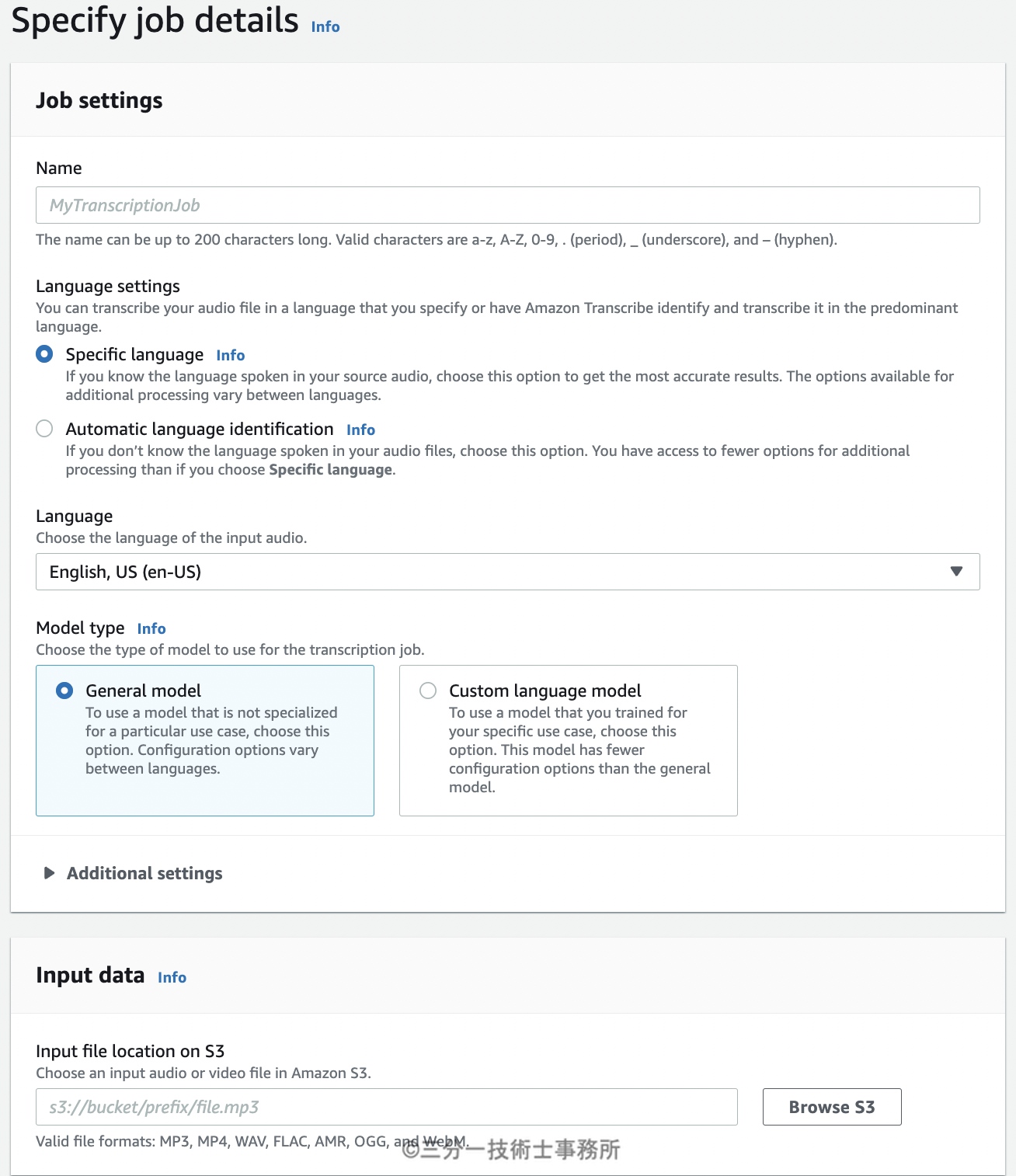
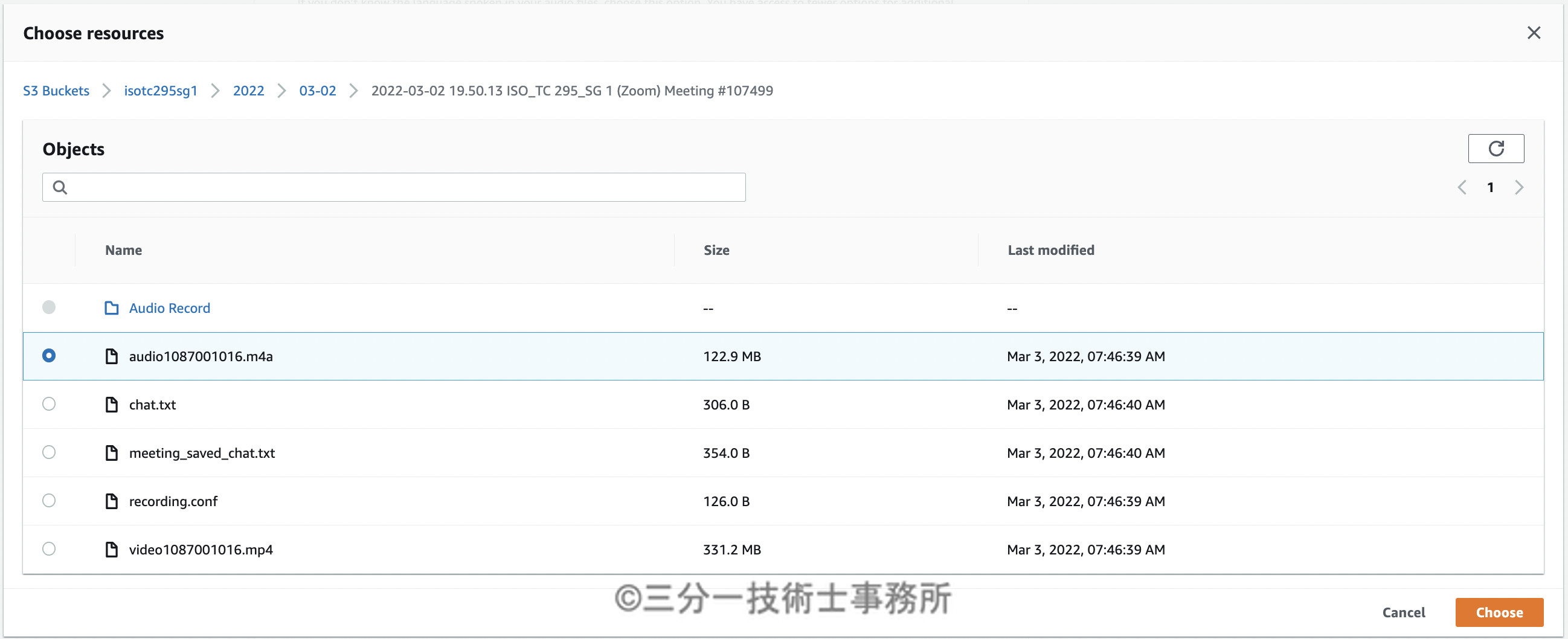
S3の音声ファイルを指定
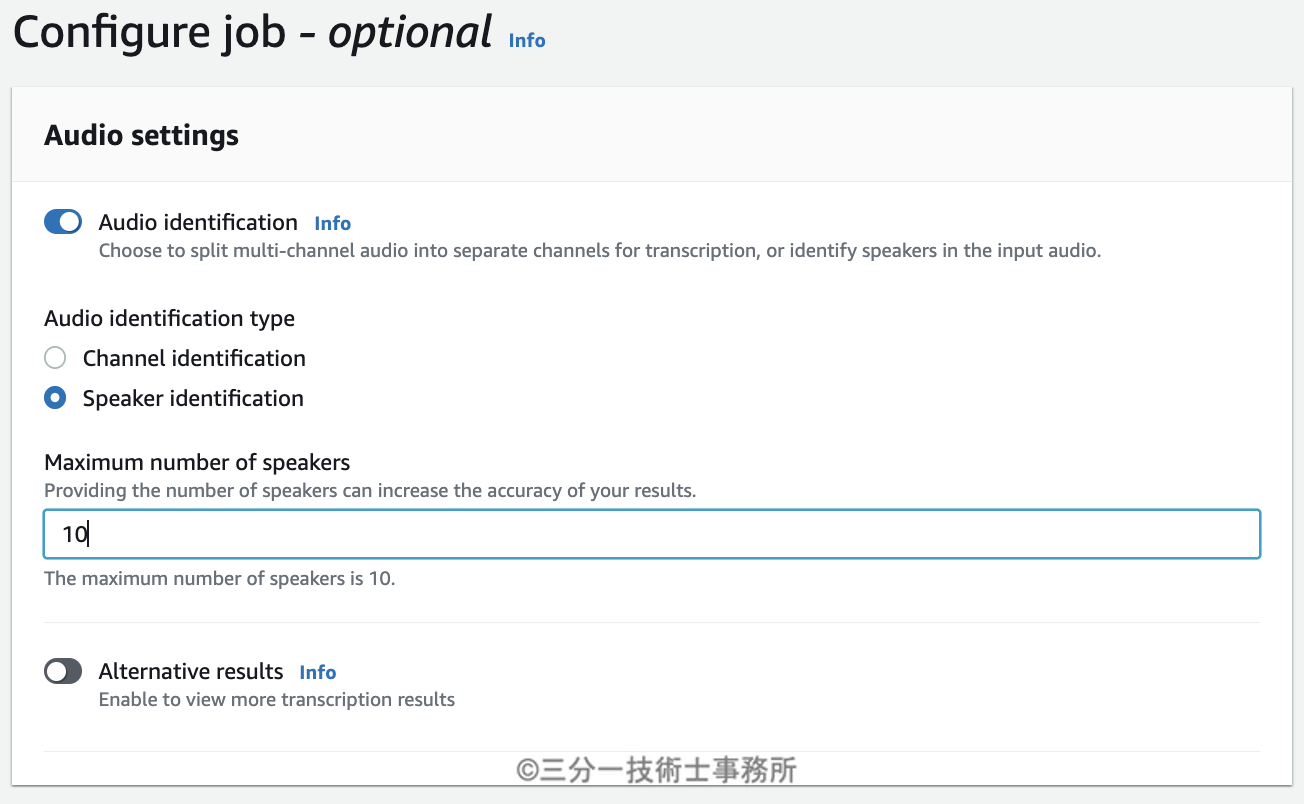
話者別に識別するように指定
文字起こしデータをjsonファイルとしてダウンロード
