
Visits: 25
Streamlining UML Diagram Automation for ISO 21378 Audit Data Collection: Integrating Python and PlantUML with CSV
Nobuyuki SAMBUICHI
ISO/TC295 Audit data services
Convener at SG1 Semantic model
Co-project Leader at AWI 21926 Semantic data model for audit data services
1. Introduction
In today’s digital world, visual representation of data models is crucial. This blog explains how to automate UML (Unified Modeling Language) diagrams creation from CSV (Comma Separated Values) files using Python and PlantUML.
2. Objective
Our primary goal is to transform class information stored in CSV files into structured UML diagrams, useful for software developers and system architects.
3. Tool and Environment Setup
To begin, ensure you have Python installed. Then, set up PlantUML:
-
Download PlantUML: Go to PlantUML official website and download
plantuml.jar. -
Install Java: PlantUML requires Java. Download and install the Java Runtime Environment (JRE).
-
Verify PlantUML Setup: Run
java -jar path/to/plantuml.jar -versionin your terminal. Replacepath/to/plantuml.jarwith your PlantUML jar file path.
4. Building the Python Script and Its Functions
The Python script is designed to automate the UML diagram creation process by performing several key functions:
-
Path Conversion: Converts relative paths to absolute paths for reliable file access.
-
Reading Target Classes: Reads specific class names from
target_classes_fileto selectively generate UML diagrams based on user-defined criteria. -
Parsing CSV Data: Extracts essential class properties and relationships from
object_class. -
Generating PlantUML Code: Transforms extracted data into PlantUML syntax, setting the stage for diagram generation.
-
Exporting to UML Diagram: Writes the PlantUML code to a file and employs PlantUML to convert this code into a visual UML diagram.
This script, by processing only relevant data from mim.csv and target_classes_file, efficiently creates focused and accurate UML diagrams, enhancing the understanding and representation of complex semantic models.
5. Understanding the CSV Input Format
5.1. object_class
The object_class file, used as input, is a Refined Message Information Model (R-MIM) for HL7 graphwalk, aimed at producing Hierarchical Message Definition (HMD). The file contains the following columns:
-
ID: A unique identifier for each entry.
-
Type: The type of the entry, such as attribute, association, etc.
-
Level: The hierarchical level of the entry in the model.
-
Multiplicity: Defines the multiplicity of the relationship.
-
ClassName: The name of the class.
-
AttributeName: The name of the attribute.
-
Datatype: The datatype of the attribute.
-
AssociatedClass: Any class that is associated with the current entry.
-
Description: A brief description of the entry.
It’s important to note that the Python script utilizes only a subset of these columns – specifically ClassName, AttributeName, Type, Datatype, and AssociatedClass, to construct the UML diagrams.
Ensure the CSV file follows this format for the script to parse and generate UML diagrams correctly.
The Python script specifically processes the following columns from object_class file:
-
ClassName: Utilized to identify and create UML classes.
-
AttributeName: Used to define attributes within each UML class.
-
Type: Indicates the nature of the entry, whether it’s an attribute or a type of relationship (like association or aggregation).
-
Datatype: Specifies the data type of attributes in the UML class.
-
AssociatedClass: Important for defining relationships between classes, especially in cases of associations, aggregations, and compositions.
These columns are essential for accurately mapping the R-MIM data into a structured UML diagram, capturing the necessary details for each class and their inter-relationships.
5.2. target_classes_file
The object_class file, integral to this semantic model, encompasses a range of classes related to the Refined Message Information Model (R-MIM) for HL7. To selectively generate UML class diagrams, the target_classes_file is utilized. This file contains a list of class names, with each class name written on a separate row. The Python script reads this file to filter and process only the specified classes from mim.csv, enabling focused and relevant UML diagram generation based on the user’s requirements.
6. Usage
Prepare your CSV with class information, then run the Python script to generate the UML diagram.
7. Conclusion
This automation simplifies creating UML diagrams from CSV files, showcasing the synergy between Python’s simplicity and PlantUML’s efficiency.
8. UML Class Diagrams for ISO 21378:2019 Audit data collection
8.1. Sales module
To enlarge, right-click and select “Open image in new tab.”

8.2. Accounts Receivable module
To enlarge, right-click and select “Open image in new tab.”

8.3. Purchase module
To enlarge, right-click and select “Open image in new tab.”

8.4. Accounts Payable module
To enlarge, right-click and select “Open image in new tab.”

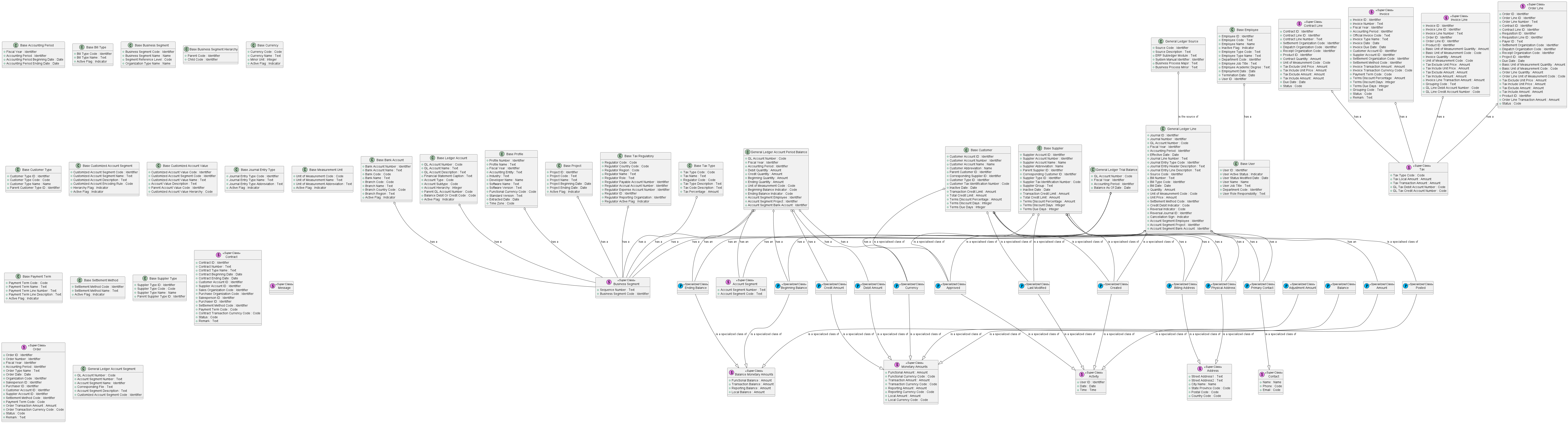
8.5. General Ledger module
To enlarge, right-click and select “Open image in new tab.”
8.6. Inventory module
To enlarge, right-click and select “Open image in new tab.”