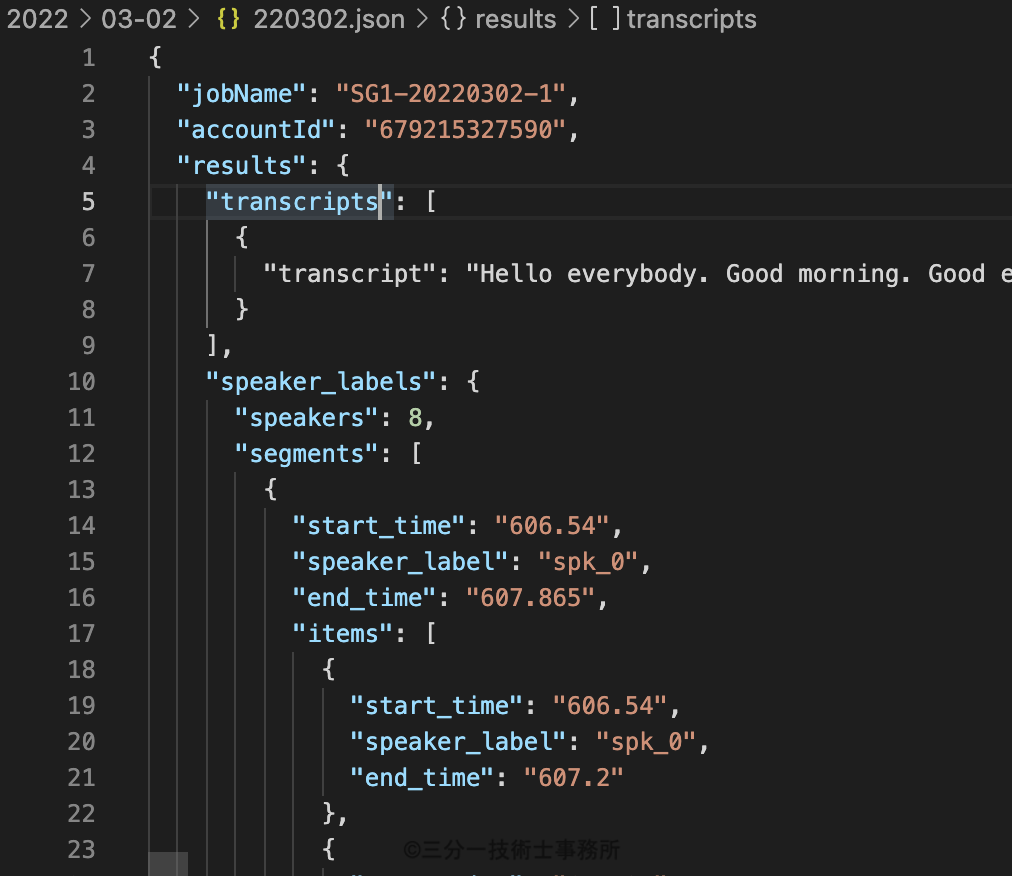
確かに英文としてデータが生成され、話者別に開始・終了時間等が出力されているもののこのままでは使いづらい。
AWS Forum調査
色々調べるとAWS Forumにそれらしい回答があった。
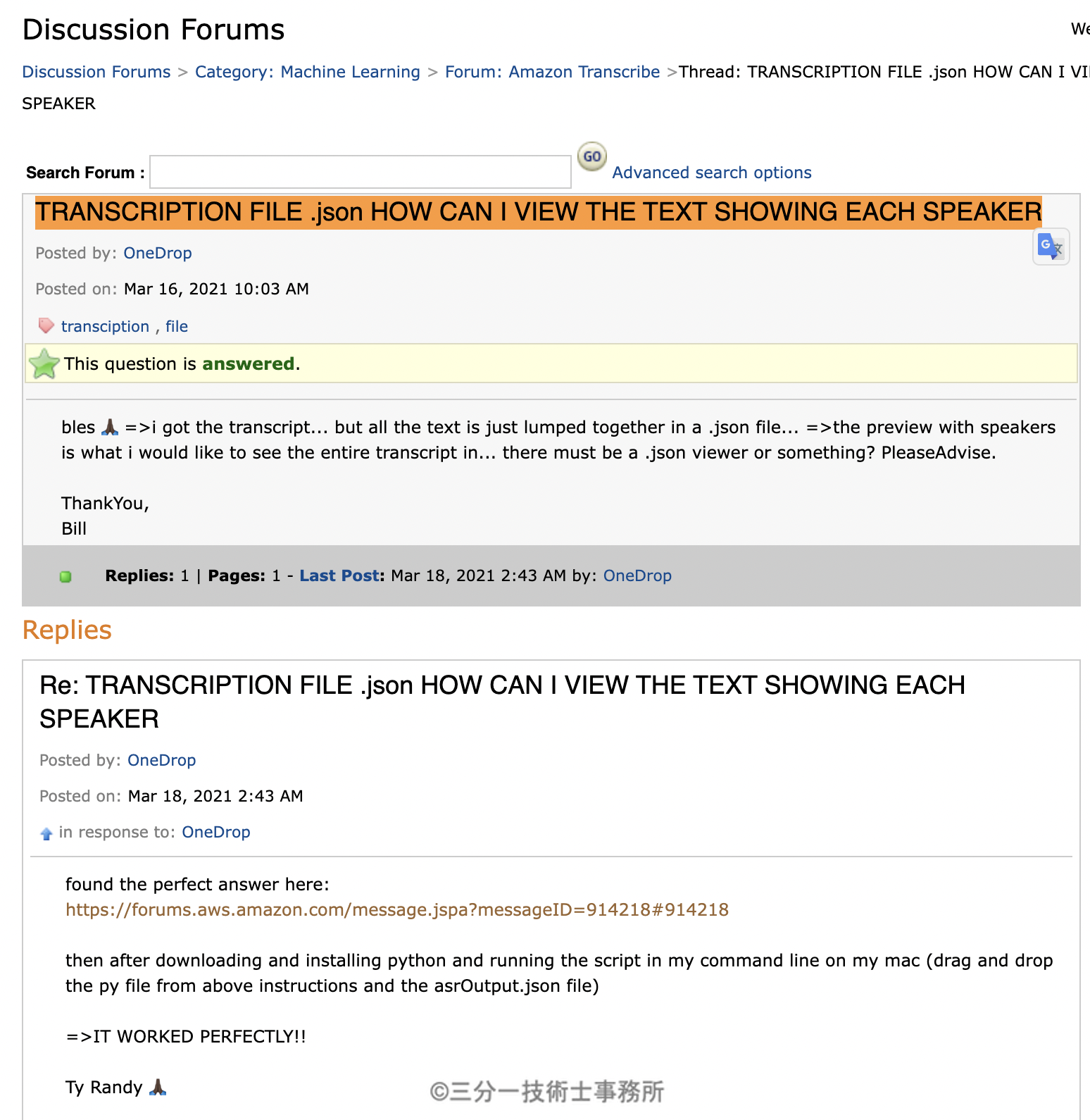
TRANSCRIPTION FILE .json HOW CAN I VIEW THE TEXT SHOWING EACH SPEAKER
found the perfect answer here:
https://forums.aws.amazon.com/message.jspa?messageID=914218#914218
transcript.py実行
transcript.py 2022/03-02/220302.json
実行結果
[0:10:07] spk_0: Hello everybody.
[0:10:09] spk_1: Good morning. Good evening. Oh
[0:10:13] spk_0: all right. Hello everyone.
[0:10:18] spk_1: Okay. It’s time to start today.