8.7. PPE module
To enlarge, right-click and select “Open image in new tab.”

9. Source Code
#!/usr/bin/env python3
# coding: utf-8
#
# automate UML (Unified Modeling Language) diagrams creation from CSV
# (Comma Separated Values) files using Python and PlantUM
#
# designed by SAMBUICHI, Nobuyuki (Sambuichi Professional Engineers Office)
# written by SAMBUICHI, Nobuyuki (Sambuichi Professional Engineers Office)
#
# MIT License
#
# (c) 2023 SAMBUICHI Nobuyuki (Sambuichi Professional Engineers Office)
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
import csv
import os
import subprocess
import re
SEP = os.sep # Define the system-specific path separator
# Function to convert a given path to an absolute path
def file_path(pathname):
if SEP == pathname[0:1]:
return pathname
else:
pathname = pathname.replace('/', SEP)
dir = os.path.dirname(__file__)
new_path = os.path.join(dir, pathname)
return new_path
# Function to load target class names from a file
def load_target_classes(file_path):
with open(file_path, 'r', encoding='utf-8-sig') as file:
return [line.strip() for line in file if line.strip()]
# Function to parse a CSV file and generate UML code
def parse_csv_to_uml(plantuml_path, source, object_class, uml_file_path, target_modules):
classes = {}
relationships = []
object_class = file_path(f"{source}{object_class}")
uml_file_path = file_path(f"{source}{uml_file_path}")
with open(object_class, 'r', encoding='utf-8-sig') as file:
reader = csv.reader(file)
next(reader) # Skip the header row
target_class = []
for row in reader:
# Skip empty rows
if not row or not any(row):
continue
# Extract and strip values from the row
id, prop_type, level, multiplicity, class_name, prop_name, data_type, assoc_class, description = [x.strip() for x in row]
pattern = r'([A-Z]+)[0-9]+'
match = re.search(pattern, id)
module = None
if match:
module = match.group(1)
if module in target_modules:
if class_name and class_name not in target_class:
target_class.append(class_name)
if assoc_class and assoc_class not in target_class:
target_class.append(assoc_class)
with open(object_class, 'r', encoding='utf-8-sig') as file:
reader = csv.reader(file)
next(reader) # Skip the header row
for row in reader:
# Skip empty rows
if not row or not any(row):
continue
# Extract and strip values from the row
id, prop_type, level, multiplicity, class_name, prop_name, data_type, assoc_class, description = [x.strip() for x in row]
if class_name in target_class:
if class_name and class_name not in classes:
classes[class_name] = {"attributes": []}
elif assoc_class and assoc_class not in classes:
classes[assoc_class] = {"attributes": []}
# Handle attributes and relationships
if 'Attribute' in prop_type:
# Additional handling for primary key attribute
if 'PK' in prop_type:
classes[class_name]["attributes"].append(f'+PK: {prop_name} : {data_type} ')
else:
classes[class_name]["attributes"].append(f'+{prop_name} : {data_type}')
elif prop_type in ['Association', 'Aggregation', 'Composition', 'Specialized Class']:
# Determine the relationship symbol based on the property type
if prop_type == 'Association':
relation_symbol = '--'
elif prop_type == 'Aggregation':
relation_symbol = 'o--'
elif prop_type == 'Composition':
relation_symbol = '*--'
elif prop_type == 'Specialized Class':
relation_symbol = '--|>'
relation = f'"{class_name}" {relation_symbol} "{assoc_class}" : {prop_name}'
relationships.append(relation)
uml_code = '@startuml\n'
# Build UML code for each class
for class_name, properties in classes.items():
if not class_name:
continue
uml_code += f'class "{class_name}" {{\n'
for attr in properties["attributes"]:
uml_code += f' {attr}\n'
uml_code += '}\n\n'
# Add relationships to UML code
for relation in relationships:
uml_code += relation + '\n'
uml_code += '@enduml'
# Write the resulting UML code to a text file
with open(uml_file_path, 'w') as f:
f.write(uml_code)
# Function to generate UML image using PlantUML
# def generate_uml_image(plantuml_path, uml_file_path):
subprocess.run(["java", "-DPLANTUML_LIMIT_SIZE=16384", "-jar", plantuml_path, uml_file_path])
# Main execution: Setting up paths and generating UML code and image
plantuml_path = file_path('UML/bin/plantuml-mit-1.2023.12.jar')
source = 'UML/'
object_class = 'source/mim.csv'
# Generate UML from CSV and then create the image
# Sales module
target_modules = ['SAL','GEN','BS']
uml_file_path = 'diagram/SAL_UML.txt'
parse_csv_to_uml(plantuml_path, source, object_class, uml_file_path, target_modules)
print(uml_file_path)
# Accounts Receivable module
target_modules = ['AR','GEN','BS']
uml_file_path = 'diagram/AR_UML.txt'
parse_csv_to_uml(plantuml_path, source, object_class, uml_file_path, target_modules)
print(uml_file_path)
# Purchase module
target_modules = ['PUR','GEN','BS']
uml_file_path = 'diagram/PUR_UML.txt'
parse_csv_to_uml(plantuml_path, source, object_class, uml_file_path, target_modules)
print(uml_file_path)
# Accounts Payable module
target_modules = ['AP','GEN','BS']
uml_file_path = 'diagram/AP_UML.txt'
parse_csv_to_uml(plantuml_path, source, object_class, uml_file_path, target_modules)
print(uml_file_path)
# General Ledger module
target_modules = ['GL','GEN','BS']
uml_file_path = 'diagram/GL_UML.txt'
parse_csv_to_uml(plantuml_path, source, object_class, uml_file_path, target_modules)
print(uml_file_path)
# Inventory module
target_modules = ['INV','GEN','BS']
uml_file_path = 'diagram/INV_UML.txt'
parse_csv_to_uml(plantuml_path, source, object_class, uml_file_path, target_modules)
print(uml_file_path)
# PPE module
target_modules = ['PPE','GEN','BS']
uml_file_path = 'diagram/PPE_UML.txt'
parse_csv_to_uml(plantuml_path, source, object_class, uml_file_path, target_modules)
print(uml_file_path)
